







基础篇
1.正则中的 开始和结束限制符号
var reg = /^this/; //只能匹配开始位置为this 的字符串。
var str = 'this is a test!';
var str1 = ' this is a test!';
console.log(reg.test(str));//true
console.log(reg.test(str1));//false
var reg = /this$/;//只能匹配结束位置为this的字符串。
var str3 = 'this is a test';//false
var str4 = 'this is a test this';//truevar reg = /^this$/;//这个值能匹配 this 字符串 其他都不匹配!
var str1 = 'this is a test';
var str2 = 'this';
console.log(reg.test(str1));//false
console.log(reg.test(str2));//true
reg =/this/;//这种情况 只要字符串中有this 就匹配成功
str1 = 'this is a test';//true
str2 = 'is a test';//false
console.log(reg.test(str1));//true
console.log(reg.test(str2));//false3 . ^不在开始位置而是在[]时意思是取反的意思 也就是不包含的意思,至于[]的讲解在后面会详细提到
var reg = /hello,[^w]/;
var str = 'hello,world';
console.log(reg.test(str));//false
var str1 ='hello,better';
console.log(reg.test(str1));//true2.元字符(这里详细的可以参考w3c中对每个元字符详细的描述)点击这里查看详情
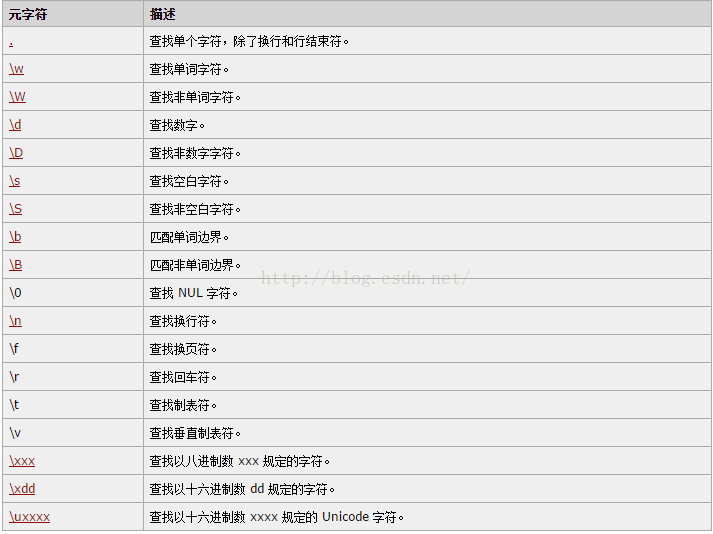
3.修饰符(这里按照我的理解称之为修饰符,意思就是对元字符起到修饰的作用)
| 修饰符 | 前面元字符出现的次数 |
| * | 0次或更多次 |
| + | 至少1次 |
| ? | 0次或者1次 |
| {n,m} | 最少n次,最大m次(n<=m) |
| {n} | n次 |
var reg = /hello,w*d/;//w出现个数可以为0个可以为多个
var str = 'hello,mm';
var str1 = 'hello,d';
var str2 = 'hello,wd';
var str3 = 'hello,wwwwwd';
console.log(reg.test(str));//false
console.log(reg.test(str1));//true
console.log(reg.test(str2));//true
console.log(reg.test(str3));//truevar reg = /hello,w+d/;
var str = 'hello,mm';
var str1 = 'hello,d';
var str2 = 'hello,wd';
var str3 = 'hello,wwwwwd';
console.log(reg.test(str));//false
console.log(reg.test(str1));//false
console.log(reg.test(str2));//true
console.log(reg.test(str3));//truevar reg = /hello,w?d/;
var str = 'hello,mm';
var str1 = 'hello,d';
var str2 = 'hello,wd';
var str3 = 'hello,wwwwwd';
console.log(reg.test(str));//false
console.log(reg.test(str1));//true
console.log(reg.test(str2));//true
console.log(reg.test(str3));//falsevar reg = /hello{2,5}d/; //匹配hello,o 出现的次数最少为2次,最多为5次 后面紧跟一个d
var str = 'sljfhellodsdf';
var str1 = 'sljfhelloodsdf'
var str2 = 'sljfhellooodsdf'
var str3 = 'sljfhelloooodsdf'
var str4 = 'sljfhellooooodsdf'
var str5 = 'sljfhelloooooodsdf'
console.log(reg.test(str));//false
console.log(reg.test(str1));//true
console.log(reg.test(str2));//true
console.log(reg.test(str3));//true
console.log(reg.test(str4));//true
console.log(reg.test(str5));//falsevar reg = /hello{2}d/; //匹配hello,o 出现的次数只能为2次 后面紧跟一个d
var str = 'sljfhellodsdf';
var str1 = 'sljfhelloodsdf'
var str2 = 'sljfhellooodsdf'
var str3 = 'sljfhelloooodsdf'
var str4 = 'sljfhellooooodsdf'
var str5 = 'sljfhelloooooodsdf'
console.log(reg.test(str));//false
console.log(reg.test(str1));//true
console.log(reg.test(str2));//false
console.log(reg.test(str3));//false
console.log(reg.test(str4));//false
console.log(reg.test(str5));//false4. [ ] 和 | 符号的详细说明
var reg = /hello,[a-z]+/;//匹配 hello, 后面是小写字母
var str = 'hello,world';
var str1 ='hello,World';
var str2 ='hello,better';
var str3 ='hello,Better';
console.log(reg.test(str));//true
console.log(reg.test(str1));//false
console.log(reg.test(str2));//true
console.log(reg.test(str3));//falsevar reg = /hello,[world|better]/;//匹配 hello, 后面紧跟 world 或者 better
var str = 'hello,world';
var str1 ='hello,meinv';
var str2 ='hello,better';
var str3 ='hello,Better';
console.log(reg.test(str));//true
console.log(reg.test(str1));//false
console.log(reg.test(str2));//true
console.log(reg.test(str3));//false进阶篇
(进阶篇会根据我遇到的情况慢慢进行补充和整理,本人整理不可能尽到所有的方方面面,毕竟本人脑力有限 哈哈)
1.分组
2.贪婪量词和惰性量词
var reg = /hello,w+?/;
var str = 'hello,wwwrold';
console.log(reg.exec(str));
3.RegExp对象的静态属性
| 静态属性 (简写形式) | 属性描述 |
| input ($_) | 最后匹配的字符,如果下次再匹配为空时 则 input的值还是上次匹配的字符串 |
| lastMatch ($&) | 最后匹配的分组 |
| leftContext(&`) | 返回被查找的字符串中从字符串开始位置到最后匹配之前的位置之间的字符 |
| rightContext($') | 返回被搜索的字符串中从最后一个匹配位置开始到字符串结尾之间的字符 |
| $1,$2……$9 | 这些属性是只读的。如果表达式模式中有括起来的子匹配,$1…$9属性值分别 是第1个到第9个子匹配所捕获到的内容。如果有超过9个以上的子匹配,$1…$9属 性分别对应最后的9个子匹配。 |
input
var reg = /[A-Z]/;
var str = 'Hello,wrold';
var ss = reg.test(str);
console.log(RegExp.input);//Hello,world;
var ss1 = reg.test('this is a test');
console.log(RegExp.input);//Hello,world 还是之前匹配到的 并没有改变 原因是 上次匹配到的为空,而input是最后一次匹配成功的字符串
console.log(RegExp['$_']);//Hello,world 简写模式
console.log(RegExp.$_);//Hello,world 简写模式lastMatch
var reg = /[a-z]/g;
var str = 'hello,world';
reg.test(str);
console.log(RegExp.lastMatch);//h
reg.test(str);
console.log(RegExp['$&']);//e 由于$&是不合法的变量名 所以 RegExp.$& 会报错
var reg = /[a-z](\d+)/g;
var str ="sdlj123sdkfksujs45kkkk67dff";
reg.test(str);
console.log(RegExp.lastParen);//123
reg.test(str);
console.log(RegExp['$+']);//45var reg = /[A-Z]+/g;
str = 'sdl123AAABBBdlj43s';
reg.test(str);
console.log(RegExp.leftContext);//sdl123
console.log(RegExp["$`"]);//sdl123 $后面的符号是esc按键下面的那个键盘符号
console.log(RegExp.rightContext);//dlj43s
console.log(RegExp["$'"]);//dlj43s 注意这里 双引号""不能换成单引号''要不然会报错$1...$9
var reg = /([a-z]+)(\d+)/g;
var str = 'sdfj123sldjfj34fkfkkfkf456kkl';
reg.test(str);
console.log(RegExp['$1']);//sdfj
console.log(RegExp['$2']);//123
reg.test(str);
console.log(RegExp['$1']);//sldjfj
console.log(RegExp['$2']);//34
reg.test(str);
console.log(RegExp['$1']);//fkfkkfkf
console.log(RegExp['$2']);//4564.RegExp对象的实例属性
var reg = /hello,[a-z]+/gi; //或者reg = RegExp('hello,[a-z]+','gi');
console.log(reg.global); //true
console.log(reg.ignoreCase); //true
console.log(reg.multiline); //false
console.log(reg.source);//hello,[a-z]+tip: global/ignoreCase/multiline属性都是可读写属性 也就是说 可以对实例化后的RegExp对象再次进行 这些属性设置。
5.RegExp对象的实例方法
字符串对象与 RegExp相关的函数
compile()
var reg = /is\d/g;
var str = 'myageis20,herageis22.';
console.log(reg.exec(str));//["is2", index: 5, input: "myageis20,herageis22."]
reg1 = /is/g;
reg.compile(reg1);
console.log(reg.exec(str));//["is", index: 5, input: "myageis20,herageis22."]test()
var reg = /[A-Z]+/g;
var str = 'this is a test!';
var str1 ='This is a test!';
console.log(reg.test(str));//false
console.log(reg.test(str1));//trueexec() 和 match()
他们都是检索字符串中指定的字符,并返回一个 数组对象,那么这个数组中都包含什么内容呢 咱慢慢来分析非全局匹配模式
应用的RegExp实例 没有设置全局属性 g
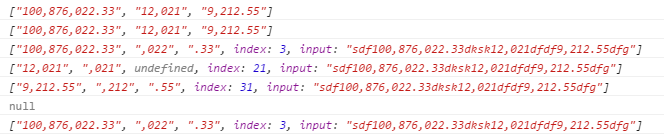
var reg = /[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?/;//匹配数字个位开始没3位一个逗号,可以有小数部分,如果有小数部分位数精确到百分位,看到这的相信都能看懂什么意思
var str = 'sdf100,876,022.33dksk12,021dfdf9,212.55dfg';
console.log(str.match(reg));
console.log(reg.exec(str));
console.log(reg.exec(str));
看到结果了么 都一样的结果 这也就是说
1. 无g也就是非全局模式 exec()方法和 match()方法输出的结果是相同,都是匹配到就退出 返回第一次匹配到的结果
2.输出数组中的
第一项 表示 整个字符串中第一次匹配到的结果
第二项 表示 第一个分组匹配到的结果 也就是子匹配
第三项 表示 第二个分组匹配到的结果 (说明 由于示例中的regexp只有2个分组也就是2对小括号,分组的排序是从左到有出现小括号的次序来排的,如果有更多个分组 ,那么下面的第四项,第五项 分别代表 第三个分组匹配的结果,第四个分组匹配的结果,但是最多只能匹配最后9次 上面已经提到过,这里 还回到例子中来(这句话是错误的 刚才测试了一下 最多应该是99个分组))
第四项 index 不陌生吧 就是匹配成功的第一个字符在整个串中的索引位置(默认0开始)
第五项 input 这个就是代表整个要匹配的字符串 相当于str
3.无论进行多少次匹配 都是返回第一次匹配成功的字符信息 也就是说 每次匹配 都是从字符串 索引为0的位置开始匹配 匹配成功就返回 不管后面 还有没有能够匹配的字符串
全局匹配模式
var reg = /[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?/g;
var str = 'sdf100,876,022.33dksk12,021dfdf9,212.55dfg';
console.log(str.match(reg));
console.log(str.match(reg));
console.log(reg.exec(str));
console.log(reg.exec(str));
console.log(reg.exec(str));
console.log(reg.exec(str));

明显 结果 不一样了 返回数组结构也不一样了 这两个函数 复杂就复杂到这个地方了 要根据是否全局模式匹配来变化。
下面进行一一说明
match:
全局模式下 返回数组中每一项为整个匹配字符串中所有能匹配成功的字符 再次调用 还是一样的结果
exec:
全局模式下 第一次调用 返回 第一次成功匹配的字符信息 数组中的每一项含义跟 非全局模式 一样 这里就不累赘的详细说明了
然后第二次调用 返回 第二次成功匹配的字符信息
同理 第三次调用 返回第三次成功匹配的字符信息
直到最后没有匹配的了 返回null;
这里说明一下 如果 返回null后 再次调用 会从字符串开始位置从新进行匹配 大家可以去动手试一下
这俩复杂的函数终于告一段落了 下面来看剩余的几个函数
replace()
顾名思义也就是字符串替换,但是很多童鞋只会简单的替换操作 ,次函数接收两个参数
第一个参数 要匹配的字符串 或者一个RegExp对象
第二个参数 要替换的字符串 或者一个函数 函数的返回值为要替换的字符串
先上简单的 咱们慢慢深入研究
1.两参数都为字符串
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace('20','30');
console.log(newStr);//myageis30,herageisalso20,youageis25.var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace('20','30');
newStr = newStr.replace('20','30');
console.log(newStr);//myageis30,herageisalso30,youageis25.2.第一个参数为一个RegExp对象,第二个参数为普通字符串
还是刚才例子 改写一下
var reg =/20/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,'30');
console.log(newStr);//myageis30,herageisalso30,youageis25.myageis30,herageisalso30,youageis30.
还有一种特殊情况: 第二个参数为字符串时 存在$,在这里 $具有不同的含义,具体下表
$1,$2.....$99 与RegExp中 第 1个 到第99个子表达式相匹配的文本。(如果RegExp中只有3个分组,那么 $4以后的 就会匹配不到 经测试 会当成 直接量输出)
$& 与RegExp整个相匹配的文本。
$` 位于匹配子字符左侧的文本
$' 位于匹配子字符串右侧的文本
$$ $直接量
$1,$2.....$99
var reg =/(m)(y)(a)(g)(e)(i)(s)(\d+)(y)(e)(a)(r)(s)(o)(l)(d)/g;
var str = 'myageis20yearsold,herageisalso20yearsold,myageis25yearsold.';
var newStr = str.replace(reg,'$2'+'+');//$2代表第二个子表达式匹配的结果 即 y;
console.log(newStr);//y+,herageisalso20yearsold,y+.
var newStr1 = str.replace(reg,'$16'+'--');//这里reg对象有16个分组,即16个子表达式,$16 ---->d;
console.log(newStr1);//d--,herageisalso20yearsold,d--.
var newStr2 = str.replace(reg,'$17'+'####');//$17本应该代表第17个子表达式匹配的结果,但是reg没有第17个子表达式 这里就会按照直接量替换输出
console.log(newStr2);//m7####,herageisalso20yearsold,m7####. //结果居然不是直接量 而是m7 什么鬼? 仔细一看 原来$17 被当成了$1 7 来玩的
//咱们拿一个分组少的玩,多的容易玩坏
var reg1 = /is(\d+)/g; //就1个分组
var str1 = 'myageis20,herageisalso20,youageis25.';
console.log(str1.replace(reg1,'$1'+'####'));//myage20####,herageisalso20,youage25####.
console.log(str1.replace(reg1,'$2'+'@@@'));//yage$2@@@,herageisalso20,youage$2@@@. 这里的$2就当成直接量输出了$&
var reg = /is(\d+)/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,'$&'+'#####');
console.log(newStr);//myageis20#####,herageisalso20,youageis25#####.$`和$'
var reg = /is(\d+)/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,'$`'+'#####');
console.log(newStr);//myagemyage#####,herageisalso20,youagemyageis20,herageisalso20,youage#####.
var newStr2 = str.replace(reg,"$'"+'@@@@');//注意 这里只能用双引号,否则会报错
console.log(newStr2);//myagemyage#####,herageisalso20,youagemyageis20,herageisalso20,youage#####.var reg = /is(\d+)/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,'$$'+'#####');
console.log(newStr);//myage$#####,herageisalso20,youage$#####.下面来说第三种情况
3.第一个参数为一个字符串,第二个参数为函数
还是刚才的例子 咱们改写一下
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace('20',function(succStr,index,input){
console.log(succStr);//20
console.log(index);//7
console.log(input);//myageis20,herageisalso20,youageis25.
return succStr+'yearsold';
});
console.log(newStr);//myageis20yearsold,herageisalso20,youageis25.例子上面 replace第二个参数为函数时 接收3个参数
第一个参数 是匹配成功的字符串
第二个参数 是匹配成功字符串第一个字符在整个串种的索引(默认0开始)
第三个参数 就是被匹配的整个字符串
我们能够拿到匹配到的字符串 下面可以任意蹂躏他了 想怎么玩都可以 一切随你所愿 你懂的 哈哈!
前面已经讲过 函数 return 的内容 就是 要替换的字符 可以根据自己的实际情况来玩 是不是很爽的赶脚! 本例子相对简单 就是为了让大家能看懂,有的人想了 我要替换所有的数字呢 很显然 第一个参数可以用上面提到过的 RegExp对象设置全局模式来匹配
4.第一个参数为RegExp对象,第二个为函数
var reg = /\d+/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,function(succStr,index,input){
console.log(succStr);
console.log(index);
console.log(input);
return succStr+'yearsold';
});
console.log(newStr);
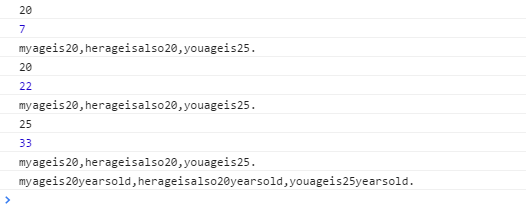
卧槽 输出那么多 我只log了4次呀,这里说明一下 全局匹配模式 每成功匹配一次 都会调用一下函数 每次执行的 参数 分别对应为本次成功匹配字符,本次成功匹配字符首字符在整个串种的索引,第三个 都一样 都是被替换的整个原始字符串
对于第4中参数情况 还有一个复杂的问题
就是 RegExp对象存在分组的情况
var reg = /is(\d+)/g;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = str.replace(reg,function(succStr,substr1,index,input){
console.log(succStr);
console.log(substr1);
console.log(index);
console.log(input);
});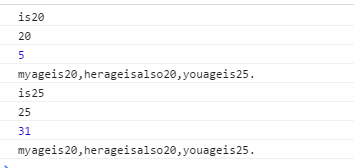
这里replace的第二个参数 (函数) ,次函数有4个参数 分别表示
succStr 匹配的整个字符串
substr1 分组1匹配的字符串 这里说明一下 如果 RegExp对象中有多个分组,那么 函数的参数从第二个开始 一次表示reg中第一个分组匹配的字符串,第二个分组匹配的字符串......
index 匹配成功字符串在整个字符串中的索引
input 被匹配的整个字符串
一时没把握住 replace说了这么多 下面来看另外一个
split()
这个函数 就是对字符串进行分割,返回值为一个数组类型,可以接受2个参数 第一个参数(必选) 类型:String /RegExp,表示要以什么为分隔点分隔字符串,第二个参数(可选) 类型:Number 表示 限制返回的数组最大长度,如果没有限制 则返回整个分隔的内容String时:
var str = 'myageis20,herageisalso20,youageis25.';
var arr = str.split(',');
console.log(arr);//["myageis20", "herageisalso20", "youageis25."]
var arr1 = str.split(',',2);
console.log(arr1);//["myageis20", "herageisalso20"]
var arr2 = str.split(',',10);
console.log(arr2);//["myageis20", "herageisalso20", "youageis25."]说明:如果第二个参数设置的大于字符串分割为数组的最大长度 ,则直接返回整个字符串被分隔的结果,和不设置效果一样
RegExp时:
var reg = /is\d+/;
var str = 'myageis20,herageisalso20,youageis25.hisageis22!';
console.log(str.split(reg));//["myageis", ",herageisalso", ",youageis", ".hisageis", "!"]var reg = /(is)(\d+)/;
var str = 'myageis20,herageisalso20,youageis25.hisageis22!';
console.log(str.split(reg));//["myage", "is", "20", ",herageisalso20,youage", "is", "25", ".hisage", "is", "22", "!"]这里的 reg 有两个分组 分别是 is 和 \d+ , 分隔的字符 为 is后面跟数字 每进行一次分隔 所产生的数组中的每一项后面追加 匹配模式中分组匹配到的字符串 这样就一目了然了。
tip: split()函数 和 数组对象的 Array.join() 他们是两个相反的操作。
几个与正则表达式相关的函数 大概就说这么多吧!
6.创建RegExp时注意特殊符号的使用
//会报错 这里的? 被当成修饰符来用了 单独使用修饰符会出错的 前面已经讲解过了
var reg =/?/;
var str = '?';
console.log(reg.test(str));
reg = /\?/; //所以必须对?进行转义
console.log(reg.test(str));//true//但是如果用RegExp构造函数来声明正则的时候
var reg = new RegExp('\?','g');//这样也会报错 原因是 使用这种声明方法 跟字面量声明 /?/g 是等价的 构造函数声明 必须使用双重转义
var str = 'this is ok?';
console.log(reg.test(str));reg = new RegExp('\\?','g');
var str = 'this is ok?';
console.log(reg.test(str));//true7.分组和非捕获性分组
//分组和非捕获性分组
var reg = /is(?:\d+)/;
var str = 'myageis20,herageisalso20,youageis25.';
var newStr = reg.exec(str);
console.log(newStr);//["is20", index: 5, input: "myageis20,herageisalso20,youageis25."]
//结果 并没有 20这一项 就是因为分组前面添加了?: 成为了非捕获性分组了var reg = /is(\d+)/g;的铁路图表示法
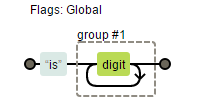
var reg = /is(?:\d+)/g;的铁路图表示法
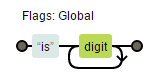
一目了然,不多说了
8.RegExp中的反向引用
//反向引用
var reg = /^<(\w+)\s*\/?>(?:<\/\1>|)$/; //匹配一组html标签 类似1:<div></div> 2:带有空格 <div ></div> 3:单标签 <img />
var str ='<div></div>'; //一个div标签
var str1 = '<div></li>';
console.log(reg.test(str));//ture
console.log(reg.test(str1));//false
//reg中的 \1 就是一个反向引用 它就代表 正则表达式中的第一个分组 匹配的结果必须和第一个分组中匹配结果相同,也就是说 反向引用保存着分组中的匹配 当然 \2 表示保存第二个分组匹配到的结果 依次类推(如果有的话)
9.正向/负向前瞻 和 正向/负向回顾
| 名称 | 表示方法 | 描述 |
| 正向前瞻 | ?= pattern | 代表后面的字符串必须匹配pattern 但是不包含pattern |
| 负向前瞻 | ?!pattern | 代表后面紧跟的字符串不能匹配pattern 而且不包含pattern 和正向前瞻相反 |
| 正向回顾 | ?<=pattern | 代表紧跟前面的字符串必须匹配pattern 但是不包含pattern |
| 负向回顾 | ?<!pattern | 代表紧跟前面的字符串不能匹配pattern 而且不包含pattern 和正向回顾相反 |
//正向前瞻
var reg = /is\d{2}(?=,)/g;
var str = 'myageis20,herageis21,youageis25.';
console.log(str.match(reg));//["is20", "is21"] //结果 只匹配 is后面是数字 数字后面有逗号的 但是不包含这个逗号
var reg1 = /is\d{2}(?!,)/g; //匹配is后面紧跟2位数字,并且数字后面不能为逗号的(不包含逗号)
console.log(str.match(reg1));//["is25"] 上面都是简单的例子 只阐明原理性的东西 复杂的正则 还需要多写多练多想
(已完)
转载请注明出处:
by 年华 :http://blog.csdn.net/wu595679200/article/details/50488020
想了解更多欢迎加入QQ群:384064953 308649768















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









