









文章目录
解决方案
MySQL 客户端侧
适当提高 MySQL JDBC 参数 netTimeoutForStreamingResults 的值。
官方文档:https://dev.mysql.com/doc/connector-j/en/connector-j-connp-props-result-sets.html
调整参数的好处是,仅影响当前客户端,对 MySQL 服务及其他客户端无明显影响。
MySQL JDBC netTimeoutForStreamingResults 默认值 600,ShardingSphere 将该参数赋予了默认值 0。
但要注意的是,netTimeoutForStreamingResults 值大于 0 且执行流式查询时,因额外执行了 SET net_write_timeout 语句,会增加 JDBC 执行 SQL 的 RTT,在一些数据量比较小或 SQL 执行很快的情况下,性能影响可能会比较明显。
MySQL 服务端侧
适当提高 net_write_timeout 的值。
可参考 MySQL 官方文档:https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_net_write_timeout
SET GLOBAL net_write_timeout=3600;
从服务端配置的好处是,不需要客户端在执行流式查询时指定写超时时间,但全局配置影响 MySQL 数据库所有客户端,调整配置时需要充分评估影响。
问题描述
前段时间,笔者无意中看到有 ShardingSphere 用户提了一个 Issue:试图使用流式查询 5000 万行数据,但 ShardingSphere-Proxy 流式查询总是报错。笔者解答问题后,用户表示问题解决。
Streaming query shardingsphere-proxy always interrupted java.sql.SQLException: null #30014
** BEGIN NESTED EXCEPTION **
java.io.EOFException
MESSAGE: Can not read response from server. Expected to read 152 bytes, read 29 bytes before connection was unexpectedly lost.
STACKTRACE:
java.io.EOFException: Can not read response from server. Expected to read 152 bytes, read 29 bytes before connection was unexpectedly lost.
at com.mysql.cj.protocol.FullReadInputStream.readFully(FullReadInputStream.java:67)
省略部分调用栈...
at com.mysql.cj.protocol.a.NativeProtocol.read(NativeProtocol.java:1651)
at com.mysql.cj.protocol.a.result.ResultsetRowsStreaming.next(ResultsetRowsStreaming.java:194)
at com.mysql.cj.protocol.a.result.ResultsetRowsStreaming.close(ResultsetRowsStreaming.java:116)
at com.mysql.cj.jdbc.result.ResultSetImpl.realClose(ResultSetImpl.java:1950)
at com.mysql.cj.jdbc.result.ResultSetImpl.close(ResultSetImpl.java:564)
at com.zaxxer.hikari.pool.HikariProxyResultSet.close(HikariProxyResultSet.java)
at org.apache.shardingsphere.proxy.backend.connector.DatabaseConnector.closeResultSets(DatabaseConnector.java:410)
at org.apache.shardingsphere.proxy.backend.connector.DatabaseConnector.close(DatabaseConnector.java:395)
at org.apache.shardingsphere.proxy.frontend.mysql.command.query.text.query.MySQLComQueryPacketExecutor.close(MySQLComQueryPacketExecutor.java:128)
省略部分调用栈...
at org.apache.shardingsphere.proxy.frontend.command.CommandExecutorTask.run(CommandExecutorTask.java)
at com.alibaba.ttl.TtlRunnable.run(TtlRunnable.java:60)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
** END NESTED EXCEPTION **
关于 MySQL 流式查询在网上有很多资料可以参考,本文不赘述。
深入探究问题根因
笔者水平有限,如有描述不正确的内容请读者及时指正。
恰好笔者之前遇到过现象相同的问题:
使用 ShardingSphere 进行 128 分库不分表,SQL 全路由大数据量流式查询在执行数分钟后,客户端程序发生异常导致查询中断。
为什么会发生 EOFException?
之前遇到这个问题的时候,第一现象是 MySQL 数据库 TCP 连接被断开,导致流式查询无法继续读取数据。但当时排查了数据库各项指标,没有发现异常。
由于该问题是必现,对 MySQL 客户端(ShardingSphere-Proxy)与 MySQL 之间的网络进行了抓包,并向 DBA 要到了 MySQL 数据库日志。发现以下现象:
MySQL 日志中有因为网络写超时导致数据库服务端主动断开连接。
我们从抓包文件中挑选一个数据库连接进行分析。
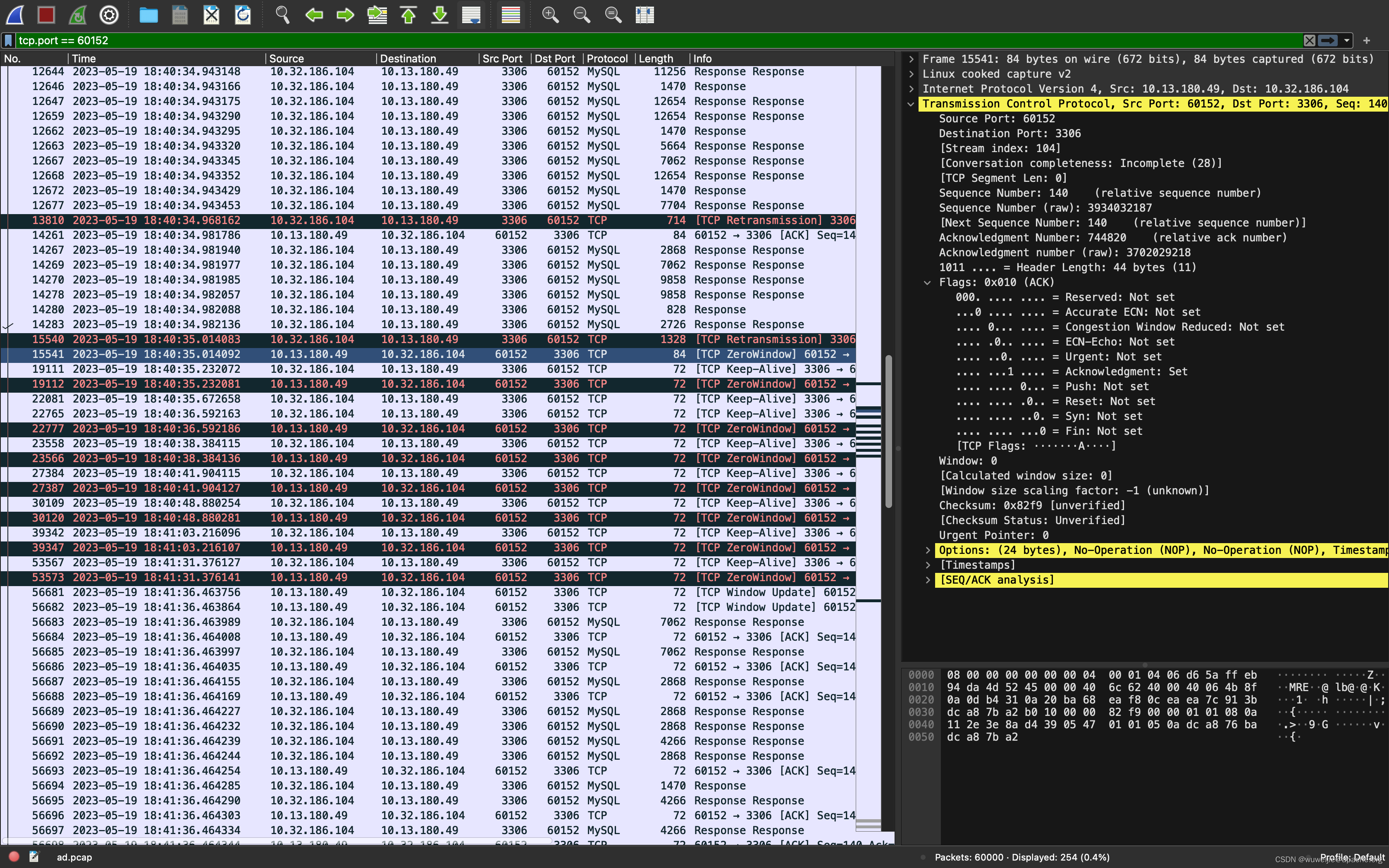
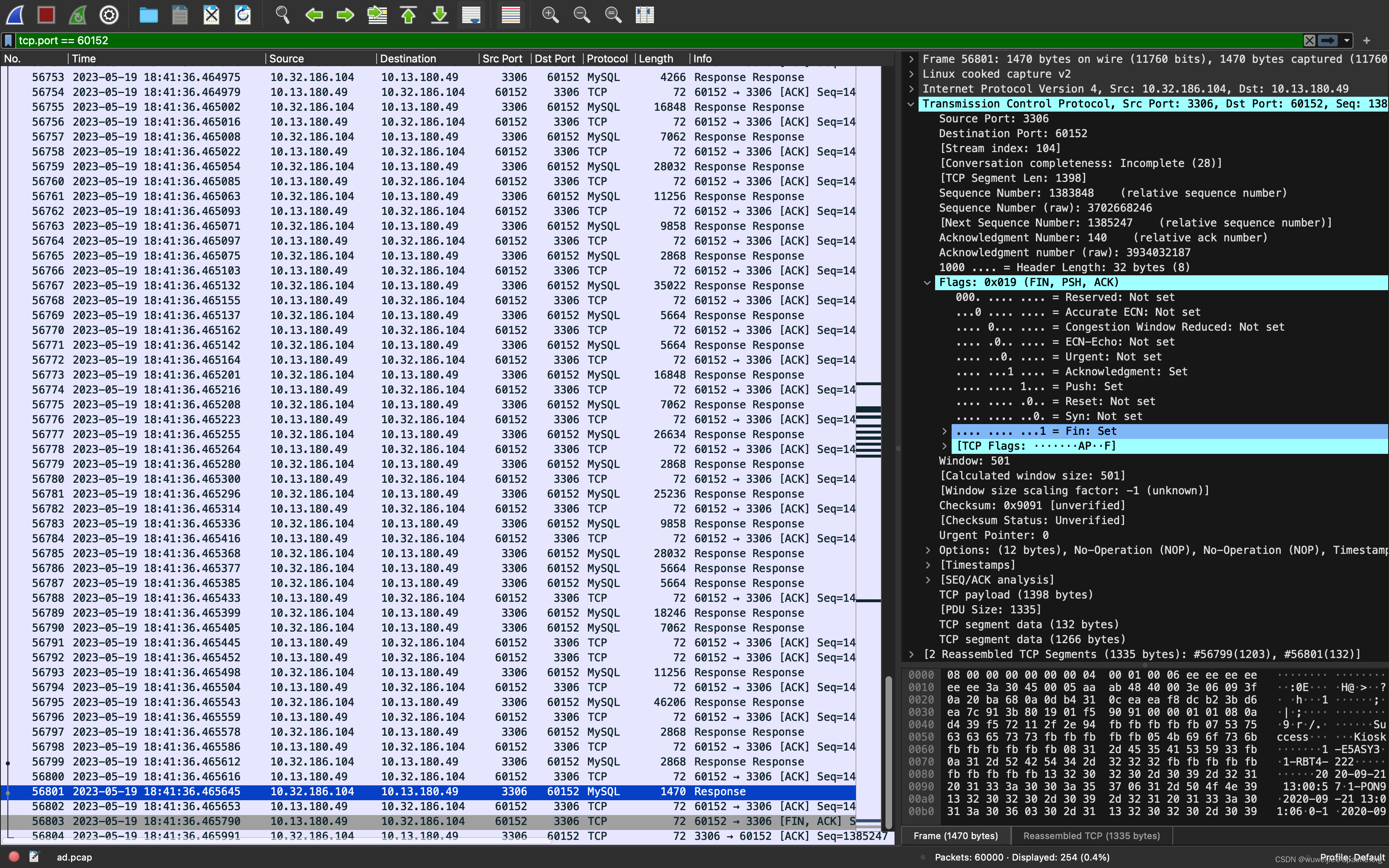
抓包显示,MySQL 客户端(ShardingSphere-Proxy)在 18:40:34.788387 向 MySQL 执行 SQL。MySQL 在 18:40:34:800810 开始响应数据。

MySQL 开始响应数据的 200 毫秒后,MySQL 客户端侧响应 TCP ZeroWindow 状态,无法继续接收数据。
从以上现象得到初步结论:
ShardingSphere-Proxy 发起了流式查询,但却没能及时消费数据,MySQL 服务端写入等待超时断开了数据库连接后,ShardingSphere-Proxy 才开始消费流式查询结果集。从已关闭的连接读取数据,发生 EOFException。
ShardingSphere 什么时候会发起流式查询?
ShardingSphere 定义了两种 ConnectionMode
public enum ConnectionMode {
MEMORY_STRICTLY, CONNECTION_STRICTLY
}
从命名上就能看出:
MEMORY_STRICTLY侧重于限制内存使用,相当于用连接数换空间;CONNECTION_STRICTLY侧重于限制连接数使用,相当于空间换连接数。
那以上两种模式又分别在什么时候使用?
@Override
public final ExecutionGroupContext<T> prepare(final RouteContext routeContext, final Map<String, Integer> connectionOffsets, final Collection<ExecutionUnit> executionUnits,
final ExecutionGroupReportContext reportContext) throws SQLException {
Collection<ExecutionGroup<T>> result = new LinkedList<>();
for (Entry<String, List<SQLUnit>> entry : aggregateSQLUnitGroups(executionUnits).entrySet()) {
String dataSourceName = entry.getKey();
List<SQLUnit> sqlUnits = entry.getValue();
List<List<SQLUnit>> sqlUnitGroups = group(sqlUnits);
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
result.addAll(group(dataSourceName, connectionOffsets.getOrDefault(dataSourceName, 0), sqlUnitGroups, connectionMode));
}
return decorate(routeContext, result, reportContext);
}
private List<List<ExecutionUnit>> group(final List<ExecutionUnit> sqlUnits) {
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
return Lists.partition(sqlUnits, desiredPartitionSize);
}
上面代码中的 aggregateSQLUnitGroups(executionUnits) 方法返回值是一个 Map<String, List<SQLUnit>>,其中 key 为数据源名称,value 为该数据源需要执行的 SQL 条数。
有一个关键参数 maxConnectionsSizePerQuery,命名上可能不是特别精确,这个参数控制的是,每次执行 SQL 允许从每个数据源获取的最大连接数。
也许参数名叫做 maxConnectionSizeOfEachDataSourcePerQuery 会更准确。
关于 ConnectionMode 的选择可以大致总结为:数据源最大连接数少于该数据源需要执行的 SQL 数量,则使用 CONNECTION_STRICTLY,否则反之。
我们举一些实际的例子:
- 假设 128 分库不分表的场景,此时每个数据源的 SQLUnit(需要执行的 SQL)数量一般只有 1 个,不会大于
maxConnectionsSizePerQuery最小值 1,所以一般都会走到MEMORY_STRICTLY; - 假设 128 分表不分库的场景,在全路由的情况下,每个数据源的 SQLUnit(需要执行的 SQL)数量有可能高达 128 个(不考虑多分表 UNION ALL 查询),此时除非
maxConnectionsSizePerQuery设置为 128,否则一般会走到CONNECTION_STRICTLY模式。
以上就是对 ShardingSphere ConnectionMode 的大致介绍,具体逻辑还可能因实际场景的不同存在差异,逻辑仅供参考。
为什么 ShardingSphere 发起了流式查询却没有及时消费数据?
使用 ShardingSphere 执行非单点查询时,向多个数据源执行 SQL 后,需要对多个结果集进行归并后再返回给请求发起方。ShardingSphere 对结果集的归并在不同的场景下存在差异,例如涉及 ORDER BY 的查询,会在 ShardingSphere 内部以类似归并排序的形式访问结果集。
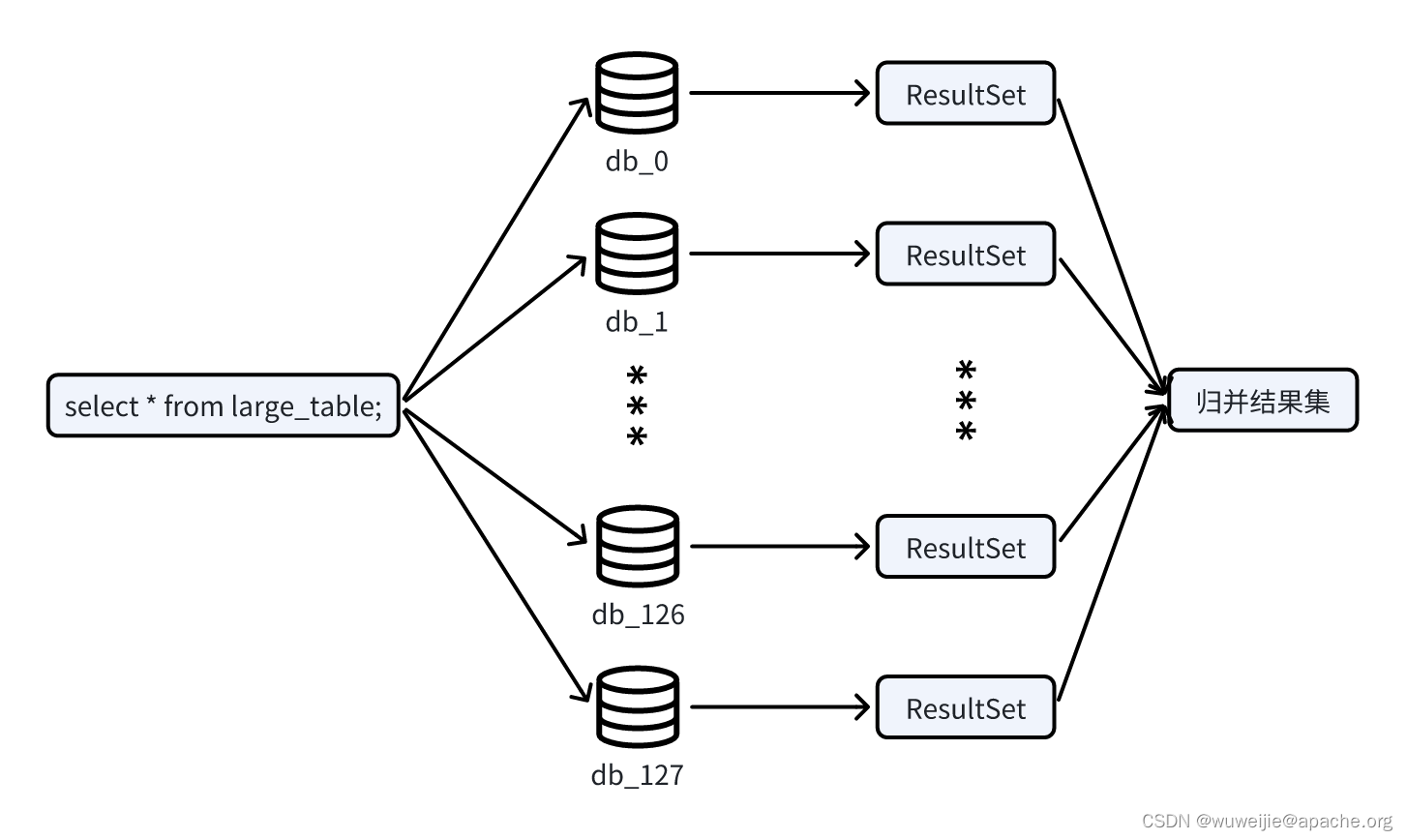
对于本文出问题的场景,128 分库不分表 SQL 全路由大数据量查询,不涉及排序或聚合等计算,ShardingSphere 只需串行遍历结果集即可完成归并,对应的就是以下方法结尾的 return,其中 queryResults 是对 JDBC ResultSet 的封装:
https://github.com/apache/shardingsphere/blob/5.4.1/features/sharding/core/src/main/java/org/apache/shardingsphere/sharding/merge/dql/ShardingDQLResultMerger.java#L83-L99
private MergedResult build(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext,
final Map<String, Integer> columnLabelIndexMap, final ShardingSphereDatabase database) throws SQLException {
String defaultSchemaName = new DatabaseTypeRegistry(selectStatementContext.getDatabaseType()).getDefaultSchemaName(database.getName());
ShardingSphereSchema schema = selectStatementContext.getTablesContext().getSchemaName()
.map(database::getSchema).orElseGet(() -> database.getSchema(defaultSchemaName));
if (isNeedProcessGroupBy(selectStatementContext)) {
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema);
}
if (isNeedProcessDistinctRow(selectStatementContext)) {
setGroupByForDistinctRow(selectStatementContext);
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema);
}
if (isNeedProcessOrderBy(selectStatementContext)) {
return new OrderByStreamMergedResult(queryResults, selectStatementContext, schema);
}
return new IteratorStreamMergedResult(queryResults);
}
串行遍历结果集的逻辑如下:对每个 QueryResult(即 ResultSet)持续调用 next() 方法,如果当前 QueryResult next() 结束了,就换下一个 QueryResult 继续调用 next()。
https://github.com/apache/shardingsphere/blob/5.4.1/features/sharding/core/src/main/java/org/apache/shardingsphere/sharding/merge/common/IteratorStreamMergedResult.java#L40-L57
public boolean next() throws SQLException {
if (getCurrentQueryResult().next()) {
return true;
}
if (!queryResults.hasNext()) {
return false;
}
setCurrentQueryResult(queryResults.next());
boolean hasNext = getCurrentQueryResult().next();
if (hasNext) {
return true;
}
while (!hasNext && queryResults.hasNext()) {
setCurrentQueryResult(queryResults.next());
hasNext = getCurrentQueryResult().next();
}
return hasNext;
}
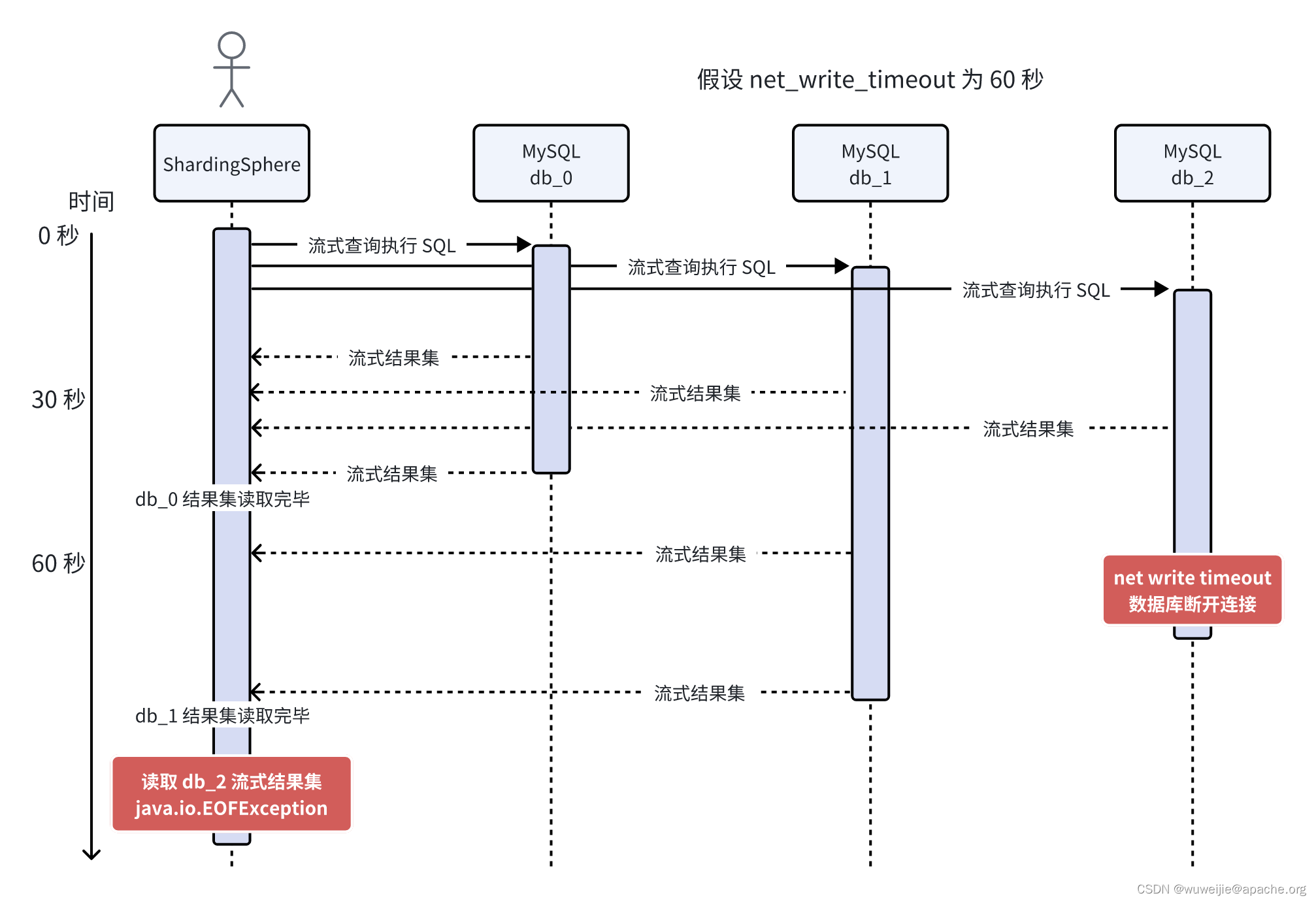
在数据量比较大的情况下,榨干每个结果集(持续调用 ResultSet 获取数据直到 next() 为 false)可能需要数十秒,此时串行遍历的问题就凸现了。时序图如下:
假设每个 ResultSet 获取全部数据需要花费 40 秒时间:
- ShardingSphere-Proxy 执行所有查询 SQL;
- SQL 执行后,开始从 db_0 的流式结果集获取数据;
- 第 40 秒,db_0 数据取完,开始获取 db_1 流式结果集的数据;
- 在第 60 秒的时候,但由于 db_2 的响应写入已经阻塞超过 60 秒时间(net_write_timeout 默认值 60 秒),db_2 服务端主动断开了数据库连接。不过由于客户端的读缓冲区、服务端的写缓冲区均积压了数据,TCP FIN 会随服务端发送缓冲区最末尾的数据发送,从抓包结果上看连接不会立即断开。
- 第 80 秒后,db_1 数据取完,开始获取 db_2 流式结果集的数据。此时客户端开始消费读缓冲区积压的数据,服务端写缓冲区积压的数据也开始发送给客户端。等到服务端写缓冲区中带有的 FIN 的数据被客户端接收后,TCP 连接四次挥手断开。由于此时客户端流式查询还在继续进行读操作,对已关闭 Socket 进行读取操作,发生报错。
ShardingSphere-Proxy 消费流式结果集不及时的原因大致如上。
为什么 MySQL JDBC netTimeoutForStreamingResults 默认 600,ShardingSphere 却设置了 0?
笔者跟踪到历史非常久远的 PR:
[Proxy performance] Set property netTimeoutForStreamingResults=0 for Connector/J #1113
笔者在本文前面部分 ShardingSphere 什么时候会发起流式查询? 已经介绍了 ShardingSphere 的 ConnectionMode,在连接充足的情况下,ShardingSphere 可能会使用流式查询执行语句以尽量减少内存使用。
为什么参数 netTimeoutForStreamingResults 会影响性能?
本文以 MySQL Connector/J 8.0.31 为例,从源码看参数 netTimeoutForStreamingResults 具体做了什么。
我们先看使用了 netTimeoutForStreamingResults 参数的代码逻辑:
https://github.com/mysql/mysql-connector-j/blame/8.0.31/src/main/user-impl/java/com/mysql/cj/jdbc/StatementImpl.java#L628-L634
/**
* Adjust net_write_timeout to a higher value if we're streaming result sets. More often than not, someone runs into
* an issue where they blow net_write_timeout when using this feature, and if they're willing to hold a result set open
* for 30 seconds or more, one more round-trip isn't going to hurt.
*
* This is reset by RowDataDynamic.close().
*
* @param con
* created this statement
* @throws SQLException
* if a database error occurs
*/
protected void setupStreamingTimeout(JdbcConnection con) throws SQLException {
int netTimeoutForStreamingResults = this.session.getPropertySet().getIntegerProperty(PropertyKey.netTimeoutForStreamingResults).getValue();
if (createStreamingResultSet() && netTimeoutForStreamingResults > 0) {
executeSimpleNonQuery(con, "SET net_write_timeout=" + netTimeoutForStreamingResults);
}
}
当启用流式查询且 netTimeoutForStreamingResults 参数大于 0 时,向数据库执行 SET net_write_timeout 语句设置写超时时间。
再看 setupStreamingTimeout 方法的上层调用,上层调用有多处,此处取其中一处分析:
https://github.com/mysql/mysql-connector-j/blame/8.0.31/src/main/user-impl/java/com/mysql/cj/jdbc/StatementImpl.java#L1124
@Override
public java.sql.ResultSet executeQuery(String sql) throws SQLException {
synchronized (checkClosed().getConnectionMutex()) {
JdbcConnection locallyScopedConn = this.connection;
this.retrieveGeneratedKeys = false;
checkNullOrEmptyQuery(sql);
resetCancelledState();
implicitlyCloseAllOpenResults();
if (sql.charAt(0) == '/') {
if (sql.startsWith(PING_MARKER)) {
doPingInstead();
return this.results;
}
}
setupStreamingTimeout(locallyScopedConn);
executeQuery 是 JDBC 执行查询的关键方法之一,在每次执行流式查询前执行 SET net_write_timeout 语句,网络来回的耗时对于简单查询语句不容忽视。
所以 ShardingSphere 在创建 MySQL 数据源时,默认把 netTimeoutForStreamingResults 设置为 0 以减少 SET net_write_timeout 的性能影响。
本文写到这里,笔者已经暂时没有想到可以继续深入挖掘的点了。后续有遇到其他问题或想法再继续作一些思考与记录。















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











