







目录
服务查询(InstanceOperatorClientImpl)
根据条件过滤实例( ServiceUtil.doSelectInstances)
流程图
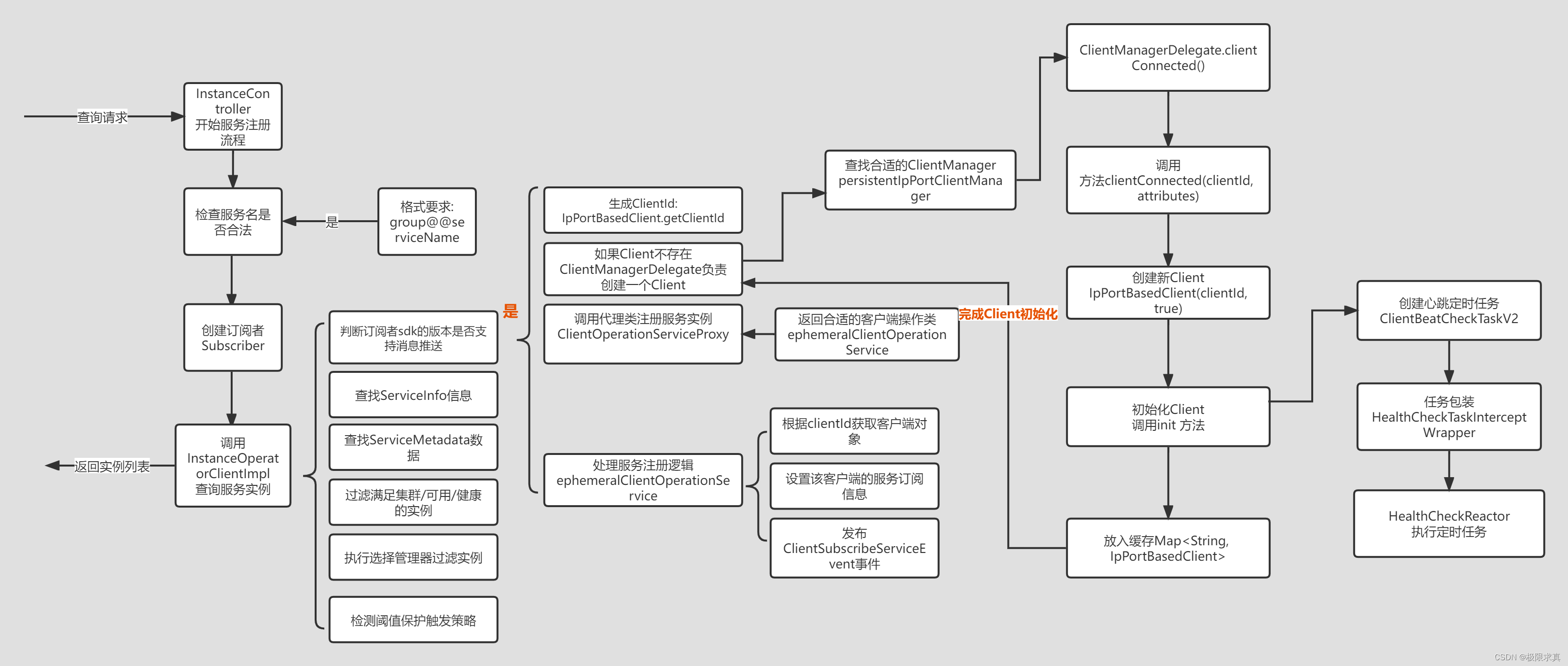
服务查询(InstanceOperatorClientImpl)
public class InstanceOperatorClientImpl implements InstanceOperator {
//客户端管理器
private final ClientManager clientManager;
//客户端操作服务 有2种具体实现
// EphemeralClientOperationServiceImpl
// PersistenceClientOperationServiceImpl
private final ClientOperationService clientOperationService;
//服务存储服务 后面我们会讲 ServiceStorage 跟
// ClientServiceIndexesManager 有什么区别 都是管理服务的
private final ServiceStorage serviceStorage;
//元数据管理器
private final NamingMetadataManager metadataManager;
private final NamingMetadataOperateService metadataOperateService;
//可以理解成全局的配置开关
private final SwitchDomain switchDomain;
//udp推送服务
private final UdpPushService pushService;
@Override
public ServiceInfo listInstance(String namespaceId, String serviceName, Subscriber
subscriber, String cluster, boolean healthOnly) {
//构建service
Service service = getService(namespaceId, serviceName, true);
// 判断客户端sdk是否支持推送功能
if (subscriber.getPort() > 0 && pushService.canEnablePush(subscriber.getAgent())) {
String clientId = IpPortBasedClient.getClientId(subscriber.getAddrStr(), true);
//创建客户端这里不在赘述创建客户端的逻辑需要了解客户端的朋友异步到前面
//的客户端章节
createIpPortClientIfAbsent(clientId);
//EphemeralClientOperationServiceImpl 完成服务注册功能
clientOperationService.subscribeService(service, subscriber, clientId);
}
//查询服务信息包括所有的实例列表
ServiceInfo serviceInfo = serviceStorage.getData(service);
//查询服务的元数据信息
ServiceMetadata serviceMetadata =
metadataManager.getServiceMetadata(service).orElse(null);
//对实例列表根据集群名称/是否可用/是否健康/自定义过滤器/阈值保护层曾过滤
ServiceInfo result = ServiceUtil
.selectInstancesWithHealthyProtection(serviceInfo, serviceMetadata,
cluster, healthOnly, true, subscriber.getIp());
// adapt for v1.x sdk
result.setName(NamingUtils.getGroupedName(result.getName(),
result.getGroupName()));
return result;
}
}
selectInstancesWithHealthyProtection方法总的来说完成3件事情
1、创建保护 阈值保护和执行用户自定义查询条件功能的过滤器
2、查询【所属集群内】的节点同时根据 【是否只查询可用实例】 标志 和 【是否只查询健康实例】 标志筛选实例列表
3、把第二步的筛选结果应用到第一个步骤的过滤器
根据条件过滤实例( ServiceUtil.doSelectInstances)
public final class ServiceUtil {
....
/**
* Select instance of service info with healthy protection.
*
* @param serviceInfo original service info
* @param serviceMetadata service meta info
* @param cluster cluster of instances
* @param healthyOnly whether only select instance which healthy
* @param enableOnly whether only select instance which enabled
* @param subscriberIp subscriber ip address
* @return new service info
*/
public static ServiceInfo selectInstancesWithHealthyProtection(ServiceInfo serviceInfo, ServiceMetadata serviceMetadata, String cluster,
boolean healthyOnly, boolean enableOnly, String subscriberIp) {
....
return doSelectInstances(serviceInfo, cluster, healthyOnly, enableOnly, filter);
}
/**
* 根据条件过滤实例列表
*
* @param serviceInfo original service info
* @param cluster cluster of instances
* @param healthyOnly whether only select instance which healthy
* @param enableOnly whether only select instance which enabled
* @param filter do some other filter operation
* @return new service info
*/
private static ServiceInfo doSelectInstances(ServiceInfo serviceInfo, String cluster,
boolean healthyOnly, boolean enableOnly,
InstancesFilter filter) {
ServiceInfo result = new ServiceInfo();
result.setName(serviceInfo.getName());
result.setGroupName(serviceInfo.getGroupName());
result.setCacheMillis(serviceInfo.getCacheMillis());
result.setLastRefTime(System.currentTimeMillis());
result.setClusters(cluster);
result.setReachProtectionThreshold(false);
//把集群字符串分割成set 列表
Set<String> clusterSets =
com.alibaba.nacos.common.utils.StringUtils.isNotBlank(cluster) ?
new HashSet<>(Arrays.asList(cluster.split(","))) : new HashSet<>();
//统计健康实例数
long healthyCount = 0L;
List<com.alibaba.nacos.api.naming.pojo.Instance> filteredInstances =
new LinkedList<>();
//过滤后的实例列表
List<com.alibaba.nacos.api.naming.pojo.Instance> allInstances
= new LinkedList<>();
for (com.alibaba.nacos.api.naming.pojo.Instance ip : serviceInfo.getHosts()) {
//clusterSets是否包含ip所属的集群
//如果enableOnly为true代表实例要求可用否则 允许返回不可用的实例
if (checkCluster(clusterSets, ip) && checkEnabled(enableOnly, ip)) {
//如果healthyOnly 为true代表实例要求健康否则 允许返回不健康的实例
if (!healthyOnly || ip.isHealthy()) {
//healthyOnly 为true时 filteredInstances只包括健康实例
//healthyOnly 为false时 filteredInstances包括所有实例
//此时filteredInstances的记录跟allInstances记录一致
filteredInstances.add(ip);
}
//统计健康的实例数
if (ip.isHealthy()) {
healthyCount += 1;
}
//记录所有健康不健康的实例列表
allInstances.add(ip);
}
}
//设置过滤后的实例列表
result.setHosts(filteredInstances);
if (filter != null) {
//交给过滤器去过滤一遍
filter.doFilter(result, allInstances, healthyCount);
}
return result;
}
....
//运行clusterSets为空代表查询的集群字符串为空 无需校验实例的集群
private static boolean checkCluster(Set<String> clusterSets,
com.alibaba.nacos.api.naming.pojo.Instance instance) {
if (clusterSets.isEmpty()) {
return true;
}
//包含当前实例的集群则返回true
return clusterSets.contains(instance.getClusterName());
}
private static boolean checkEnabled(boolean enableOnly,
com.alibaba.nacos.api.naming.pojo.Instance instance) {
return !enableOnly || instance.isEnabled();
}
}方法的几个变量的意义:
filteredResult 满足集群名称匹配、可用条件、健康条件 过滤后的实例列表
allInstances 满足集群条件和可用条件的实例列表
healthyCount 满足集群条件和可用条件 且健康的实例列表最终设置到返回结果的是filteredResult结果
如果过滤器不为空 把统计结果交给过滤器 处理
健康阈值保护
public final class ServiceUtil {
....
public static ServiceInfo selectInstancesWithHealthyProtection(ServiceInfo serviceInfo, ServiceMetadata serviceMetadata, String cluster,
boolean healthyOnly, boolean enableOnly, String subscriberIp) {
//filteredResult 满足集群名称匹配、可用条件、健康条件 过滤后的实例列表
//allInstances 满足集群条件和可用条件的实例列表
//healthyCount 满足集群条件和可用条件 且健康的实例列表
InstancesFilter filter = (filteredResult, allInstances, healthyCount) -> {
if (serviceMetadata == null) {
return;
}
allInstances = filteredResult.getHosts();
int originalTotal = allInstances.size();
// filter ips using selector
SelectorManager selectorManager =
ApplicationUtils.getBean(SelectorManager.class);
//交给服务元数据的查询处理器处理
allInstances = selectorManager.select(serviceMetadata.getSelector(),
subscriberIp, allInstances);
//设置selector过滤后的结果
filteredResult.setHosts(allInstances);
// will re-compute healthCount
//这里为啥不是初始为0 有读者知道为什么的可以评论群回复下
long newHealthyCount = healthyCount;
//如果selector成功过滤了记录 重新计算健康数
if (originalTotal != allInstances.size()) {
for (com.alibaba.nacos.api.naming.pojo.Instance allInstance :
allInstances) {
if (allInstance.isHealthy()) {
newHealthyCount++;
}
}
}
//读取阈值保护值
float threshold = serviceMetadata.getProtectThreshold();
if (threshold < 0) {
threshold = 0F;
}
if ((float) newHealthyCount / allInstances.size() <= threshold) {
//设置触发阈值保护状态为true
filteredResult.setReachProtectionThreshold(true);
List<com.alibaba.nacos.api.naming.pojo.Instance> filteredInstances =
allInstances.stream()
.map(i -> {
if (!i.isHealthy()) {
//对于不健康的实例我们拷贝出新得实例并设置健康状态为true
//这里不能直接修改真实实例得健康属性
i = InstanceUtil.deepCopy(i);
i.setHealthy(true);
}
return i;
})
.collect(Collectors.toCollection(LinkedList::new));
//最后赋值给要返回得对象
filteredResult.setHosts(filteredInstances);
}
};
return doSelectInstances(serviceInfo, cluster, healthyOnly, enableOnly, filter);
}
....
}这里有一个疑问:
为什么newHealthyCount 要初始化为healthyCount 而不是0.如果有读者知道原因,可以评论区留言 long newHealthyCount = healthyCount;
阈值保护得思路是:如果 健康实例数/总实例数 < 阈值 那就把所有不健康得实例转变为健康的实例,让用户误以为都是健康的时候,这样不会让所有的请求都打到少量健康的机器而发生服务雪崩。这个策略非常重要。如果么有阈值保护。很快剩余的健康节点在大流量下都可能会挂掉。
接下来我们看看Instance的深拷贝是怎么实现的?
实例深拷贝
public class InstanceUtil {
/**
* Deepcopy one instance.
*
* @param source instance to be deepcopy
*/
public static Instance deepCopy(Instance source) {
Instance target = new Instance();
target.setInstanceId(source.getInstanceId());
target.setIp(source.getIp());
target.setPort(source.getPort());
target.setWeight(source.getWeight());
target.setHealthy(source.isHealthy());
target.setEnabled(source.isEnabled());
target.setEphemeral(source.isEphemeral());
target.setClusterName(source.getClusterName());
target.setServiceName(source.getServiceName());
target.setMetadata(new HashMap<>(source.getMetadata()));
return target;
}
}
}实际上这里的深拷贝就是把所有属性赋值给新对象。深拷贝最主要的目的就是从原本的对象拷贝一份而不是直接引用之前的对象。所以如果有复杂类型的对象就会比较复杂。
这里的属性基本都是基本类型或者字符串对象,没有太复杂的对象所以拷贝比较简单。
像这个Metadata对象就需要通过new HashMap 重新new一个对象 再赋值 target.setMetadata(new HashMap<>(source.getMetadata()));
而不能直接像下面这样赋值
target.setMetadata(source.getMetadata);
总结
至此,我们通过把服务查询的3个部分服务订阅、服务实例查询、实例过滤与阈值保护3个重要的逻辑都讲解完毕。
接下了我们会用专门的章节来介绍之前代码中遇到比较多的 NamingMetadataManager、ServiceMetadata、InstanceMetadata等。














 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









