







详解 InnoDB ReplicaSet
InnoDB ReplicaSet 是什么?
InnoDB ReplicaSet ,即 InnoDB 副本集,是一组由 AdminAPI 管理的一组使用基于 GTID 的异步复制的 MySQL 实例组成的集群集合。它由单 主(服务器实例)和多 辅助(服务器实例)组成(在 MySQL 复制 中通常叫做 源 和 副本)。
类似于 InnoDB Cluster ,InnoDB ReplicaSet 深度依赖 MySQL Shell 和 MySQL Router ,但它不提供 InnoDB Cluster 所具备的高可用性。通过 AdminAPI ,可以使用 ReplicaSet 对象来管理它。同时, MySQL Router 也支持对其进行引导,引导过程是自动配置的。因此,它适用于在不需要高可用的使用场景中横向扩展读取能力,并提供手动故障转移功能。
InnoDB ReplicaSet 底层基于 MySQL 异步复制技术。因而,它适用于 MySQL 服务器实例部署在广域网(WAN,Wide Area Network),彼此通过异步复制通道连接,辅助实例可容忍更大程度的复制延迟,且不需要在事务上达成共识的场景。
此外,你可以使用 AdminAPI 采用一个已有的复制拓扑来部署一个 InnoDB ReplicaSet ,之后可以像管理从头创建的 InnoDB ReplicaSet 一样管理它。InnoDB ReplicaSet 相较于 MySQL 复制 的优势在于可以使用 MySQL Shell 和 MySQL Router 更简单、方便、快捷的管理,而不需要使用第三方中间件来管理主从架构、故障转移、路由、重定向。
InnoDB ReplicaSet 的优缺点
上面其实已经提及了它的优缺点,按参照对象分析如下:
- 对比 MySQL 复制 :
-优点: InnoDB ReplicaSet提供更好的写性能,这是使用它的主要原因。 而且,它通过 MySQL Shell 提供了更加简单、方便、快捷的管理方式。
-缺点: 所有管理操作必须要通过 MySQL Shell 来完成,不能直连到主实例上配置系统变量。 - 对比 InnoDB Cluster :
- 优点:InnoDB ReplicaSet 对网络的要求不高,支持在广域网跨地域的不稳定或缓慢的网络上部署,允许更大的复制延迟,可以覆盖一些不适合使用 InnoDB Cluster 的场景。
- 缺点:它属于低配版,不提供高可用,底层使用的是复制而非组复制,因而不需要所有成员在某个事务上达成共识,不支持自动故障转移,且在发生故障转移或网络分区事件时,有发生脑裂的可能。
InnoDB ReplicaSet 的限制
- 无自动故障转移。在主服务器不可用的情况下,需要使用 AdminAPI 手动触发故障切换,然后才能再次进行任何更改。但是,辅助实例仍然可用于读取。
- 由于意外暂停或不可用,无法防止部分数据丢失:在意外暂停时未完成的事务可能会丢失。
- 意外退出或不可用后,无法防止不一致。如果手动故障切换提升了一个辅助实例,而前一个主实例仍然可用,例如,由于网络分区,则大脑分裂的情况可能会导致数据不一致。
- InnoDB ReplicaSet 不支持多主模式。使用允许写入所有成员的经典复制拓扑无法保证数据一致性。
- 读取扩展受限。 InnoDB ReplicaSet 基于异步复制,因此不可能像组复制那样调整流控制。
- 所有辅助成员都从单个源复制。对于某些特定的用例,这可能会影响单个源,例如,许多小更新。
- 仅支持运行 MySQL 8.0 及更高版本的实例。
- 仅支持基于 GTID 的复制,二进制日志文件位置复制与 InnoDB ReplicaSet 不兼容。
- 仅支持基于行的复制( RBR ),不支持基于语句的复制( SBR )。
- 不支持复制筛选器。
- 任何实例上都不允许使用非托管复制通道。
- ReplicaSet 最多包含一个主实例。支持一个或多个辅助设备。虽然可以添加到 ReplicaSet 的辅助服务器数量没有限制,但连接到 ReplicaSet 上的每个 MySQL 路由器都必须监视每个实例。因此,添加到 ReplicaSet 的实例越多,监视就越多。
- ReplicaSet 必须由 MySQL Shell 管理。例如,复制帐户由 MySQL Shell 创建和管理。不支持在 MySQL Shell 外部对实例进行配置更改,例如,直接使用 SQL 语句更改主实例。始终使用 MySQL Shell 与 InnoDB ReplicaSet 一起工作。
部署 InnoDB ReplicaSet
部署过程类似于部署 InnoDB Cluster,但因基于复制而非组复制,故仅最少需要两个实例即可部署一个 InnoDB ReplicaSet 实例。
以下介绍的是从头部署一个 InnoDB ReplicaSet 实例,采用已有的 MySQL 复制拓扑的部署请参考我的后续文章。
1. 准备两个 MySQL 实例
添加新实例的配置选项到 /etc/my.cnf
在 ic-source 主机上/etc/my.cnf中添加如下内容创建 MySQL 实例 replica01:
[mysqld@replica01]
datadir=/var/lib/mysql/replica01
port=3308
mysqlx_port=33080
admin_port=33082
socket=/var/lib/mysql/replica01/mysql.sock
log-error=/var/log/mysql-replica01.log
innodb_buffer_pool_size=256M
innodb_redo_log_capacity=100M
innodb_flush_method=O_DIRECT_NO_FSYNC
在 ic-replica1 主机上/etc/my.cnf中添加如下内容创建 MySQL 实例 replica02:
[mysqld@replica02]
datadir=/var/lib/mysql/replica02
port=3310
mysqlx_port=33100
admin_port=33102
socket=/var/lib/mysql/replica02/mysql.sock
log-error=/var/log/mysql-replica02.log
innodb_buffer_pool_size=256M
innodb_redo_log_capacity=100M
innodb_flush_method=O_DIRECT_NO_FSYNC
分别在两台主机上进行预配置
分别在两台主机上执行如下操作:
- 启动 MySQL 服务器。
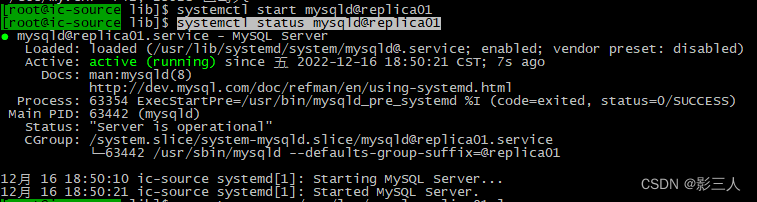
在 ic-source 主机上启动 mysqld@replica01 :
$ systemctl start mysqld@replica01
$ systemctl status mysqld@replica01
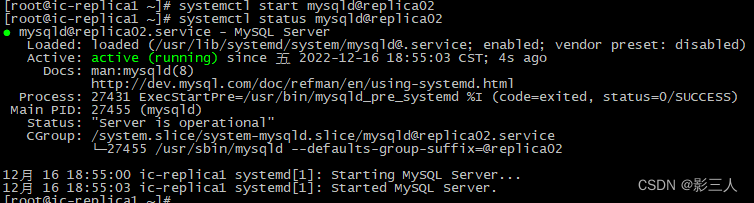
在 ic-replica1 主机上启动 mysqld@replica02 :
$ systemctl start mysqld@replica02
$ systemctl status mysqld@replica02
- 配置 root@localhost 及 root@`%` 用户
获取为 MySQL 的 root 用户初始化的临时密码,并登录 MySQL 。
$ grep temporary /var/log/mysql-replica01.log
# 替换为你配置的socket
$ mysql -uroot -p -S /var/lib/mysql/replica01/mysql.sock
执行如下 SQL 修改 root@localhost 用户的密码,创建用于远程登录的 root@`%` 用户:
mysql> alter user root@localhost identified by '要为本地root设置的密码';
mysql> create user root@`%` identified by '要为远程root设置的密码';
mysql> grant all on *.* to root@`%` with grant option;
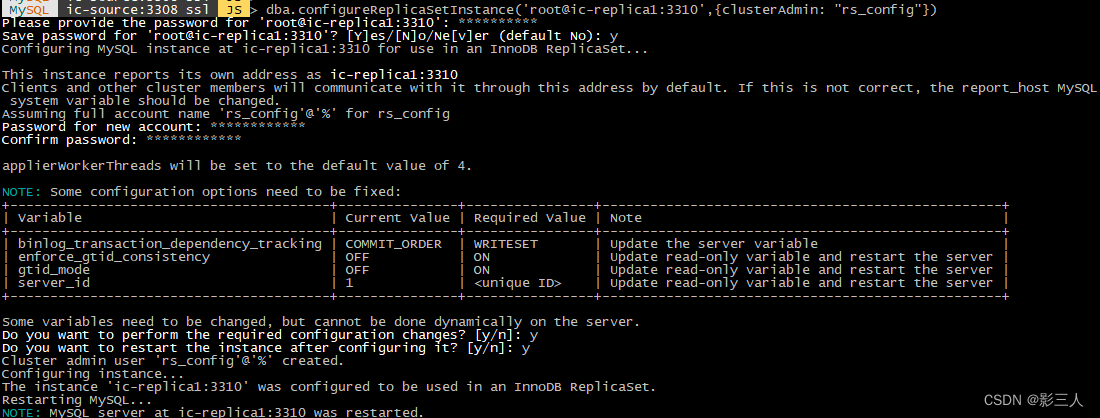
2. 使用 MySQL Shell 连接到一个实例来配置两个实例
在 ic-source 主机上启动 mysqlsh 连接到 root@ic-source:3308 :
$ mysqlsh --quiet-start=2 root@ic-source:3308
在 mysqlsh 中执行:
MySQL ic-source:3308 ssl JS > dba.configureReplicaSetInstance('root@ic-source:3308',{clusterAdmin: "rs_config"})
MySQL ic-source:3308 ssl JS > dba.configureReplicaSetInstance('root@ic-replica1:3310',{clusterAdmin: "rs_config"})
3. 创建 ReplicaSet
此处我限制了一下复制通道允许的 IP 网段,试一下安全功能。出于安全考虑,生产环境中也应该这么做。
MySQL ic-source:3308 ssl JS > rs=dba.createReplicaSet('ReplicaSet01',{replicationAllowedHost: '192.168.52.0/24'})
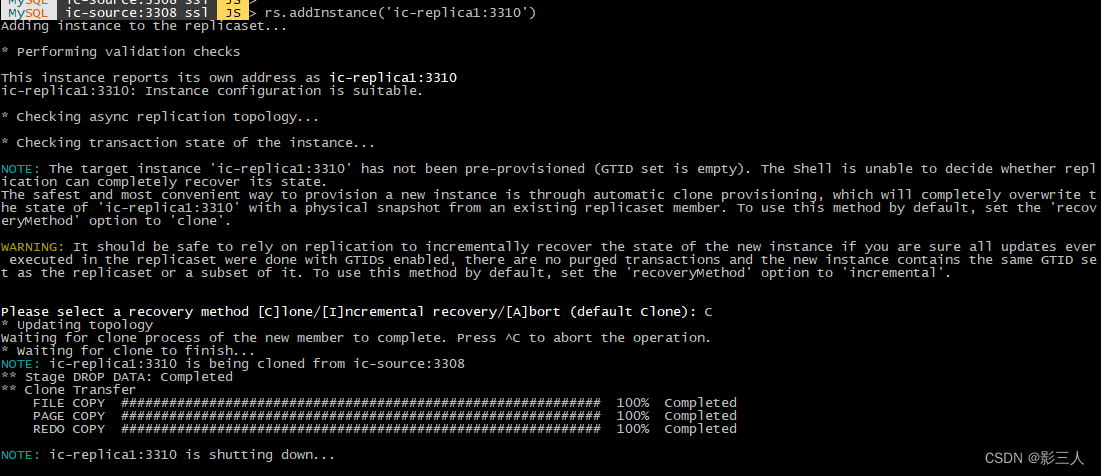
4. 将另一个实例加入到创建的 ReplicaSet
MySQL ic-source:3308 ssl JS > rs.addInstance('ic-replica1:3310')
5. 查看副本集状态
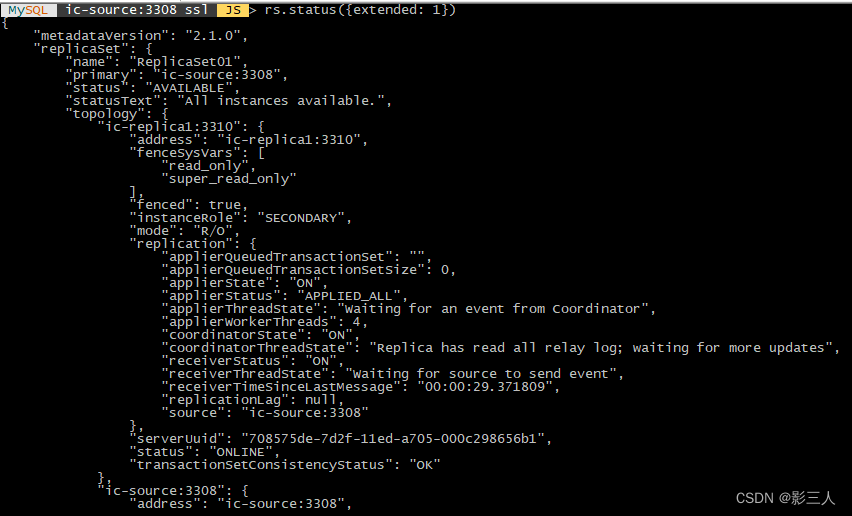
MySQL ic-source:3308 ssl JS > rs.status({extended: 1})
6. (可选)创建 ReplicaSet 的管理员账号
为了更清晰的权限管理,我们应将配置账户和管理员账户进行权限分离,即便一般情况下二者是同一个。
说明
此步骤也可以放在第二步后执行,然后通过克隆复制,而不是现在所使用的增量复制。
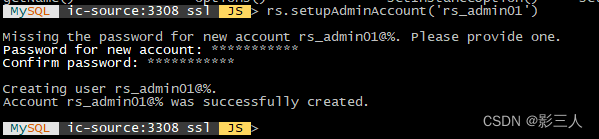
MySQL ic-source:3308 ssl JS > rs.setupAdminAccount('rs_admin01')
执行完后,我们应该可以在 replica02 实例的 relaylog 和 binlog 中查看到。
建议使用 less 查看,直接 grep 会使你的终端显示字符集乱码,需要 reset 重置才行。
$ mysqlbinlog binlog.000002| less
$ mysqlbinlog binlog.000002| grep rs_admin

$ mysqlbinlog ic-replica1-relay-bin.000002| grep rs_admin

7. 引导 MySQL Router 为 ReplicaSet 配置路由
$ mysqlrouter --bootstrap rs_config@ic-source:3308 --account rsRouter01 --user=mysqlrouter --directory=/var/lib/mysqlro
因为我这台主机上还有之前搭建的 InnoDB Cluster 和 InnoDB ClusterSet 的路由,所以此处需要修改 mysqlrouter 配置文件 mysqlrouter.conf 的端口号。简单起见,我将前四个 默认端口号 乘 10 ,http_port 加 100 设置为 8543 。
[routing:bootstrap_rw]
bind_address=0.0.0.0
bind_port=64460
[routing:bootstrap_ro]
bind_address=0.0.0.0
bind_port=64470
[routing:bootstrap_x_rw]
bind_address=0.0.0.0
bind_port=64480
[routing:bootstrap_x_ro]
bind_address=0.0.0.0
bind_port=64490
[http_server]
port=8543
8. 查看路由状态
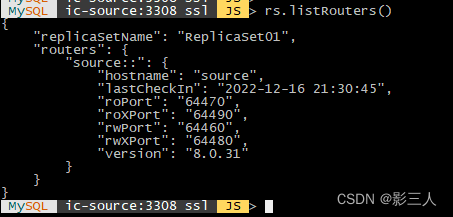
MySQL ic-source:3308 ssl JS > rs.listRouters()
9. 验证路由功能
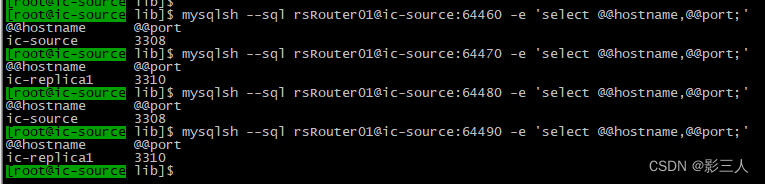
$ mysqlsh --sql rsRouter01@ic-source:64460 -e 'select @@hostname,@@port;'
$ mysqlsh --sql rsRouter01@ic-source:64470 -e 'select @@hostname,@@port;'
$ mysqlsh --sql rsRouter01@ic-source:64480 -e 'select @@hostname,@@port;'
$ mysqlsh --sql rsRouter01@ic-source:64490 -e 'select @@hostname,@@port;'
因为只有两个实例,主实例负责写,辅助实例负责读,所以无需像验证 InnoDB Cluster 时执行三次来验证。
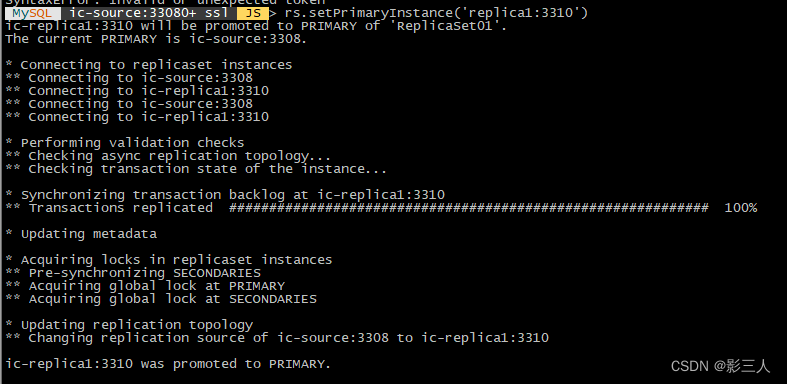
手动切主
$ mysqlsh --quiet-start=2 root@ic-source:33080
在 mysqlsh 中执行:
MySQL ic-source:33080+ ssl JS > rs=dba.getReplicaSet()
MySQL ic-source:33080+ ssl JS > rs.setPrimaryInstance('replica1:3310')
其他信息
有关 InnoDB ReplicaSet 的手动强制故障转移、打标签、升级等其他信息,请参阅 我的 《MySQL Shell 8.0 》专栏。
总结
InnoDB ReplicaSet 的关键字是 AdminAPI,MySQL Shell,MySQL Router,MySQL 异步复制 。其功能同比传统 MyCat 等中间构成的 MMM 、MHA 主从架构相差不大,可以理解为 MySQL 官方实现发行版本,但 MySQL Shell 这个 MySQL 未来主打的 DevOps 工具还是更具优势的。

















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











