







紧急故障切换会将选定的副本集群放入 InnoDB ClusterSet 部署的主 InnoDB 集群中。当当前主集群不工作或无法联系时,可以使用此过程。在紧急故障切换过程中,无法确保数据一致性,因此为了安全起见,在故障切换过程中将原始主集群标记为无效。如果原始主集群保持联机,则应在联系到它后立即关闭。您可以修复失效的主集群,然后将其重新连接到 InnoDB ClusterSet 拓扑,前提是您可以修复这些问题。
当 InnoDB ClusterSet 部署中的主 InnoDB 集群出现问题或您无法访问它时,不要立即执行到副本集群的紧急故障切换。相反,您应该始终从尝试修复当前活动的主集群开始。
重点
为什么不只是故障切换? InnoDB ClusterSet 拓扑中的副本集群正在尽最大努力保持与主集群的同步。然而,根据事务量以及主集群和副本集群之间的网络连接的速度和容量,副本集群在接收事务和将更改应用于其数据方面可能落后于主集群。这称为复制延迟(replication lag)。在大多数复制拓扑中,预期会出现一些复制延迟,在 InnoDB ClusterSet 部署中,集群在地理上分散在不同的数据中心,这种情况很可能发生。
此外,主集群可能因网络分区与 InnoDB ClusterSet 拓扑的其他元素断开连接,但仍保持在线。如果发生这种情况,一些副本集群可能和主集群保留在一起,而一些实例和客户端应用程序可能会继续连接到主集群并应用事务。在这种情况下,InnoDB ClusterSet 拓扑的分区区域开始彼此分离,每组服务器上都有不同的事务集。
当存在复制延迟或网络分区时,如果触发到副本集群的紧急故障切换,则主集群上任何未复制或不同的事务都有丢失的风险。在网络分区的情况下,故障切换会造成脑裂的情况,拓扑的不同部分具有不同的事务集。因此,在触发紧急故障切换之前,应始终尝试修复或重新连接主集群。如果无法足够快速地修复主集群或无法访问主集群,则可以继续进行紧急故障切换。
该图显示了 InnoDB ClusterSet 部署示例中紧急故障切换的效果。罗马数据中心的主集群已离线,因此已执行紧急故障切换,以使布鲁塞尔数据中心的副本集群成为 InnoDB ClusterSet 部署的主 InnoDB 集群。罗马集群已被标记为无效,其在 InnoDB ClusterSet 部署中的状态已降级为副本集群,尽管它目前无法从布鲁塞尔集群复制事务。
图 8.3 InnoDB ClusterSet 故障切换
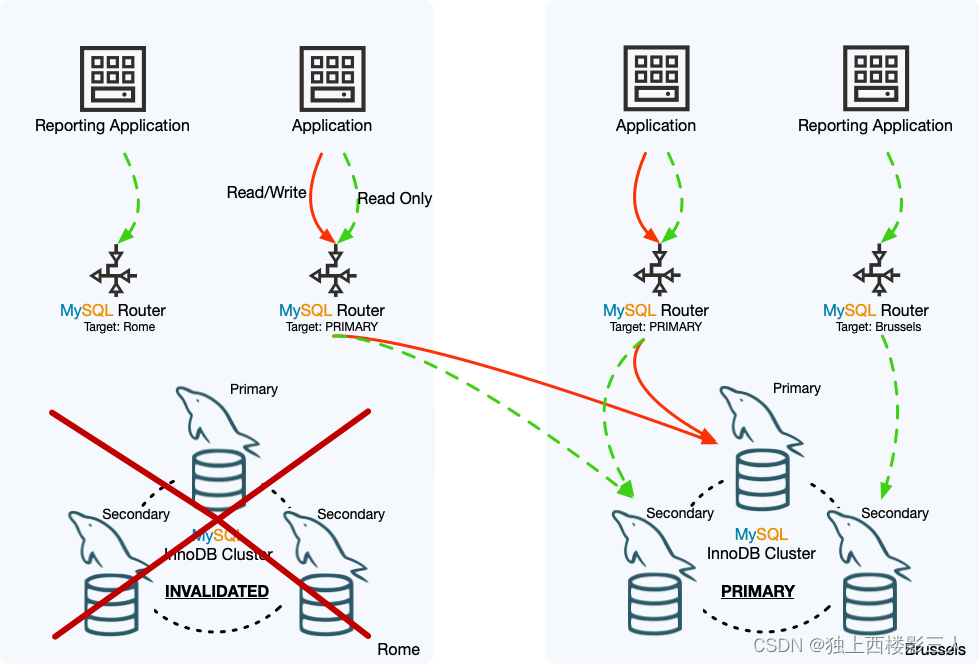
被设置为跟随主节点的 MySQL 路由器实例已将读写流量路由到布鲁塞尔集群,该集群现在是主节点。MySQL 路由器实例在复制集群时按名称将读取流量路由到布鲁塞尔集群,并继续将流量路由到该集群,并且不受该集群现在是主集群而不是复制集群这一事实的影响。然而,通过名称将读取流量路由到罗马集群的 MySQL Router 实例当前无法在那里发送任何流量。本例中的报告应用程序不需要报告本地数据中心何时离线,但如果应用程序仍需要运行,MySQL 路由器实例的路由选项应更改为遵循主路由或向布鲁塞尔集群发送流量。
要为主要 InnoDB 集群执行紧急故障切换,请执行以下步骤:
-
使用 MySQL Shell, 使用 InnoDB Cluster 管理员帐户(使用
cluster.setupAdminAccount()创建)连接到 InnoDB ClusterSet 部署中仍处于活动状态的任何成员服务器。您也可以使用 InnoDB Cluster 服务器配置帐户,该帐户也具有所需的权限。建立连接后,使用
dba.getClusterSet()或cluster.getClusterSet()命令从该成员服务器获取 ClusterSet 对象。以前从现在脱机的成员服务器检索的 ClusterSet 对象将不再工作,因此需要从联机的服务器再次获取该对象。使用 InnoDB Cluster 管理员帐户或服务器配置帐户非常重要,以便存储在 ClusterSet 对象中的默认用户帐户具有正确的权限。例如:mysql-js> \connect admin2@127.0.0.1:4410 Creating a session to 'admin2@127.0.0.1:4410' Please provide the password for 'admin2@127.0.0.1:4410': ******** Save password for 'admin2@127.0.0.1:4410'? [Y]es/[N]o/Ne[v]er (default No): Fetching schema names for autocompletion... Press ^C to stop. Closing old connection... Your MySQL connection id is 71 Server version: 8.0.27-commercial MySQL Enterprise Server - Commercial No default schema selected; type \use <schema> to set one. <ClassicSession:admin2@127.0.0.1:4410> mysql-js> myclusterset = dba.getClusterSet() <ClusterSet:testclusterset> ``` -
使用 MySQLShell 中 AdminAPI 的
clusterSet.status()函数检查整个部署的状态。使用扩展选项查看问题的确切位置和内容。例如:mysql-js> myclusterset.status({extended: 1})有关输出的说明,请参阅 第 8.6 节 “InnoDB ClusterSet 的状态和拓扑” 。
-
InnoDB 集群可以容忍一些问题,并且运行良好,可以继续作为 InnoDB ClusterSet 部署的一部分。当您使用
clusterSet.status()命令检查运行正常的主集群时,它的全局状态为OK。 例如,如果集群中的一个成员服务器脱机,即使该服务器是主服务器,底层组复制技术也可以处理这种情况并重新配置自己。如果根据报告的状态,主集群在 InnoDB ClusterSet 部署中仍能正常运行,但您需要进行维护或修复一些小问题以改进主集群的功能,则可以进行受控切换到副本集群。然后,如果需要,您可以使主集群离线,修复任何问题,并使其在 InnoDB ClusterSet 部署中重新运行。有关此操作的说明,请参阅 第 8.7 节 “InnoDB ClusterSet 的受控切换” 。
-
如果主集群在 InnoDB ClusterSet 部署中运行不正常(全局状态为
NOT_OK), 但您可以联系它,首先尝试通过 MySQL Shell 使用 AdminAPI 修复任何问题。例如,如果主集群已失去法定人数,则可以使用cluster.forceQuorumUsingPartitionOf命令恢复它。有关此操作的说明,请参阅 第 8.9 节“ InnoDB ClusterSet 的修复和重新加入” 。 -
如果无法执行受控切换,并且无法通过使用主集群快速解决问题(例如,因为无法联系主集群),请继续执行紧急故障切换。首先确定一个合适的副本集群,它可以作为主集群来接管。副本集群的紧急故障切换资格取决于其全局状态,如
clusterSet.status()命令所报告的:表 8.2 允许的集群操作(按状态)
ClusterSet 内的 InnoDB Cluster 全局状态 是否可路由 受控切换 紧急故障切换 OK 是 是 是 OK_NOT_REPLICATING 是,如果使用名称指定目标集群 是 是 OK_NOT_CONSISTENT 是,如果使用名称指定目标集群 否 是 OK_MISCONFIGURED 是 是 是 NOT_OK 否 否 否 INVALIDATED 是,如果使用名称指定目标集群并且设置 accept_ro路由策略否 否 UNKNOWN 已连接的MySQL路由器实例可能仍在将流量路由到该集群 否 否 您选择的副本集群必须具有所有可访问的副本集群中最新的事务集( GTID 集)。如果有多个副本集群符合紧急故障切换条件,请检查每个集群的复制延迟(这在
clusterSet.status()命令的扩展输出中显示)。选择复制延迟最少的副本集群,因此它应该具有最多的事务。紧急故障转移过程检查当前可访问的所有副本集群的 GTID 集,并告诉另一个集群是否更为最新,以便您可以使用该集群重试。 -
当连接到 InnoDB ClusterSet 部署中的任何成员服务器时,通过在 MySQL Shell 中执行
clusterSet.routingOptions()命令,检查为每个 MySQL Router 实例设置的路由选项以及 InnoDB ClusterSet 部署的全局策略。例如:mysql-js> myclusterset.routingOptions() { "domainName": "testclusterset", "global": { "invalidated_cluster_policy": "drop_all", "target_cluster": "primary" }, "routers": { "Rome1": { "target_cluster": "primary" }, "Rome2": {} } }如果所有 MySQL 路由器实例都设置为遵循主集群(
"target_cluster": "primary"), 则流量将在故障切换后几秒内自动重定向到新的主集群。如果没有为 MySQL Router 实例显示路由选项,如上面针对 Rome2 的“target_cluster”示例所示,这意味着该实例没有该策略集,而是遵循全局策略。如果将任何实例设置为按名称(
"target_cluster": "name_of_primary_cluster") 将当前主集群作为目标,则它们不会将流量重定向到新的主集群。当主集群不工作时,clusterSet.setRoutingOptions()命令不能用于更改路由选项,因此在故障切换到新的主集群之前,您无法重定向该 MySQL 路由器实例处理的流量。 -
如果可以,请尝试验证原始主集群是否处于脱机状态,如果处于联机状态,请尝试将其关闭。如果它保持在线并继续接收来自客户端的流量,则可能会出现脑裂的情况,即 InnoDB ClusterSet 的分离部分发生分歧。
-
要继续进行紧急故障转移,请执行
clusterSet.forcePrimaryCluster()命令,指定要接管的副本集群为新的主集群。例如:mysql-js> myclusterset.forcePrimaryCluster("clustertwo") Failing-over primary cluster of the clusterset to 'clustertwo' * Verifying primary cluster status None of the instances of the PRIMARY cluster 'clusterone' could be reached. * Verifying clusterset status ** Checking cluster clustertwo Cluster 'clustertwo' is available ** Checking whether target cluster has the most recent GTID set * Promoting cluster 'clustertwo' * Updating metadata PRIMARY cluster failed-over to 'clustertwo'. The PRIMARY instance is '127.0.0.1:4410' Former PRIMARY cluster was INVALIDATED, transactions that were not yet replicated may be lost.在
clusterSet.forcePrimaryCluster()命令中:- clusterName 参数是必需的,它指定用于 InnoDB ClusterSet 中副本集群的标识符,如
clusterSet.status()命令的输出所示。在本例中,clustertwo 是要成为新主集群的集群。 - 如果要执行验证并记录更改而不实际执行,请使用
dryRun选项。 - 使用
invalidateReplicaClusters选项来指定任何无法访问或不可用的副本集群。这些将在故障切换过程中标记为无效。如果在此过程中发现了任何您未指定的不可访问或不可用的副本集群,则会取消故障切换。在这种情况下,您必须修复并重新加入副本集群,然后重试该命令,或者在重试该命令时指定其为该选项的值,然后稍后修复。 - 使用
timeout选项定义等待在集群的每个实例中应用挂起事务的最大秒数。确保GTID_EXECUTED具有最新的 GTID 集。默认值从dba.gtidWaitTimeout选项中检索。
当您执行
clusterSet.forcePrimaryCluster()命令时,MySQLShell 会检查目标副本集群是否符合接管主集群的要求,如果不符合,则返回错误。如果目标副本集群满足要求,MySQL Shell 将执行以下任务:
- 尝试联系当前主集群,如果确实可以联系到,则停止故障切换。
- 检查未使用
invalidateReplicaClusters指定的任何无法访问或不可用的副本集群,如果发现任何副本集群,则停止故障转移。 - 将
invalidateReplicaClusters中列出的所有副本集群标记为无效,并将旧的主集群标记为失效。 - 检查目标副本集群是否具有可用副本集群中的最新 GTID 集。 这涉及停止所有副本集群中的 ClusterSet 复制通道。
- 更新从以新的主集群作为目标集群、复制到所有副本集群上的 ClusterSet 复制通道。
- 在 ClusterSet 元数据中将目标集群设置为主集群,并将旧的主集群更改为副本集群,尽管它当前未作为副本集群运行,因为它被标记为无效。
在紧急故障切换期间,MySQL Shell 不会尝试将目标副本集群与当前主集群同步,也不会锁定当前主集群。如果原始主集群保持联机,则应在联系到它后立即关闭。
- clusterName 参数是必需的,它指定用于 InnoDB ClusterSet 中副本集群的标识符,如
-
如果您有任何 MySQL 路由器实例要切换到新的主集群,请立即切换。您可以将它们更改为跟随主集群(
"target_cluster": "primary"), 或指定已作为主集群来接管的副本集群("target_cluster": "name_of_new_primary_cluster")。 例如:mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'primary') 或 mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'clustertwo') Routing option 'target_cluster' successfully updated in router 'Rome1'.
执行 clusterSet.routingOptions() 命令,检查所有 MySQL 路由器实例现在是否正确路由。
-
使用扩展选项再次执行
clusterSet.status()命令,以验证 InnoDB clusterSet 部署的状态。 -
如果您能够再次联系旧的主集群,请首先确保没有应用程序流量被路由到该集群,然后使其脱机。然后按照 第 8.9 节“ InnoDB ClusterSet 的修复和重新加入” 中的流程检查事务并决定如何安排 InnoDB ClusterSet 拓扑结构。
在发生紧急故障切换后,如果 ClusterSet 的各个部分之间存在事务集不同的风险,则必须保护集群不受写入流量或所有流量的影响。有关详细信息,请参阅 隔离 InnoDB ClusterSet 中的集群 。
如果您必须在切换过程中使任何副本集群失效,并且当您能够再次联系它们时,您可以使用第 8.9 节“ InnoDB ClusterSet 的修复和重新加入” 中的过程来修复它们并将它们添加回 InnoDB ClusterSet。

















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











