







文章目录
一、前言
本文创作之初是在学习李海翔所著的《分布式数据库原理、架构与实践》,因该书内容存在错误,故而去查找了其引用的 《ANSI SQL-92 标准》1、《A Critique of ANSI SQL Isolation Levels》2、《Generalized Isolation Level Definitions》3 (以上三本参考文献被很多研究学者在进行事务隔离级别、数据异常方面研究时普遍引用),以及同样是李海翔所著的《数据库事务处理的艺术:事务管理与并发控制》。在查资料过程中,又参阅了 TiDB 在知乎上的相关文章《事务前沿研究 | 隔离级别的追溯与究明,带你读懂 TiDB 的隔离级别(上篇)》 及 《事务前沿研究 | 隔离级别的追溯与究明,带你读懂 TiDB 的隔离级别(下篇)》 ,还有阿里云开发者社区的文章 《A Critique of ANSI SQL Isolation Levels 论文翻译》 及 《数据库必知词汇:SQL标准》。
本文的文章结构遵循各研究文献的发表顺序,意图通过理清各研究在真实世界的演进过程、研究目的和解决的问题,来更清晰地突显研究背后的发展逻辑与前人的智慧。
如若只想了解要点知识,请参阅我的另一篇文章 《【数据库理论】事务、数据异常与隔离级别(精华版)》 。


二、简介研究的演进过程
本文参考及级联参考的研究文献顺序按时间先后顺序总结如下:
- 《On the Notions of Consistency and Predicate Locks》4 为 [NC&PL]5 的先行发布版本,发布于 1974 年。
- 《Granularity of Locks and Degrees of Consistency in a Shared Data Base》6,发表于 1976 年,主要参考了 **[ONC&PL]4 ,在该文章第三部分结合现有的数据管理系统进行讨论时又参考了 [IMS/VS]7 、 [DMS1100]8 两篇文档。
- 《ANSI SQL-92 标准》1 基于 [GL&DC]6 中的工作成果和 《An Introduction to Database Systems》9 提出的一些改进,对 SQL 相关概念给出了规范定义,其目标是开发一个 “独立于实现”( Implementation-independent) 的标准。在此之前,还有一个发布于 1986 年的 《ANSI SQL-86 标准》 。
- 《An Introduction to Database Systems》9 第五版发行于 1990 年,被 5. 和 6. 中的文档引用,作者为数据库领域的名人 C. J. Date ,第一版不详,不知是否 [ANSI SQL]1 是否参考了它。
- 《A Critique of ANSI SQL Isolation Levels》2 发表于 1995 年,基于 [ANSI SQL]1 对其模糊的定义做了批评,并给出了一套新的定义,还参考了 [CC&Rcv]10 [TDBCC]11 [DBPPP]12 [TPCT13 等资料。
- 《Generalized Isolation Level Definitions》3 发表于 2000 年,也是基于 [ANSI SQL]1 和 [C-ANSI]2 进行了改进,对现象、隔离级别等相关概念给出更通用、准确的定义,以达到 [ANSI SQL]1 “独立于实现”的设计初衷。
一般其他类似的文章出于只关注事务的数据异常和隔离级别方面知识的动机,而只参考研究 《ANSI SQL-92 标准》1、《A Critique of ANSI SQL Isolation Levels》]2、《Generalized Isolation Level Definitions》3 这三篇文章的递进式发展关系,对它们参考的其他文章未做研究。
三、一致性级别与锁机制
《Granularity of Locks and Degrees of Consistency in a Shared Data Base》6 首次 以 一致性级别(Degrees of Consistency) 为名引入了 隔离级别(Isolation Levels) 的概念。该著作的目标是通过牺牲对完全隔离性的保障来提高工作负载的并发性。[GL&DC]6 中的工作成果和 《An Introduction to Database Systems》9 提出的一些改进为 ANSI/ISO SQL-92 对隔离级别定义1 奠定了基础。
该文献第一部分“锁的粒度”介绍了层级锁、锁的访问模式和兼容性、锁图(有向无环图,DAG)、动态锁图(动态有向无环图)、调度、锁转换、死锁和锁抖动等。第二部分“一致性级别”介绍了一致性级别,并给出了三种定义。第三部分结合当时现有的数据管理系统 [IMS/VS]7** 、 **[DMS1100]8 进行讨论。
本节仅讨论其第二部分“一致性级别”内容。
[GL&DC]6 定义了 4 种一致性级别:0 、1、2、3 级 ,其中 3 级 等同于 可序列化(Serializability) 。
关于数据项、事务、历史、事件等的符号表示说明
- 数据项 :使用“
单字符+下标”的形式表示,单字符为 x 、y 、z 等。- 事务 :使用 “
T+下标”的形式表示。- 事件 :即读、写、提交、中断操作,分别使用 “
事件对应的单字符+下标” 的形式表示,后可能接圆括号等扩展形式,后文介绍,此处不加赘述。- 历史 :使用 “
H+下标”的形式表示。- 下标 :既可以是数字,也可以是字母、单词。
3.1 定义 1 :一致性的非正规定义
定义 1 是一种业务上的、直观的定义,用于向用户描述系统行为。
先非正规地介绍一个概念:
- “脏(Dirty)”:**“未提交(Uncommitted)”**状态。脏数据(Dirty Data) 即表示未提交的事务中已写入的数据。
使用 “脏数据” 的概念,一致性级别可以定义为:
“定义1” :
- 3 级:满足以下要求,则称事务 T 具有(原文为 “sees”,笔者认为应翻译为“确保”) 3 级的一致性:
- (a)T 不覆写其他事务的脏数据
- (b)T 在完成所有写入之前不提交任何写入,例如,直到事务结束(the End of Transaction,简写为 EOT)
- (c)T 不从其他事务读取脏数据
- (d)其他事务在T 完成之前不弄脏 T 读取的任何数据- 2 级:满足以下要求,则称事务 T 具有 2 级一致性:
- (a)T 不覆写其他事务的脏数据
- (b)T 在 EOT 之前不提交任何写入
- (c)T 不读取其他事务的脏数据- 1 级:满足以下要求,则称事务 T 具有 1 级一致性:
- (a)T 不覆写其他事务的脏数据
- (b)T 在 EOT 之前不提交任何写入- 0 级:满足以下要求,则称事务 T 具有 0 级的一致性:
- (a)T 不覆写其他事务的脏数据
注意,如果一个事务满足一个高级别的一致性,则它也满足所有更低级别的一致性。
小注 1
到这里,笔者认为,没有问题。1 级一致性可以防止 P0 脏写 现象。但该作者们后面的解释却产生了问题,[C-ANSI]2 中指出作者们因这一方面的定义而持续受到批评。只有那些基于历史和依赖图或锁的更为数学化的定义经受住了时间的考验。
原文后面的解释:
- 0 级一致性事务在事务结束前提交了写入。因此, 回滚一个 0 级一致性事务可能需要撤销对被另一个事务锁定的一个实体的更新。在这种情况下, 0 级事务是不可恢复的。
- 1 级一致性事务直到事务结束才提交写入。因此,可以撤销一个进行中的事务而无需设置额外的锁。这意味着撤销事务不会清除其他事务的更新。这是数据管理系统自动向所有事务提供 1 级一致性的主要原因。
- 2 级一致性将事务与其他事务未提交的数据隔离。使用 1 级 一致性事务可能读取后面可能更新或撤销的未提交的值。
- 3 级一致性将事务与值之间的脏关系隔离。读是 可重复的(Reapeatable)。例如,一个 2 级一致性的事务,如果它对同一个实体读取两次,可能读取两个不同的已提交的值。这是因为一个更新实体的事务可能开启、更新、结束在两次读取间的时间间隔。如果一个事务在读取一个实体后又更新了它,或涉及多个实体可能发生更多由并发导致的复杂类型的 异常(Anomalies)。3 级一致性将事务完全与因并发导致的不一致性隔离。
3.2 定义 2 :一致性的锁协议定义
定义 2 是一种基于锁协议的、程序上的定义,用于解释系统实现。
锁协议 先对锁进行了分类:
- 按并发事务间允许的访问模式分:
- 共享锁,又叫 读锁
- 排它锁 ,又叫 写锁
- 按锁的持续时间分:
- 短期锁:单个原子操作期间持有的锁,在该操作完成后立即释放。
- 长期锁:持有直到事务结束(提交或中止)的锁。
锁协议 为:
定义 2 :
- 3 级:如果满足以下条件,则称事务 T 遵循 3 级锁协议:
- (a)T 在任何它弄脏的数据上设置长期排它锁。
- (b)T 在任何它读取的数据上设置长期共享锁。- 2 级:如果满足以下条件,则称事务 T 遵循 2 级锁协议:
- (a)T 在任何它弄脏的数据上设置长期排它锁。
- (b)T 在任何它读取的数据上设置(可能是短期的)共享锁。- 1 级:如果满足以下条件,则称事务 T 遵循 1 级锁协议:
- (a)T 在任何它弄脏的数据上设置长期排它锁。- 0 级:如果满足以下条件,则称事务 T 遵循 0 级锁协议:
- (a)T 在任何它弄脏的数据上设置(可能是短期的)排它锁。
锁协议可以使用如下概念更简洁地表述:
- 如果一个事务在写入(读取)一个实体前总是先以排他(共享)模式锁定它,则称这个事务是 对写入(读取)格式良好的(Well-Formed) 。
- 如果该事务对读取和写入都是格式良好的,则称该事务是格式良好的 。
一个事务在解锁某个实体前不会在另一个实体上施加(共享或排他)锁,则称这个事务在读取或更新(写入)方面是 两阶段的(Two-Phase) 。
基本的可序列化定理是,格式良好的两阶段锁 保证了可序列化——在两阶段锁协议下产生的每个历史都相当于某个串行历史。反之,如果一个事务不是格式良好的或两阶段的,除退化情况外,可能发生不可序列化执行的历史。
从一致性不会要求一个事务持有所有锁直到 EOT (例如 EOT 是收缩(Shrinking)阶段)来看,定义 2 过于限制性。相反,约束事务必须是两阶段的来确保一致性是合格的。另一方面,一旦事务解锁了一个已更新的实体。它已提交了那个实体,所以它无法被撤销,而不会级联还原任何其他可能随后读取该实体的事务。因此,收缩阶段通常推迟到事务结束;从而,事务总是可恢复的,并且所有更新一起提交。锁协议可以重定义为:
定义 2’:
- 3 级:满足以下条件:
- T 是格式良好的
- T 是两阶段的。- 2 级:满足以下条件:
- T 是格式良好的
- T 在写入方面是两阶段的。- 1 级:满足以下条件:
- T 在写入方面是格式良好的
- T 在写入方面是两阶段的。- 0 级:满足以下条件:
- T 在写入方面是格式良好的
所有的事务要求遵循 0 级 锁协议以使它们不会更新其他事务的更新。1 、2 、3 级 提供持续增强的系统保证(System-Guaranteed)一致性。
3.3 定义 3 :一致性的正式定义
定义 3 是一种基于系统操作轨迹的定义,用于正式地陈述和证明不同一致性级别的属性。
定义 3 :
如果一个事务 T 在调度 S 中满足 0(1、2、3) 级 一致性,则称事务 T 在调度 S 中以 0(1、2、3) 级一致性运行。反过来,如果所有合法的调度以 i 级一致性运行事务 T ,则称事务 T 满足 i 级一致性。如果所有事务在调度 S 中以 0(1、2、3) 级一致性运行,则称调度 S 为一个 0(1、2、3) 级一致性的调度。
小结 1
至此,对 [GL&DC]6 的摘要结束。相信你也可以看出,这篇文章在措辞、语言表述、概念定义方面确实存在不足,“sees”、“observes”、“back up”等词汇很晦涩难以翻译理解,与当今这些词的含义存在差别。
四、《ANSI SQL-92 标准》1 定义的现象与隔离级别
4.1 ANSI (ISO/IEC) SQL 标准简介
SQL 标准 是由国际标准化组织(ISO)、**美国国家标准委员会(ANSI)**等制定的,对数据库管理系统的统一操作方式。
SQL 是 Structured Query Language 的缩写,规范的发音是 “[ˌɛsˌkjuːˈɛl]”。但是它的前身是著名的关系数据库原型系统 System R 所采用的 SEQUEL 语言,这也是为什么有很多人将其读作 “[ˈsiːkwəl]” 的来源。也有人类比 GNU 这个词的定义(GNU’s Not UNIX),认为 SQL 是 SQL Query Language 的缩写。
IBM 对关系数据库以及 SQL 语言的形成和规范化产生了重大的影响,第一个版本的 SQL 标准 SQL-86就是基于System R 的手册而来的。Oracle 在1979 年率先推出了支持 SQL 的商用产品。随着数据库技术和应用的发展,为不同 RDBMS 提供一致的语言成了一种现实迫切的需求。
对SQL标准影响最大的机构自然是那些著名的数据库产商,而具体的制订者则是一些非营利机构,例如国际标准化组织(ISO)、美国国家标准委员会(ANSI) 等。各国通常会按照 ISO 标准和 ANSI 标准制定自己的国家标准。
“美国国家标准化组织(ANSI)” 是一个核准多种行业标准的组织。SQL 作为关系型数据库所使用的标准语言,最初是基于 IBM 的实现在 1986 年被批准的。1987 年,“国际标准化组织(ISO)” 把 ANSI SQL 作为国际标准。
SQL发展的简要历史:
1986年,ANSI X3.135-1986,ISO/IEC 9075:1986,SQL-86 。
1989年,ANSI X3.135-1989,ISO/IEC 9075:1989,SQL-89 。
1992年,ANSI X3.135-1992,ISO/IEC 9075:1992,SQL-92(SQL2) 。
1999年,ISO/IEC 9075:1999,SQL:1999(SQL3) 。
2003年,ISO/IEC 9075:2003,SQL:2003 。
2008年,ISO/IEC 9075:2008,SQL:2008 。
2011年,ISO/IEC 9075:2011,SQL:2011 。
2016 年,ISO/IEC 9075:2016,SQL:2016 。
2023 年,ISO/IEC DIS 9075,仍在开发中。
补充说明:
1986 年,ANSI X3.135-1986,ISO/IEC 9075:1986,SQL-86。这是 ANSI 首次将 SQL 语言标准化的版本。
1989 年,ANSI X3.135-1989,ISO/IEC 9075:1989,SQL-89。增加了完整性约束。
1992 年,ANSI X3.135-1992,ISO/IEC 9075:1992,SQL-92(SQL2)。最重要的一个版本。 引入了标准的分级概念。
1999 年,ISO/IEC 9075:1999,SQL:1999(SQL3)。变动最大的一个版本。改变了标准符合程度的定义;增加了面向对象特性、正则表达式、存储过程、Java 等支持。
2003 年,ISO/IEC 9075:2003,SQL:2003。引入了 XML、Window 函数等。
2008 年,ISO/IEC 9075:2008,SQL:2008。引入了 TRUNCATE 等。
2011 年,ISO/IEC 9075:2011,SQL:2011。引入了时序数据等。
2016 年,ISO/IEC 9075:2016,SQL:2016。引入了 JSON 等。
绝大多数人提起 SQL 标准,涉及的内容其实是 《ANSI SQL-92 标准》1 里头最基本或者说最核心的一部分。《ANSI SQL-92 标准》1 本身是分级的,包括入门级、过渡级、中间级和完全级,推荐泛读 《ANSI SQL-92 标准》1,补充阅读其他标准。而随着 SQL 标准 的发展,其包含的内容实在太多了,而且有很多特性对新的SQL产品而言也越来越不重要了。从 SQL-99 之后,标准中符合程度的定义就不再分级,而是改成了核心兼容性和特性兼容性;也没有机构来推出权威的 SQL 标准 符合程度的测试认证了。
[ANSI SQL]1 中的 4 个隔离级别和 3 个被禁止的操作结果(称为 “现象(Phenomena)”)是采用经典的 “可串行化(Serializability)” 定义(即 2.1 节中提到的那些概念和知识,[C-ANSI]2 中有详细介绍)所定义的。
[ANSI SQL]1 中对(SQL-事务)的隔离级别的定义是基于现象的,即先发现现象,然后依据现象定义隔离级别。
4.2 ANSI SQL 定义的现象
[ANSI SQL]1 定义了三种应该被禁止的现象:
- P1 (“脏读”):事务 T 1 T_1 T1 修改了一行(数据项,Data Item)。事务 T 2 T_2 T2 稍后在事务 T 1 T_1 T1 执行
COMMIT提交前读取了该行。如果 T 1 T_1 T1 稍后执行了ROLLBACK回滚操作, T 2 T_2 T2 将读取到一个从未提交过的行,因此该行可能被认为从未存在过。 - P2(“不可重复读”,后又称为“模糊读(Fuzzy Read)”):事务 T 1 T_1 T1 读取一行。事务 T 2 T_2 T2 稍后修改或删除了该行并执行
COMMIT提交。如果 T 1 T_1 T1 稍后尝试重新读取该行,它可能接收到修改后的值或发现该行已经被删除了。 - P3(“幻读”):事务 T 1 T_1 T1 读取一个满足一些查询条件
<search condition>的行集 N 。事务 T 2 T_2 T2 稍后执行 SQL 语句生成了满足 T 1 T_1 T1 所使用的查询条件<search condition>要求的一行或多行记录。如果事务 T 1 T_1 T1 稍后使用相同的查询条件<search condition>重复最初的读取,它将获取到不同的行集。
4.3 ANSI SQL 定义的隔离级别
隔离级别 定义了该 SQL-事务中对 SQL-数据或方案的操作受并发 SQL-事务中的对 SQL-数据或方案的操作影响的程度,并且可以影响并发 SQL-事务对SQL数据和方案的操作。简言之,事务隔离级别的操作对象是 SQL-数据或方案,被参照事务是当前事务,参照事务是其他并发事务,隔离级别定义了当前事务对某些数据或方案的操作,与其他并发事务对某些数据或方案的操作,二者之间相互影响的程度。
《ANSI SQL-92 标准》1 引文
4.28 SQL-transactions
An SQL-transaction has an isolation level that is READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, or SERIALIZABLE. The isolation level of an SQL-transaction defines the degree to which the operations on SQL-data or schemas in that SQL-transaction are affected by the effects of and can affect operations on SQL-data or schemas in concurrent SQL-transactions. The isolation level of a SQL-transaction is SERIALIZABLE by default. The level can be explicitly set by the <set transaction statement>.
The execution of concurrent SQL-transactions at isolation level SERIALIZABLE is guaranteed to be serializable. A serializable execution is defined to be an execution of the operations of concurrently executing SQL-transactions that produces the same effect as some serial execution of those same SQL-transactions. A serial execution is one in which each SQL-transaction executes to completion before the next SQL-transaction begins.
The isolation level specifies the kind of phenomena that can occur during the execution of concurrent SQL-transactions. The following phenomena are possible:
- P1 (“Dirty read”): SQL-transaction T 1 T_1 T1 modifies a row. SQL-transaction T 2 T_2 T2 then reads that row before T 1 T_1 T1 performs a COMMIT. If T 1 T_1 T1 then performs a ROLLBACK, T 2 T_2 T2 will have read a row that was never committed and that may thus be considered to have never existed.
- P2 (“Non-repeatable read”): SQL-transaction T 1 T_1 T1 reads a row. SQL-transaction T 2 T_2 T2 then modifies or deletes that row and performs a COMMIT. If T 1 T_1 T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted.
- P3 (“Phantom”): SQL-transaction T 1 T_1 T1 reads the set of rows N that satisfy some <search condition>. SQL-transaction T 2 T_2 T2 then executes SQL-statements that generate one or more rows that satisfy the <search condition> used by SQL-transaction T 1 T_1 T1. If SQL-transaction T 1 T_1 T1 then repeats the initial read with the same <search condition>, it obtains a different collection of rows.
The four isolation levels guarantee that each SQL-transaction will be executed completely or not at all, and that no updates will be lost. The isolation levels are different with respect to phenomena P1, P2, and P3.
表-0 显示了给定隔离级别是否可能出现某个现象(P1、P2、P3)。
表-0 ANSI SQL 给出的隔离级别和 3 种现象
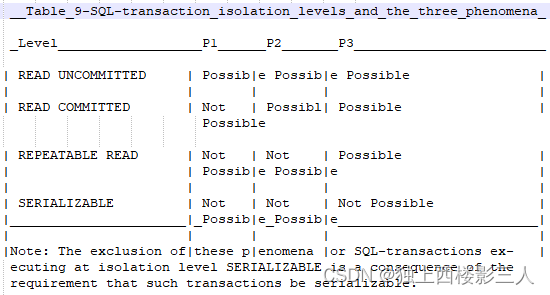
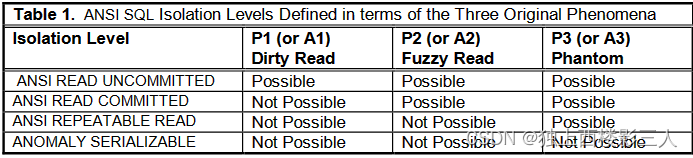
表-1 为 [C-ANSI]2 修正的 ANSI SQL 隔离级别的定义和现象的关系表。后文会做具体分析。
基于现象定义的 ANSI SQL 隔离级别以 “ANSI” 为前缀。
表-1 根据三种原始现象定义的 ANSI SQL 隔离级别2
五、《A Critique of ANSI SQL Isolation Levels》2 的重新定义
5.1 事务、锁、历史和依赖图
《A Critique of ANSI SQL Isolation Levels》2 对 《ANSI SQL-92 标准》1 对现象和隔离级别的模糊定义进行了批评,并指出 事务和锁 概念在文献 [CC&Rcv]10 、[TDBCC]11 、[DBPPP]12 、[TPCT]13 中有很好的记录。[C-ANSI]2 总结并称它们为 “可序列化(Serializability)概念” 。[C-ANSI]2 中简要介绍了这些术语,具体如下:
- 事务(Transaction) 是一系列将数据库从一个一致性状态转换为另一个一致性状态的操作的集合。历史(History) 将一组事务的交错执行建模为其操作的线性顺序,例如特定数据项的读取和写入(即插入、更新和删除)。如果历史中的两个操作是在同一数据项上的不同事务执行的,并且其中至少有一个是写入操作,则称历史中的这两个操作 冲突(Conflict)。在 [NC&PL]5 之后,该定义对 “数据项(Data Item)” 进行了广义解释:它可以是一个表行、一个页面、整个表或一个队列上的消息。冲突的操作既可能发生单个数据项上,也可能发生在由 谓词锁(Predicate Lock) 保护的一组数据项上。
- 特定的历史会产生一个 依赖图(Dependency Graph) ,定义事务之间的时序数据流。历史中已提交事务的操作表示为图 节点(Nodes)。如果事务 T 1 T_1 T1 的操作 o p 1 op_1 op1 在历史中与发生在其之前的事务 T 2 T_2 T2 的操作 o p 2 op_2 op2 冲突,则这对 < o p 1 op_1 op1, o p 2 op_2 op2> 形成依赖图中的 边(Edges)。如果两个历史具有相同的已提交事务和相同的依赖图,则它们是等效的。如果一个历史与一个 串行(Serial) 历史等价,即,如果它与在序列中一次执行一个事务的某个历史具有相同的依赖图(跨事务(Inter-Transactional) 时序数据流),则称该历史是 可串行(序列)化(Serializable) 的。
[C-ANSI]2 将 ANSI SQL 定义的 3 个数据异常中的“行”替换为“数据项”以使表述更清晰,区分于谓词条件。它还指出这三个数据异常不会出现在串行历史中。因此,根据可序列化理论,它们也不会出现在可串行化历史中。
由读取、写入、提交、中断组成的历史可以使用以下简短形式规范表示:
H表示某一历史。- 操作的符号定义包括:
r即 read,表示读;w即 write,表示写;c即 commit,表示提交;a即 abort ,表示中断;rc即 read cursor ,表示读取游标;wc即 write cursor , 表示写入游标。
- 操作后的下标数字表示事务标识。
- 紧接着的是一对方括号(“[]”)。
- 方括号内出现的是表达式,表达式可以是数据项,谓词,或数据项、谓词和值组成的表达式。
例如, w 1 w_1 w1[x] 表示 事务 1 在 数据项 x 上的写操作; r 2 r_2 r2[x] 表示 事务 2 对 x 的读操作。事务 1 读取和写入满足 谓词 P 的一组数据项分别表示为 r 1 r_1 r1[P] 和 w 1 w_1 w1[P] 。事务 1 的提交和中断分别表示为 c 1 c_1 c1 和 a 1 a_1 a1 。
5.2 重新定义的现象与隔离级别
而后,该文献又基于此给出了 P1 ~ P3 现象 的广义和狭义解释,对 “现象” 作出更正式的定义、说明,并修订了其他文献中 “异常” 定义模糊的问题,区分了 “现象” 与 “异常” :
- “现象(Phenomena)” : P 1 P_1 P1, P 2 P_2 P2 … P n P_n Pn 。现象的广义解释,表示可能导致异常的现象。
- “异常(Anomaly)” : A 1 A_1 A1, A 2 A_2 A2 … A n A_n An 。现象的严格解释,表示真实的异常。
然后,该文献给出了 P1 ~ P3 现象 的广义和狭义解释:
- P1 : w 1 w_1 w1[x]… r 2 r_2 r2[x]…(( c 1 c_1 c1 or a 1 a_1 a1) and ( c 2 c_2 c2 or a 2 a_2 a2) in any order)
A1 : w 1 w_1 w1[x]… r 2 r_2 r2[x]…( a 1 a_1 a1 and c 2 c_2 c2 in any order) - P2 : r 1 r_1 r1[x]… w 2 w_2 w2[x]…(( c 1 c_1 c1 or a 1 a_1 a1) and ( c 2 c_2 c2 or a 2 a_2 a2) in any order)
A2 : r 1 r_1 r1[x]… w 2 w_2 w2[x]… c 2 c_2 c2… r 1 r_1 r1[x]… c 1 c_1 c1 - P3 : r 1 r_1 r1[P]… w 2 w_2 w2[y in P]…(( c 1 c_1 c1 or a 1 a_1 a1) and ( c 2 c_2 c2 or a 2 a_2 a2) any order)
A3 : r 1 r_1 r1[P]… w 2 w_2 w2[y in P]… c 2 c_2 c2… r 1 r_1 r1[P]… c 1 c_1 c1
该文献接着给出了 多值历史(Multi-Valued History ,简写为 “MV-History”) 的概念。在一个 多版本(Multi-Version) 系统中可能同时存在一个数据项的多个版本。任何读取必须明确要读取哪个版本。有人试图将 ANSI 隔离定义与多版本系统以及更常见的使用标准锁调度器的 单版本(Single-Version) 系统联系起来。上文 P1、P2 和 P3 现象 的英文表述暗示了使用的是单版本的历史。
注意 [ANSI SQL-92]1 P3 的英文表述仅阻止了对谓词的插入,但定义 P3 的本意是“一旦谓词已被读取则禁止任何对满足谓词条件的元组(Tuple)的写入操作(INSERT、UPDATE 和 DELETE)”。对应的 ANSI SQL SERIALIZABLE 隔离级别的英文表述也存在类似的问题,它的本意是“在该隔离级别下的事务并发执行的结果完全等价于串行执行的结果”,排除了所有的不一致性,即 “完全可序列化” 。而后面给出的 表-0 相较于附加限制条件更为突出,导致了 一个普遍的误解:“阻止了这 3 种现象即实现了可序列化” 。究其本质,是 ANSI SQL 表述不准确导致其目标与描述出现偏差,“完全可序列化” 即要求排除所有会导致不一致性的现象,而这些现象几乎难以穷尽,当时只发现并定义了 3 种现象,后面随着技术的发展,又发现的新的现象,因而 “完全可序列化” 是无法实现的。
因此,[C-ANSI]2 将 “SERIALIZABLE” 前加上 “ANOMALY”,称禁止了 3 种现象的隔离级别为 “ANOMALY SERIALIZABLE” ,以 表-1 的形式重新生成了 表-0 。
采用 P1、P2、P3 的广义解释,可使隔离级别的定义更具限制性,也就是说,可以禁止更多的现象。可即便如此,禁止这些现象也无法确保真正的可序列化。所以,[C-ANSI]2 接着介绍了锁机制,并更简要、准确地总结了一些锁机制概念:
- 谓词锁:在所有满足给定
<search condition>的数据项上施加的有效锁。谓词锁的锁定范围可能是无限的集合。它既包含数据库中现存的数据,又包含任何当前不在数据库中、但可能因未来插入、或更新现有数据项以满足给定谓词条件<search condition>的幻读数据项。在 SQL 术语中,谓词锁覆盖了所有满足谓词的元组,以及任何因执行INSERT、UPDATE或DELETE语句而导致满足谓词的元组。 - 项目锁(记录锁) :是一种谓词为某一特定数据项的特殊谓词锁。
- 格式良好的写入(读取):Well-Formed Writes (Reads) ,相对于 [GL&DC]6 中的 “Well-Formed with respect to writes (reads)” 。
表-2 根据锁定义了一些根据 加锁范围(项(items)或谓词(predicates))、模式(读 或 写)和其持续时间(短 或 长)定义的隔离级别。作者们认为 Locking READ UNCOMMITTED、 Locking
READ COMMITTED、 Locking REPEATABLE READ、Locking SERIALIZABLE 是 ANSI SQL 隔离级别 想要的锁定义,但如下所示它们与 表-1 的那些完全不同。 因此,有必要区分基于锁定义的隔离级别 和 ANSI SQL 基于现象的隔离级别。为了进行这种区分,表-2 中的级别标有 “Locking” 前缀,对应于 表-1 的 “ANSI” 前缀。 [GL&DC]6 定义了 0 级一致性 ,以允许脏读和脏写:它只要求操作原子性。 1、2 和 3 级 对应于 Locking READ UNCOMMITTED*、 Locking READ COMMITTED 和 Locking SERIALIZABLE 。Locking READ UNCOMMITTED 提供了长期写入锁定,以避免称为 “脏写” 的现象,但除了 ANSI SERIALIZABLE 之外,ANSI SQL 无法阻止这种异常行为。此外,没有与 Locking REPEATABLE READ 对应的隔离级别。
隔离级别的符号表示 定义如下:

在比较隔离级别时,我们仅根据不可序列化的历史来区分它们,这些历史可以出现在一个隔离级别中,但不能出现在另一个隔离等级中。两个隔离级别在允许的可序列化历史方面也可能有所不同。尽管众所周知锁调度器没有允许所有可能的可串行化历史,仍认为 Locking SERIALIZABLE == SERIALIZABLE 。
表-2 基于锁定义的一致性级别和加锁隔离级别
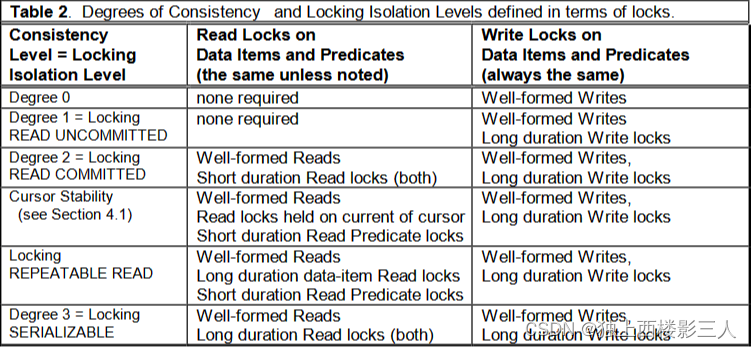
表-2 中基于锁协议定义的锁定隔离级别至少和 表-1 中相应的基于现象的隔离级别一样强。因此,锁定隔离级别至少和同名的 ANSI 隔离级别的隔离程度一样。Locking READ UNCOMMITTED 提供长期写锁来防止叫做“脏写”的现象,但 ANSI SQL 只有 SERIALIZABLE 隔离级别能防止“脏写”现象。
[C-ANSI]2 在 ANSI SQL 给出的 3 个数据异常之外,提出了几个新的 “现象” 和 “异常” 。
-
P0(“脏写”) :事务 T 1 T_1 T1 修改数据项。然后,另一个事务 T 2 T_2 T2 在 T 1 T_1 T1 执行
COMMIT或ROLLBACK之前进一步修改该数据项。如果 T 1 T_1 T1 或 T 2 T_2 T2 随后执行ROLLBACK,则无法确定正确的数据值应该是什么。P0 的广义解释为:
P0 : w 1 w_1 w1[x]… w 2 w_2 w2[x]…(( c 1 c_1 c1 or a 1 a_1 a1) and ( c 2 c_2 c2 or a 2 a_2 a2) in any order) -
P4(丢失更新) :当事务 T 1 T_1 T1 读取数据项,然后 T 2 T_2 T2 更新数据项(可能基于先前的读取),然后 T 1 T_1 T1(基于其先前的读取值)更新数据项并提交时,发生丢失更新异常。
以历史的方式表述为:
P4(丢失更新) : r 1 r_1 r1[x]… w 2 w_2 w2[x]… w 1 w_1 w1[x]… c 1 c_1 c1例如下面的历史 H 4 H_4 H4 所描述的问题,即使 T 2 T_2 T2 提交, T 2 T_2 T2 的更新也会丢失。
H 4 H_4 H4 : r 1 r_1 r1[x=100] r 2 r_2 r2[x=100] w 2 w_2 w2[x=120] c 2 c_2 c2 w 1 w_1 w1[x=130] c 1 c_1 c1
x 的最终值仅包含由事务 T 1 T_1 T1 增加的 30 ,即x 的最终值为 130 。
P4 可能发生于 READ COMMITTED 隔离级别,因为当禁止 P0 或 P1 时,允许发生 H 4 H_4 H4 。而 禁止 P2 时,也会禁止 P4 ,因为 w 2 w_2 w2[x] 发生于 r 1 r_1 r1[x] 后和事务 T 1 T_1 T1 提交或回滚前。因此,异常 P4 有助于区分 READ COMMITTED 和 REPEATABLE READ 之间中等强度的隔离级别。
-
P4C(游标丢失更新): 类似于 P4 ,但影响弱于 P4,丢失更新发生于游标,而未必发生于数据项。
以历史的方式表述为:
P4C(游标丢失更新): r c 1 rc_1 rc1[x]… w 2 w_2 w2[x]… w 1 w_1 w1[x]… c 1 c_1 c1 -
A5(“违反数据项约束”) :假设
C()是数据库中的两个数据项 x 和 y 之间的数据库约束,有两个因违反约束引起的异常:-
A5A(读倾斜,Read Skew) :假设事务 T 1 T_1 T1 读取 x , 然后第二个事务 T 2 T_2 T2 更新 x 和 y 为新值并提交。如果现在 T 1 T_1 T1 读取 y ,它可能查看到一个不一致状态,并因此产生一个不一致状态作为输出。
使用历史形式表示为:
A5A(读倾斜) : r 1 r_1 r1[x]… w 2 w_2 w2[x]… w 2 w_2 w2[y]… c 2 c_2 c2… r 1 r_1 r1[y]…( c 1 c_1 c1 or a 1 a_1 a1) -
A5B(写倾斜,Write Skew) :假设事务 T 1 T_1 T1 读取 x 和 y ,它们与
C()一致,然后一个事务 T 2 T_2 T2 读取 x 和 y ,写入 x ,然后提交。接着, T 1 T_1 T1 写入 x 。如果 x 和 y 之间存在一个约束,则违反了该约束。使用历史形式表示为:
A5B(写倾斜) : r 1 r_1 r1[x]… r 2 r_2 r2[y]… w 1 w_1
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5905
5905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











