







论文:
Mask CTC: Non-Autoregressive End-to-End ASR with CTC and Mask Predict
摘要:
提出了MASK CTC(一种新型非自回归端到端语音识别框架),自回归(Autoregressive Translation , ART)模型需要用已生成的词来预测下一个位置的词,代价比较大,非自回归模型可以在恒定的迭代次数内同时生成标记,推理时间明显减少,本论文MASK CTC 是基于Transformer,预测屏蔽以及CTC联合训练的,在推理过程中,使用贪婪CTC初始化,将置信度低的屏蔽掉,掩码MASk由于标准CTC模型,
目前主流的神经机器翻译模型为自回归模型,每一步的译文单词的生成都依赖于之前的翻译结果,因此模型只能逐词生成译文,翻译速度较慢。Gu等人提出的非自回归神经机器翻译模型(NAT)对目标词的生成进行独立的建模,因此能够并行解码出整句译文,显著地提升了模型的翻译速度。然而,非自回归模型在翻译质量上与自回归模型有较大差距,主要表现为模型在长句上的翻译效果较差,译文中包含较多的重复词和漏译错误等。
非自回归(Non-autoregressive,NAR)模型并行生成序列的所有标记,与自回归(AR)模型相比,生成速度更快,但代价是准确性较低。在神经机器翻译(neural machine translation,NMT)、自动语音识别(automatic speech recognition,ASR)和语音合成(TTS)等不同的任务中,人们提出了包括知识提取和源-目标对齐在内的不同技术来弥补AR和NAR模型之间的差距。在这些技术的帮助下,NAR模型可以在某些任务中赶上AR模型的准确性,但在其他任务中则不能。
引言
端到端神经网络和基于隐马尔可夫模型的系统差不多,在机器翻译中已经证明非自回归模型的有效性,我们的工作旨在获得一种非自回归的端到端ASR模型,该模型以较低的计算成本生成令牌级别的序列。提出的Mask CTC框架使用CTC和Mask预测目标来训练Transformer编码器-解码器模型。在推断过程中,目标序列会用贪婪的CTC输出初始化,并根据CTC概率屏蔽低置信度标记。掩盖的低置信度令牌被预测为不仅在过去而且在将来的情况下都以高置信度令牌为条件。 Mask CTC的优点总结如下。不需要预测输出长度:从输入语音预测输出令牌的长度非常具有挑战性,因为输入发声的长度会根据讲话速度或静音时间而变化很大。通过使用CTC输出初始化目标序列,Mask CTC不必担心在解码开始时预测输出长度。准确且快速的解码:我们观察到CTC输出本身的结果非常准确。掩码CTC不仅在CTC输出中保留正确的令牌,而且还通过考虑整个上下文来恢复输出错误。带有少量掩码的令牌级迭代解码使该模型非常适合实际场景中的使用。
框架
Attention-based encoder-decoder
CTC(Connectionist temporal classification)
CTC引入一个<blank> 一般为0的token来实现输入序列X和输出序列Y的帧对齐,在[1][2]中都引入了CTC和attention混合训练的办法


从上图可以看出,CTC嵌入在encoder和decoder之中,将置信度低的mask掉,通过decoder在推测真正的值
CMLM对输入序列X和未屏蔽的令牌来预测mask掉的令牌
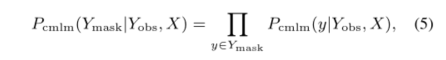
将原始CMLM应用于非自回归语音识别显示出较差的性能,存在跳过和重复输出令牌的问题。为了解决这个问题,我们发现类似于[8]的CTC联合训练为模型提供了明确的绝对位置信息(条件独立性),并合理地改善了模型性能。与等式中的CTC目标有关。针对非自回归ASR模型的CTC-CMLM联合训练的目标定义如下:

实验


应用encoder-decoder架构,
- Transformer self-attention 使用4 attention head,256 hidden units
- feed-forward 2048
- 12 self-attention encoder,6 self-attention docoder,在encoder之前使用CNN,进行特征提取,下采样
- MASK CTC model 需要更多epoch
- CTC在attention和CTC模型中占比
=0.3,以及在CTC和mask CTC 之中也占比
=0.3(the loss weights λ and γ in Eq.
(4) and Eq. (6) were set to 0.3 and 0.3, respectively.) - MASK CTC在以字符本身就是一个特定的单词中对CER效果不大
参考文献
- S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017.
- S. Karita, N. E. Y . Soplin, S. Watanabe, M. Delcroix, A. Ogawa,and T. Nakatani, “Improving Transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration,” in Proceedings of Annual Confer-ence of the International Speech Communication Association (IN-
TERSPEECH), 2019
















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









