







论文:
ASAPP-ASR: Multistream CNN and Self-Attentive SRU for SOTA Speech Recognition
摘要:
两种新颖的神经网络架构Multistream CNN(声学模型),slef-Attentive SRU(语言模型),在混合ASR框架中,多流CNN声学模型在多个并行管线中处理语音帧的输入,其中每个流具有唯一的扩容速率以实现分集,使用一些数据增强的方法训练,在Librispeech数据集test-clean,test-other分别有4%以及14%的个提升,加入语言模型后,得到进一步提升
在test-clean中WER为1.75%,在test-other中wer为4.46%是一个新的SOTA。
引言
讲了端到端语音识别系统的发展,LAS,CNN-RNN-Transducer等模型实现的结果,受[20]启发但没有多头自我注意层的多流CNN声学模型,在多个并行管线中处理输入语音帧,其中每个流对于CNN的卷积核具有唯一的扩张率,以实现多样性。经过SpecAugment的培训,它在测试清洁方面的相对WER改善了4%,在其他测试方面达到了14%。我们使用24层自关注SRU语言模型通过N最佳记录来进一步提高性能。在[30]中提出了SRU,用于递归计算中的更高并行化。我们的变体在原始SRU上增加了自注意力,不仅可以替代计算中的某些线性运算,而且还可以增强上下文建模功能。一旦使用由Kaldi工具包训练的TDNN-LSTM语言模型进行重新评分,我们便重新计算了网格的N个最佳输出[31,32]。在两个测试集上,自我专注的SRU LM的平均相对WER改善约为23%
模型架构

这种新颖的神经网络架构可在多个流中适应不同的时间分辨率,以实现鲁棒性。对于不同的时间分辨率,它考虑了TDNN-F(一维CNN的变体)上特定于流的膨胀率。每个流堆叠较窄的TDNN-F层,当并行处理输入语音帧时,它们的内核具有唯一的扩展速率。从默认子采样率(3帧)的倍数中选择每个流中TDNN-F层的扩散率。这提供了与训练和解码过程的无缝集成,其中对输入语音帧进行了二次采样。借助SpecAugment,多流CNN可以提供更高的鲁棒性,以应对具有挑战性的音频,例如LibriSpeech中的“其他”设备。
声学模型:
以单流方式放置5层2D CNN,我们将3x3内核用于2D CNN,滤波器大小为256,第一层为128,每个流使用17个TDNN-F,该嵌入矢量通过网络末端的几个完全连接的层投影在输出层上。我们采用3-6个扩张配置为6-9-12的流,其中3个流的TDNN-F层的扩展速率分别为6、9和12。
语言模型
语言模型使用[30]提出的SRU 架构,一个单层SRU计算如下:

相比LSTM以及GRU,SRU可以达到更快的训练速度,SRU的变种在[33][34][35]都取得了很好的效果
实验
数据集:Librispeech

self-attentive SRU LMs:学习率2x10-4,优化器RAdam ,schedule,使用余弦退火学习速率,隐藏层:2048,自注意力层512
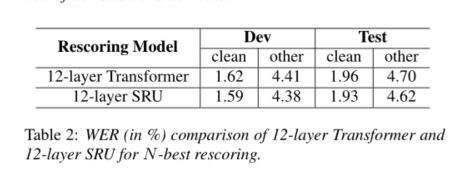

在这项工作中,我们提出了一种混合ASR系统,该系统结合了新颖的声学模型架构,多流CNN和有效的语言模型,自专心的SRU。通过对LM评分的多个阶段以及对N个最佳假设进行重新排名的预期单词错误最小化,我们在流行的语音基准测试中获得了关于测试清洁度和竞争性测试性能的最新结果图书馆。通过多流CNN在多流体系结构中进行多分辨率处理,证明了它对test other的鲁棒性,而SRU的自我关注型则证明了其建模能力优于Transformer。我们将继续通过有效使用深层CNN架构以及在培训中进一步优化数据增强方法来提高声学模型的鲁棒性。凭借自我专注的SRU在语言建模中提出的令人鼓舞的结果,我们还计划在端到端ASR的框架中在声学建模中利用SRU的类似建模能力
参考文献
[20] K. J. Han, R. Prieto, and T. Ma, “State-of-the-art speech recognition using multi-stream self-attention with dilated 1D convolution,” in ASRU, 2019, pp. 54–61
[29] K. J. Han, J. Pan, V . K. N. Tadala, T. Ma, and D. Povey, “Multistream CNN for robust acoustic modeling,” in Interspeech, 2020,in review
[30] T. Lei, Y . Zhang, S. I. Wang, H. Dai, and Y . Artzi, “Simple recur-rent units for highly parallelizable recurrence,” in EMNLP, 2018.
[33] J. Park, Y . Boo, I. Choi, S. Shin, and W. Sung, “Fully neural net-work based speech recognition on mobile and embedded devices,”in NeurIPS, 2018, pp. 10 620–10 630.
[34]Y . Shangguan, J. Li, Q. Liang, R. Alvarez, and I. McGraw, “Optimizing speech recognition for the edge,” 2019, [Online]. Avail-able: https://arxiv.org/abs/1909.12408
[35]T. Koriyama and H. Saruwatari, “Utterance-level sequential mod-eling for deep Gaussian process based speech synthesis using sim-ple recurrent unit,” ICASSP, 2020.
















 5002
5002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









