






一、通过Selenium模拟登录淘宝
模拟登录这块我粘贴的下面这位大哥的,为了记录我爬虫的过程所以我复制了这位大哥的部分文章selenium爬取淘宝评论信息_为什么py的sele爬取淘宝客服的聊天记录-CSDN博客
1、分析淘宝登录页面
现在要获取淘宝的商品信息需要先登录淘宝。我们先来分析淘宝的登录页面。
淘宝登录页面为https://login.taobao.com/member/login.jhtml,支持扫描登录和用户名、密码验证登录。我们模拟用户名、密码登录。
通过Chrome浏览器输入淘宝登录页面链接F12打开开发者工具,分析淘宝登录页的源代码,找到登录账号、登录密码和登录按钮的相关控件的源代码
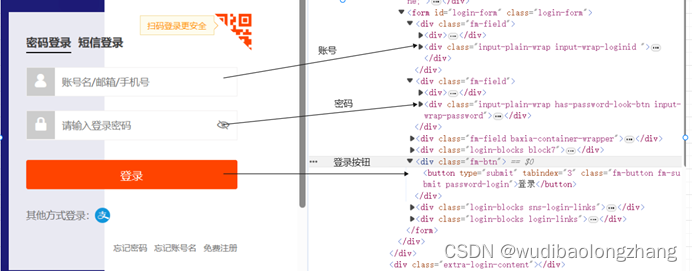
在这里可以看到
账号名的输入框控件代码:<div class="input-plain-wrap input-wrap-loginid "><input name="fm-login-id" type="text" class="fm-text" id="fm-login-id" tabindex="1" aria-label="账号名/邮箱/手机号" placeholder="账号名/邮箱/手机号" autocapitalize="off"></div>
登录密码的输入框控件代码:<div class="input-plain-wrap has-password-look-btn input-wrap-password"><input name="fm-login-password" type="password" class="fm-text" id="fm-login-password" tabindex="2" aria-label="请输入登录密码" placeholder="请输入登录密码" maxlength="40" autocapitalize="off"><div class="password-look-btn"><i class="iconfont icon-eye-close"></i></div></div>
登录按钮的控件代码:<button type="submit" tabindex="3" class="fm-button fm-submit password-login">登录</button>
2、通过Selenium实现模拟登录代码
代码如下:
# 模拟淘宝登录
def login_taobao():
print('开始登录...')
try:
login_url='https://login.taobao.com/member/login.jhtml'
driver.get(login_url)
input_login_id = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
input_login_password = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-password')))
input_login_id.send_keys('你的账号') # 用你自己的淘宝账号替换
input_login_password.send_keys('你的密码') # 用你自己的密码替换
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit.password-login')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
return is_loging
except TimeoutException:
print('login_taobao TimeoutException')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
if is_loging:
return is_loging
else:
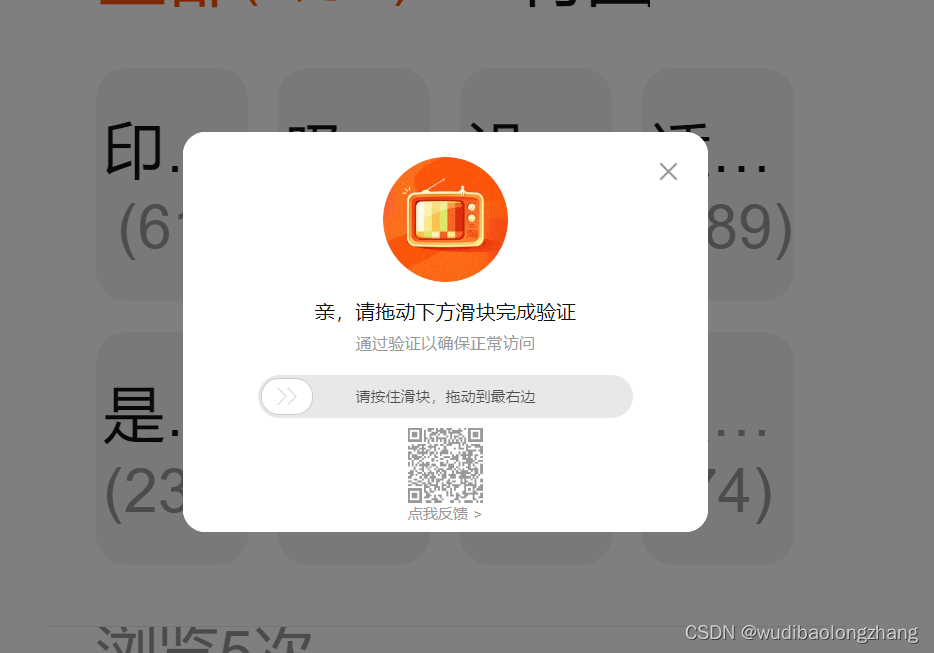
login_taobao()找到登录需要用的的这几个关键控件代码都就可以开始编码来控制这些控件进行模拟操作了运行代码后可以看到程序自动的调起了一个Chrome浏览器并访问了淘宝的登录页面,自动的输入了用户淘宝账号和密码,自动的点击了登录按钮,但出现了一个滑动验证的控件,要求滑动验证。人工拖动滑动验证控件,显示验证失败。
3、Selenium接管已经运行的Chrome浏览器
1)启动Chrome的远程调试模式
通过
chrome.exe --remote-debugging-port=9222 --user-data-dir='某个存在的文件夹地址' 启动Chrome的远程调试模式,启动一个Chrome浏览器。
找到chrome的安装目录,找到chrome.exe ,通过cmd命令行执行上面的命令。

运行上面命令后,就会弹出一个chrome浏览器,这个浏览器是可以被Selenium来接管操作的。
2)代码中实现接管已经运行的Chrome浏览器
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import TimeoutException
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "localhost:9222") #此处端口保持和命令行启动的端口一致
driver = Chrome(options=chrome_options)
wait = WebDriverWait(driver, 10)
# 模拟淘宝登录
def login_taobao():
print('开始登录...')
try:
login_url='https://login.taobao.com/member/login.jhtml'
driver.get(login_url)
input_login_id = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
input_login_password = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-password')))
input_login_id.send_keys('你的账号') # 用你自己的淘宝账号替换
input_login_password.send_keys('你的密码') # 用你自己的密码替换
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit.password-login')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
return is_loging
except TimeoutException:
print('login_taobao TimeoutException')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
if is_loging:
return is_loging
else:
login_taobao()
if __name__ == '__main__':
is_loging=login_taobao()
if is_loging:
print('已经登录')
3)运行效果
运行上述代码就可以看到,Selenium接管了这个通过Chrome的远程调试模式启动的浏览器,并自动输入用户名和密码,自动登录成功,跳转到我的淘宝界面。
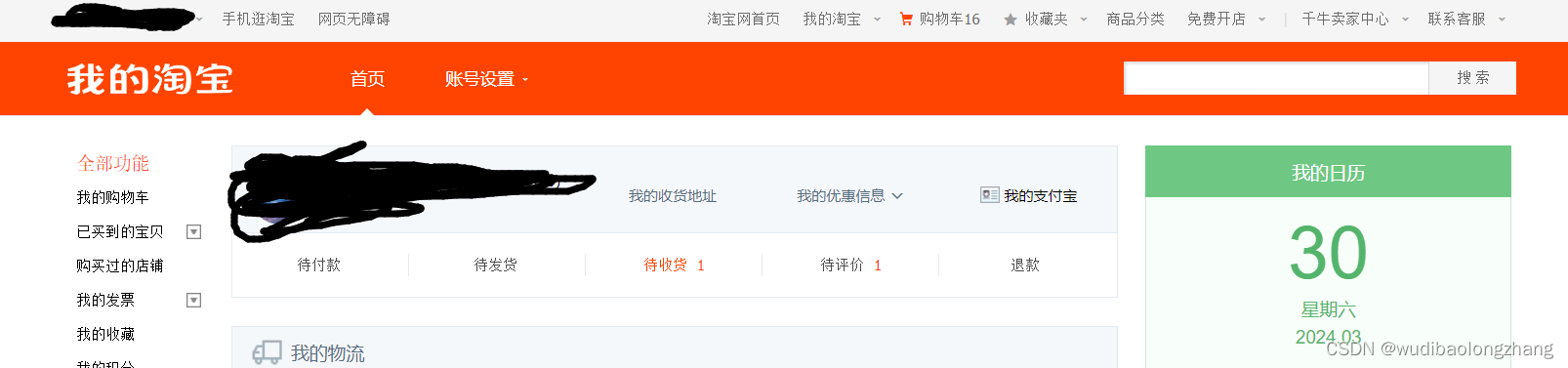
二、爬取淘宝商品评论
1、查看评论页面并分析
登录之后得先知道你想爬哪款商品的评论,我这边随便来了个抽纸的商品https://m.tb.cn/h.5yMtRbw?tk=KRdEWLCHwYs,点开评论后发现需要在手机上才可以看到更多评论
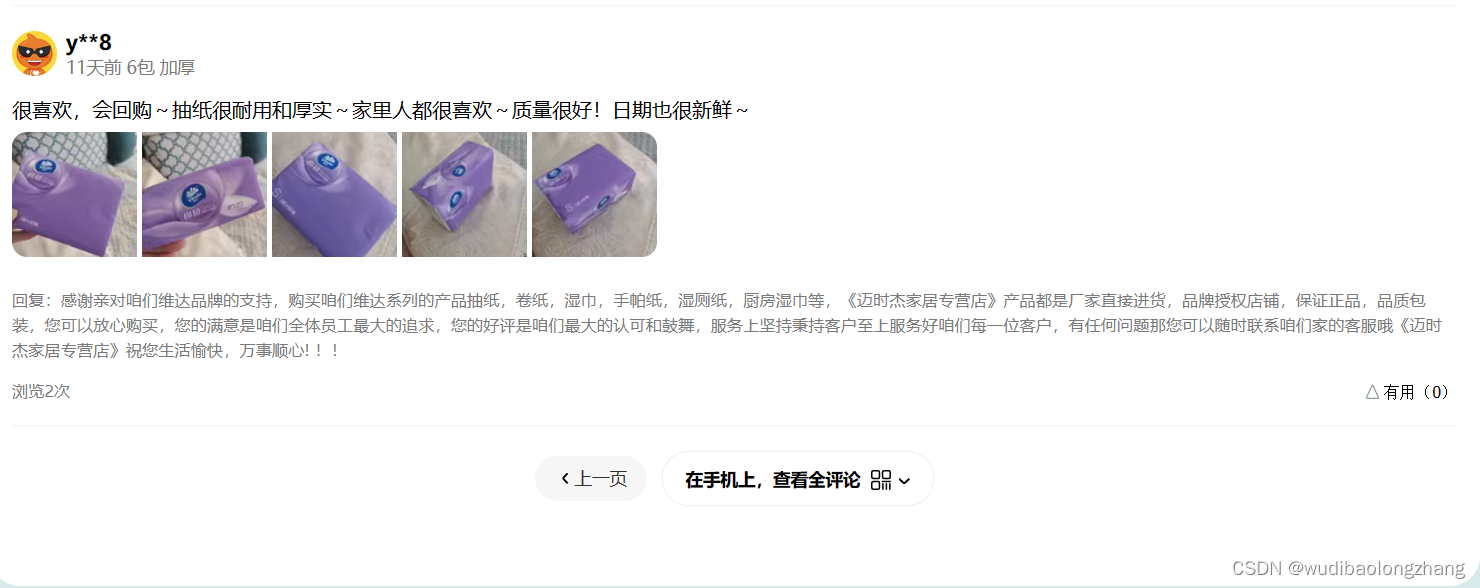
于是我打开了手机的浏览器扫描了二维码,发现可以打开网页也可以看到更多的评论
我将手机扫码后的二维码在电脑浏览器上也可以打开,下面是手机上打开的链接
https://main.m.taobao.com/detail/index.html?id=654387017938&spm=pc_detail.27183998.0.0
效果如下:

F12打开开发者工具
发现评论在这个里面
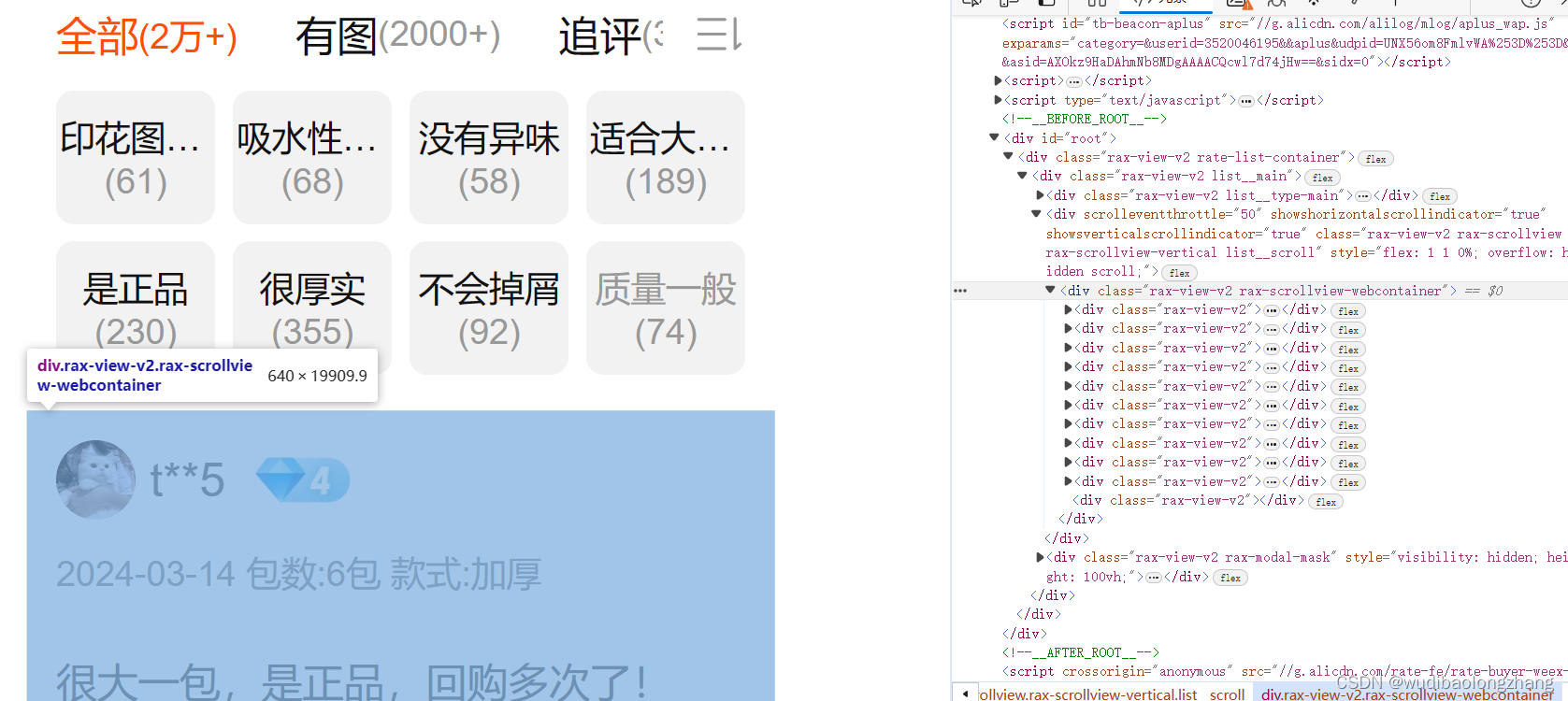
发现通过翻页评论的数量会变多
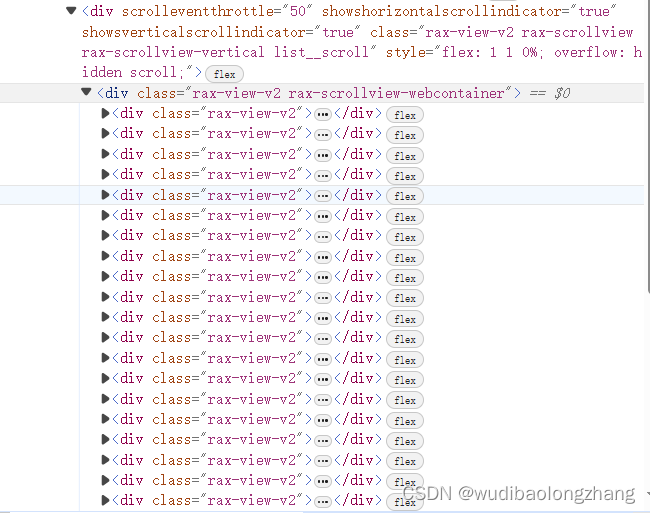
下面是相应的代码实现:
driver.get('https://main.m.taobao.com/detail/index.html?id=654387017938&spm=pc_detail.27183998.0.0')
time.sleep(3) # 等待页面加载出来可以根据需要调整等待时间
# 定位要点击的按钮
button = driver.find_element(By.XPATH, "//span[text()='查看全部']")
# 使用 JavaScript 来点击按钮
driver.execute_script("arguments[0].click();", button)
for _ in range(60):
# 循环滚动页面六十次可以自己调整
for _ in range(20):
# 定位到要滚动到的元素
element_to_scroll_to = driver.find_element(By.XPATH, "//*[@id='root']/div/div/div[2]/div")
# 使用 JavaScript 执行滚动到元素的操作,将元素滚动到视图的底部
driver.execute_script("arguments[0].scrollIntoView(false);", element_to_scroll_to)
# 等待一段时间以确保滚动完成
time.sleep(2) # 可以根据需要调整等待时间如果翻页太快可能需要你自己手动验证一下,可以调节睡眠时间避免这个问题,也可以自己动手验证
点开其中一个评论详情并找到自己想要的信息
用户名:<div class="rax-view-v2 user__info"><span class="rax-text-v2 user__name">t**5</span><img class="rax-image user__credit-image" src="https://img.alicdn.com/imgextra/i4/O1CN01ZlCYMx1nbVriw6u0S_!!6000000005108-2-tps-92-45.png"></div>
购买的物品类别:<span class="rax-text-v2 card__sku">2024-03-14 包数:6包 款式:加厚</span>
评论:<span class="rax-text-v2 card__content">很大一包,是正品,回购多次了!</span>
追评:<span class="rax-text-v2 card__append-rate-content">用起来很柔软,纸质相对于这个价位来说我觉得是我买的纸里最好的!</span>
代码部分:
# 获取包含特定 class 属性的元素列表
elements_to_get_value = driver.find_elements(By.XPATH, "//*[@class='rax-view-v2']")
# 存储所有元素信息的列表
detailed_review = []
# 遍历元素列表并获取每个元素的文本内容
for i_item in elements_to_get_value:
# 获取用户名
user_name_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 user__name']")
user_name_texts = [elem.text for elem in user_name_elements]
# 获取产品 SKU
card__sku_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__sku']")
card__sku_texts = [elem.text for elem in card__sku_elements]
# 获取评论内容
card__content_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__content']")
card__content_texts = [elem.text for elem in card__content_elements]
# 获取追加评价内容
card__append_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__append-rate-content']")
# 检查是否找到追加评价内容元素
if card__append_elements:
card__append_texts = [elem.text for elem in card__append_elements]
else:
card__append_texts = '' # 如果没有找到,将追加评价内容为空
# 使用 zip_longest 函数将对应的信息组合成元组,并添加到 detailed_review 列表中
from itertools import zip_longest
for user, sku, content, append in zip_longest(user_name_texts, card__sku_texts, card__content_texts, card__append_texts):
detailed_review.append({
"user_name": user,
"card__sku": sku,
"card__content": content,
"card__append": append
})
2、运行结果展示
效果如下图:
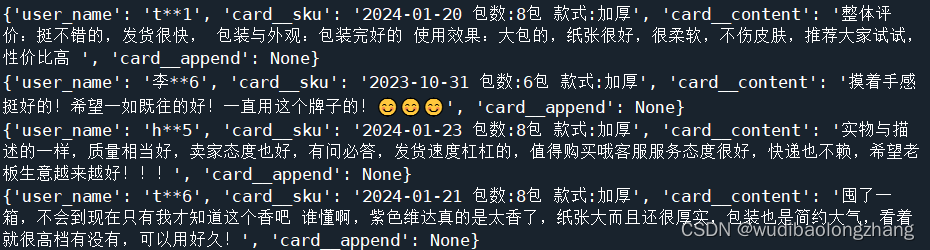
将结果保存入csv文件
# CSV 文件路径
csv_file_path = "reviews.csv"
# 写入 CSV 文件,使用 GBK 编码
with open(csv_file_path, mode='w', newline='', encoding='GBK', errors='ignore') as file:
# 定义 CSV 文件的表头
fieldnames = ['user_name', 'card__sku', 'card__content', 'card__append']
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 遍历 detailed_review 列表,并写入数据到 CSV 文件
for review in detailed_review:
writer.writerow(review)打开文件显示爬取了九百来条数据,还是不错的

附上全部完整代码:
from selenium.webdriver import Chrome
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import csv
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "localhost:9222") #此处端口保持和命令行启动的端口一致
driver = Chrome(options=chrome_options)
wait = WebDriverWait(driver, 10)
# 模拟淘宝登录
def login_taobao():
print('开始登录...')
try:
login_url='https://login.taobao.com/member/login.jhtml'
driver.get(login_url)
input_login_id = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
input_login_password = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-password')))
input_login_id.send_keys('你的账号') # 用你自己的淘宝账号替换
input_login_password.send_keys('你的密码') # 用你自己的密码替换
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit.password-login')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
return is_loging
except TimeoutException:
print('login_taobao TimeoutException')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
if is_loging:
return is_loging
else:
login_taobao()
if __name__ == '__main__':
is_loging=login_taobao()
if is_loging:
print('已经登录')
driver.get('https://main.m.taobao.com/detail/index.html?id=654387017938&spm=pc_detail.27183998.0.0')#这里可以换成你自己想爬取的商品链接
time.sleep(3) # 等待页面加载出来可以根据需要调整等待时间
# 定位要点击的按钮
button = driver.find_element(By.XPATH, "//span[text()='查看全部']")
# 使用 JavaScript 来点击按钮
driver.execute_script("arguments[0].click();", button)
for _ in range(60):
# 循环滚动页面六十次可以自己调整
for _ in range(20):
# 定位到要滚动到的元素
element_to_scroll_to = driver.find_element(By.XPATH, "//*[@id='root']/div/div/div[2]/div")
# 使用 JavaScript 执行滚动到元素的操作,将元素滚动到视图的底部
driver.execute_script("arguments[0].scrollIntoView(false);", element_to_scroll_to)
# 等待一段时间以确保滚动完成
time.sleep(2) # 可以根据需要调整等待时间
# 获取包含特定 class 属性的元素列表
elements_to_get_value = driver.find_elements(By.XPATH, "//*[@class='rax-view-v2']")
# 存储所有元素信息的列表
detailed_review = []
# 遍历元素列表并获取每个元素的文本内容
for i_item in elements_to_get_value:
# 获取用户名
user_name_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 user__name']")
user_name_texts = [elem.text for elem in user_name_elements]
# 获取产品 SKU
card__sku_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__sku']")
card__sku_texts = [elem.text for elem in card__sku_elements]
# 获取评论内容
card__content_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__content']")
card__content_texts = [elem.text for elem in card__content_elements]
# 获取追加评价内容
card__append_elements = i_item.find_elements(By.XPATH, ".//span[@class='rax-text-v2 card__append-rate-content']")
# 检查是否找到追加评价内容元素
if card__append_elements:
card__append_texts = [elem.text for elem in card__append_elements]
else:
card__append_texts = '' # 如果没有找到,将追加评价内容为空
# 使用 zip_longest 函数将对应的信息组合成元组,并添加到 detailed_review 列表中
from itertools import zip_longest
for user, sku, content, append in zip_longest(user_name_texts, card__sku_texts, card__content_texts, card__append_texts):
detailed_review.append({
"user_name": user,
"card__sku": sku,
"card__content": content,
"card__append": append
})
# CSV 文件路径
csv_file_path = "reviews.csv"
# 写入 CSV 文件,使用 GBK 编码
with open(csv_file_path, mode='w', newline='', encoding='GBK', errors='ignore') as file:
# 定义 CSV 文件的表头
fieldnames = ['user_name', 'card__sku', 'card__content', 'card__append']
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 遍历 detailed_review 列表,并写入数据到 CSV 文件
for review in detailed_review:
writer.writerow(review)















 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









