






前言
本人是才学完大数据的无业游民,我将会总结学习收获或发表自己的学习心得,期望给初学者也为自己今后复习提供一些帮助。
我将陆续发布大数据阶段所学,包括但不限于(hadoop,hive,hbase,phoneix,flume,bdeaver,kafka,spark,kylin,flink,azkaban)。
为了减少犯错,我在写下自己的博客时,会查阅官方文档或类似文章,也会将出处标记于文章末尾。
如果你是一名初学者,有学习问题可以联系我,或许你将做的决定和会犯的错我也经历过。我们互相督促,共同进步吧!
目录
一、引入
1.zookeeper是什么
- zookeeper是一个开源的分布式协调器,是一个典型的分布式数据一致性解决方案,其设计目的是将复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的系统,并以一系列简单易用的原子操作提供给用户使用。
- 它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
- 简单的说,zookeeper=文件系统+通知机制。
2.zookeeper能做什么
- 数据发布与订阅(配置中心)
- 分布式日志收集系统
- 负载均衡
- 命名服务(Naming Service)
- 分布式通知/协调
- 分布式锁
- 分布式队列
3.zookeeper优势是什么
- zookeeper对不同系统环境的支持都很好,在绝大多数主流的操作系统上都能够正常运行
- zookeeper的核心优势是,实现了分布式环境的数据一致性(也就是说,对zookeeper进行数据访问时,无论是什么时间,都不会引起脏读、重复读)
zookeeper提供的功能都是分布式系统中非常底层且必不可少的基本功能,如果开发者自己来实现这些功能而且要达到高吞吐、低延迟同时的还要保持一致性和可用性,实际上是非常困难的。因此,借助zookeeper提供的这些功能,开发者就可以轻松在zookeeper之上构建自己的各种分布式系统。
4.zookeeper历史
zookeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而zookeeper正好要用来进行分布式环境的协调一一于是,zookeeper的名字也就由此诞生了。
5.为什么要学zookeeper
套用zookeeper官网的话来说:ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services。
这大概描述了zookeeper主要是一个分布式服务协调框架,实现同步服务,配置维护和命名服务等分布式应用。是一个高性能的分布式数据一致性解决方案。通俗地讲,zookeeper是动物园管理员,它是拿来管大象 Hadoop、鲸鱼 HBase、Kafka等的管理员。
就像是建房时需要先打地基一样,我们学习大数据,zookeeper是首要也是必要学习的。
二、zookeeper详解
1.zookeeper角色分配

zookeeper有三种角色:
- Leader(领导者)
- Follower(跟随者)
- Observer(观察者)。其中,Follower和Observer归类为Learner(学习者)
按重要性排序是Leader > Follower > Observer
Leader
Leader在集群中只有一个节点,是zookeeper集群的中心,负责协调集群中的其他节点。从性能的角度考虑,leader可以选择不接受客户端的连接。
主要作用有:
- 发起与提交写请求。
所有的跟随者Follower与观察者Observer节点的写请求都会转交给领导者Leader执行。Leader接受到一个写请求后,首先会发送给所有的Follower,统计Follower写入成功的数量。当有超过半数的Follower写入成功后,Leader就会认为这个写请求提交成功,通知所有的Follower commit这个写操作,保证事后哪怕是集群崩溃恢复或者重启,这个写操作也不会丢失。
- 与learner保持心跳
- 崩溃恢复时负责恢复数据以及同步数据到Learner
Follower
Follow在集群中有多个,主要的作用有:
- 与Leader保持心跳连接
- 当Leader挂了的时候,投票选取新的leader。leader的重新选举是由各个Follower内部投票决定的。
- 向leader发送消息与请求
- 处理leader发来的消息与请求
Observer
Observer是zookeeper集群中最边缘的存在。Observer的主要作用是提高zookeeper集群的读性能。通过leader我们知道zookeeper的一个写操作是要经过半数以上的Follower确认才能够写成功的。那么当zookeeper集群中的节点越多时,zookeeper的写性能就越差。为了在提高zookeeper读性能(也就是支持更多的客户端连接)的同时又不影响zookeeper的写性能,zookeeper集群多了一个儿子Observer,只负责:
- 与leader同步数据
- 不参与leader选举,没有投票权。也不参与写操作的提议过程。
- 数据没有事务化到硬盘。即Observer只会把数据加载到内存。
下图是zookeeper官方文档中不同节点的zookeeper集群的性能表现(节点角色只有leader和follower):

竖轴是每秒请求量,横轴是读请求的占比,不同颜色的曲线代表了不同数量的zookeeper节点,分别是3个节点,5个节点,7个节点,9个节点,13个节点。
可以看到,随着读请求所占的比例越来越多,zookeeper所能处理的请求数量是指数级得提升。除了三个节点的zookeeper集群外,当读请求占比达到100%时,从曲线上看其他数量的集群能够处理的请求几乎无穷大。
当读请求达到80%时,由于follower数量的增大导致写请求的耗时增长,节点数量越多的zookeeper吞吐量越小(三个节点的集群是个例外)。吞吐量排序是:5>7>3>9>13。
正常情况下所有的请求都是读请求是不可能的,肯定含有写请求。所以建议zookeeper集群的读写比例为7:3或8:2最好,机器数量为5或者7台,不仅成本低也有良好的性能表现。
三、zookeeper伪集群搭建
zookeeper有三种运行模式:单机模式、伪集群模式和集群模式。
单机模式:这种模式一般适用于开发测试环境,一方面我们没有那么多机器资源,另外就是平时的开发调试并不需要极好的稳定性。
集群模式:一个 zookeeper集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 zookeeper集群了。组成 zookeeper集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
伪集群模式:这是一种特殊的集群模式,即集群的所有服务器都部署在一台机器上。当你手头上有一台比较好的机器,如果作为单机模式进行部署,就会浪费资源,这种情况下,zookeeper允许你在一台机器上通过启动不同的端口来启动多个 zookeeper服务实例,以此来以集群的特性来对外服务。
前提条件
1.安装VMware (详情请微信关注pc软件之家)
傻瓜式安装,不多说。
百度云链接:https://pan.baidu.com/s/1OefZVl79hxn61xFJDPlLAA
提取码:f9yx
迅雷云链接:https://pan.xunlei.com/s/VMdzzlvS6W5_1g8Uo5tvNl3kA1
提取码:698g
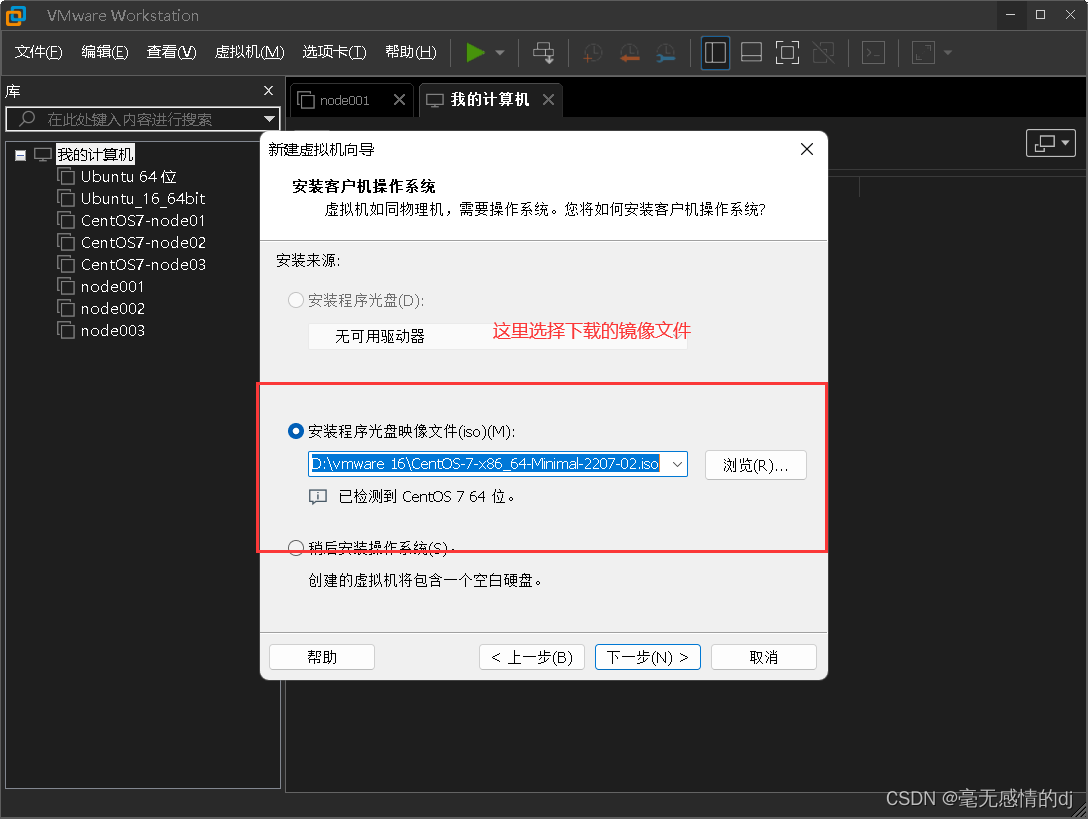
2.下载镜像文件CentOS-7-x86_64-Minimal-2207-02.iso(安装虚拟机需要用到)
3.安装Xshell
4.JDK下载(zookeeper集群需要安装jdk作为基础支持)
创建虚拟机并完成基础配置
1.创建虚拟机
这里已经有博主做了总结,不再累述。
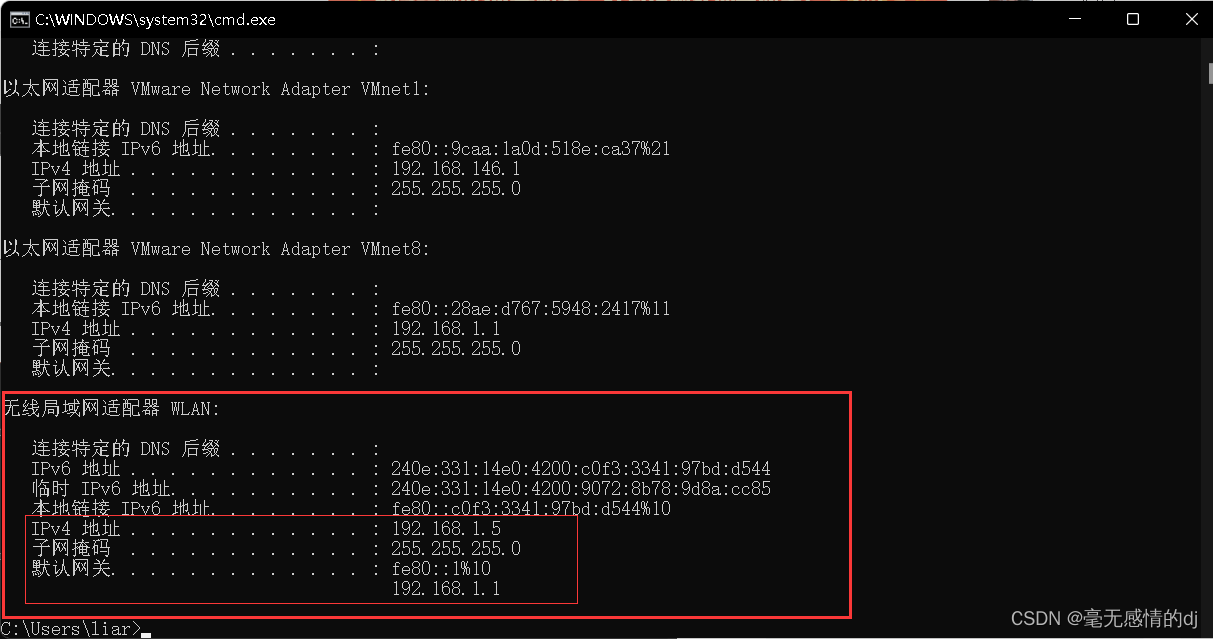
2.虚拟机网络设置
首先win+r输入cmd打开控制台
输入ipconfig得到本机的ip地址等信息。
现在返回VMware 点开左上角编辑-->虚拟网络编辑器
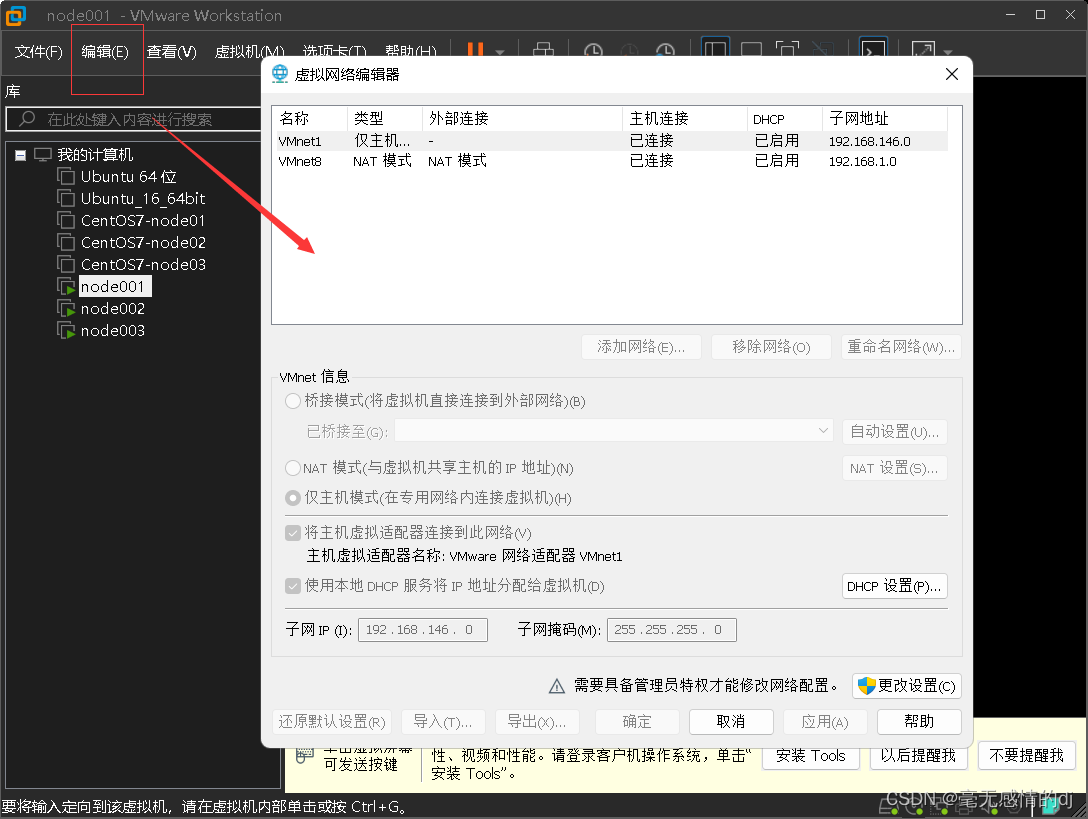
更改设置


接下来点击本窗口的NAT设置
修改网关
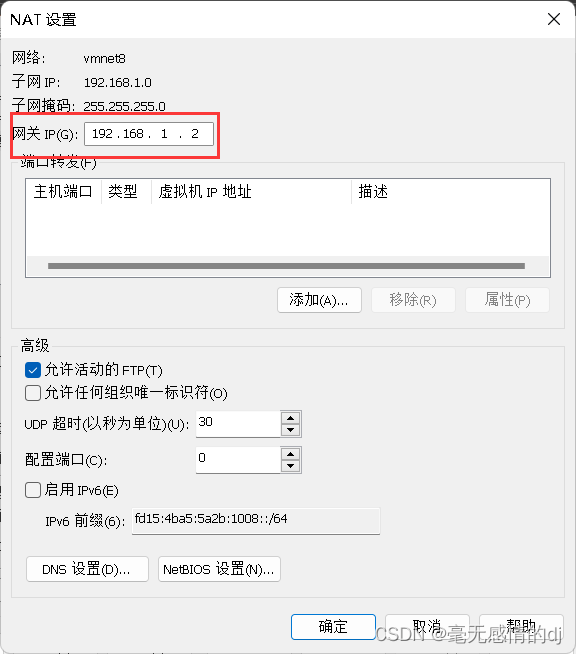
这些完成后开启虚拟机node001
控制台输入:vi /etc/sysconfig/network-scripts/ifcfg-ens33
将内容修改如下:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 改为静态
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
# 这里删除了UUIs
DEVICE=ens33
ONBOOT=yes # no改为yes,当机器重启时会重新加载这个网络配置文件
# 以下都为新增内容
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
NETMASK=255.255.255.0
DNS1=61.128.128.68 # 自己百度查询当地的dns号,我这里是重庆的#重载配置文件:service network restart
或:systemctl restart network.service
两条命令效果一样
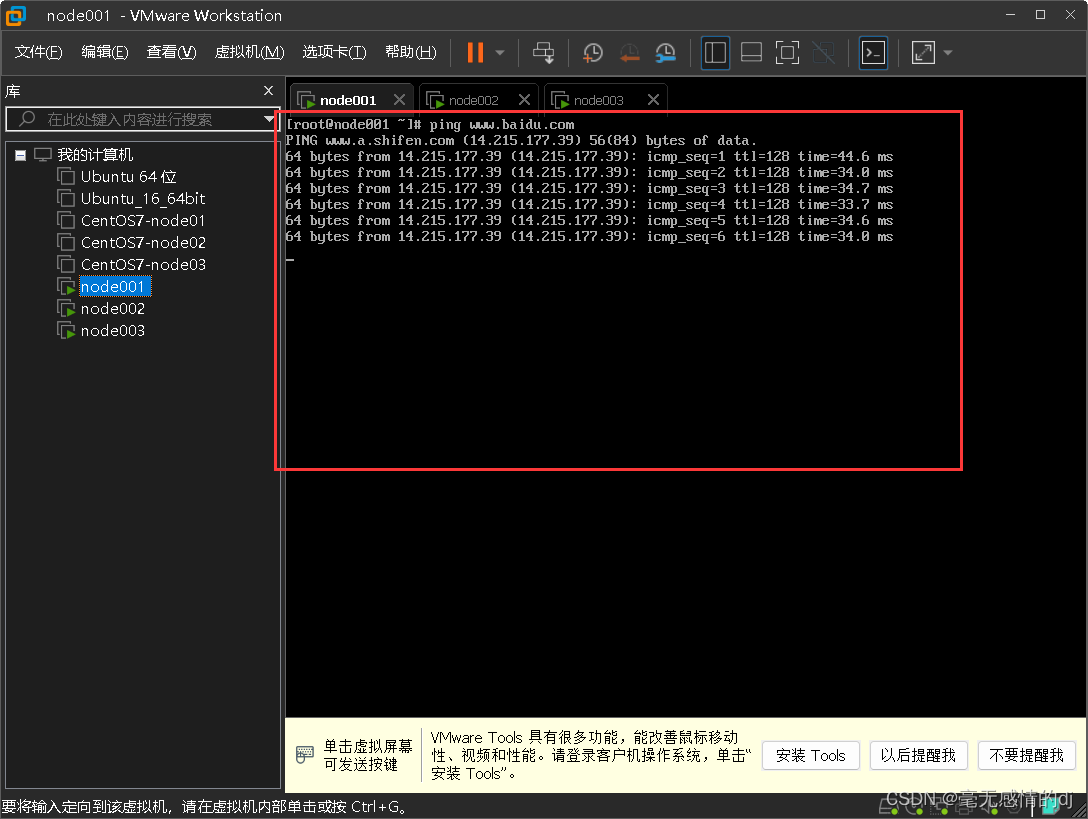
控制台输入:ping www.baidu.com
出现如下效果,表示网络配置完成
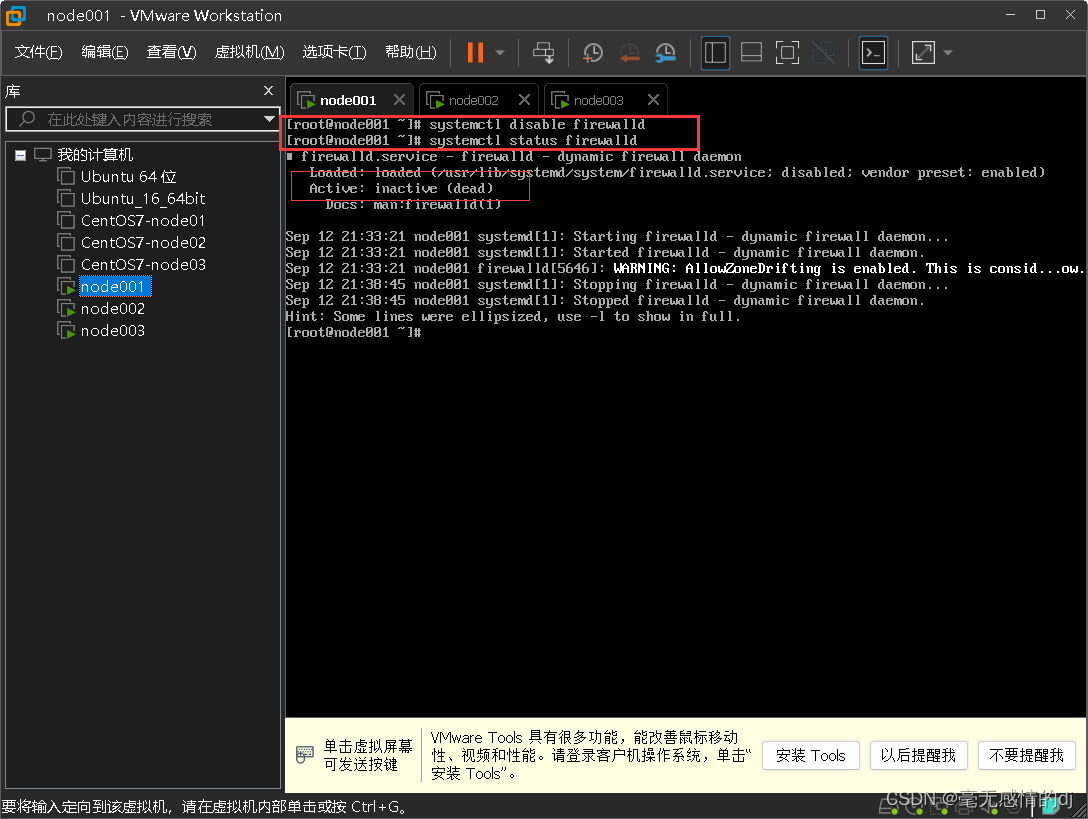
3.虚拟机防火墙firewalld设置
# 查看运行状态:systemctl status firewalld
# 停止防火墙:systemctl stop firewalld
# 启动防火墙:systemctl start firewalld
防火墙重启与重载操作
# 重启操作:systemctl restart firewalld
# 重载操作:systemctl restart firewalld
设置为开机启动与开机不启动
# 启动:systemctl enable firewalld
# 开机不启动:systemctl disable firewalld
由于防火墙会监控所有的端口,如tomcat的8080端口,nginx的80端口等等,如果不关闭防火墙,且没有手动开放对应的端口号,那么对应的端口就无法访问,如下图。
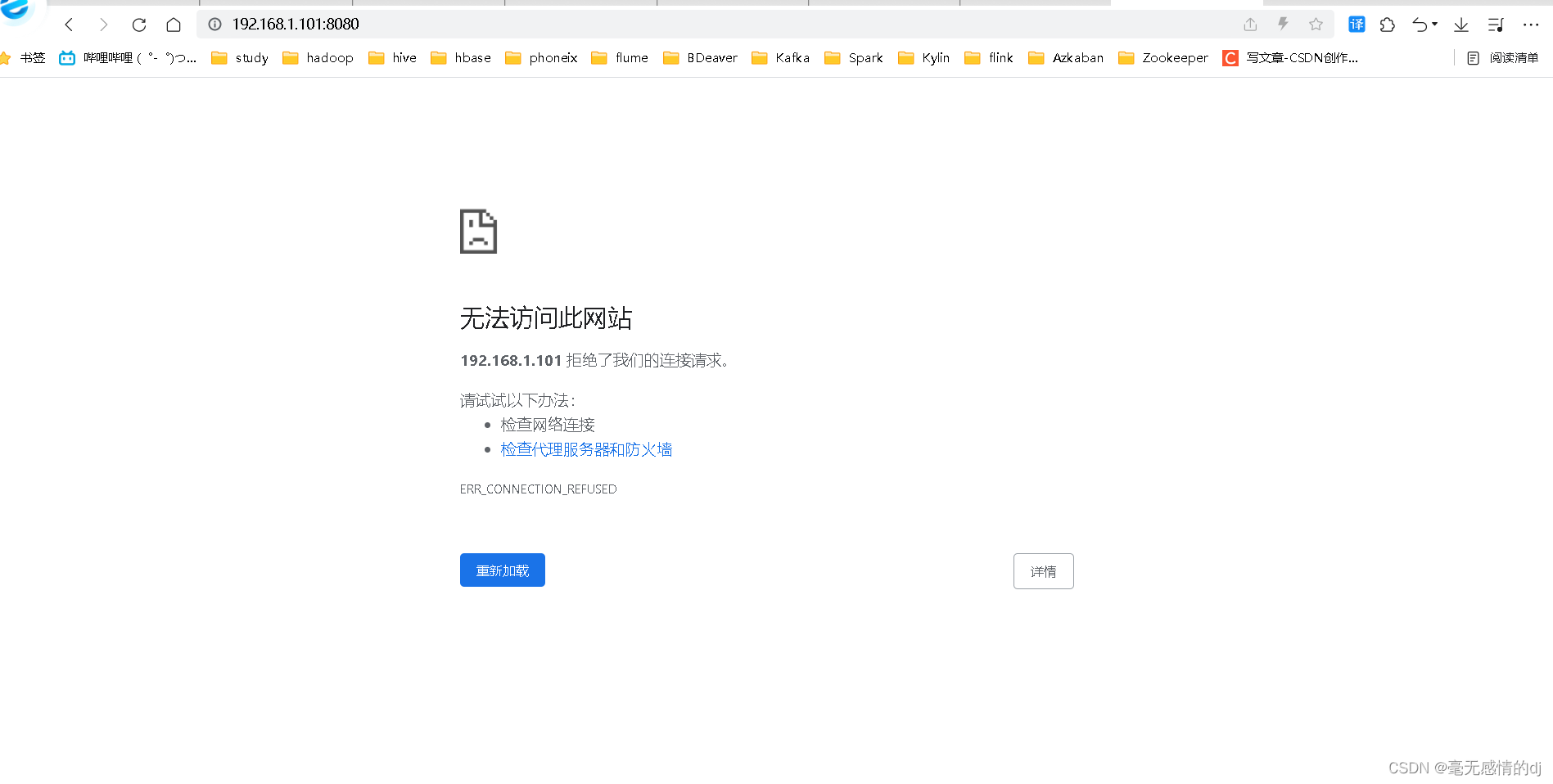
所以我们执行开机不启动防火墙的命令:systemctl disable firewalld
4.虚拟机克隆以及基本配置
克隆操作
以虚拟机node001为模板克隆node002与node003,并启动 :
注:node002和node003也需要完成前面的关闭防火墙操作

在node002输入:vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改为
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.1.102
GATEWAY=192.168.1.2
NETMASK=255.255.255.0
DNS1=61.128.128.68在node003输入:vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改为
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.1.103
GATEWAY=192.168.1.2
NETMASK=255.255.255.0
DNS1=61.128.128.68修改主机名
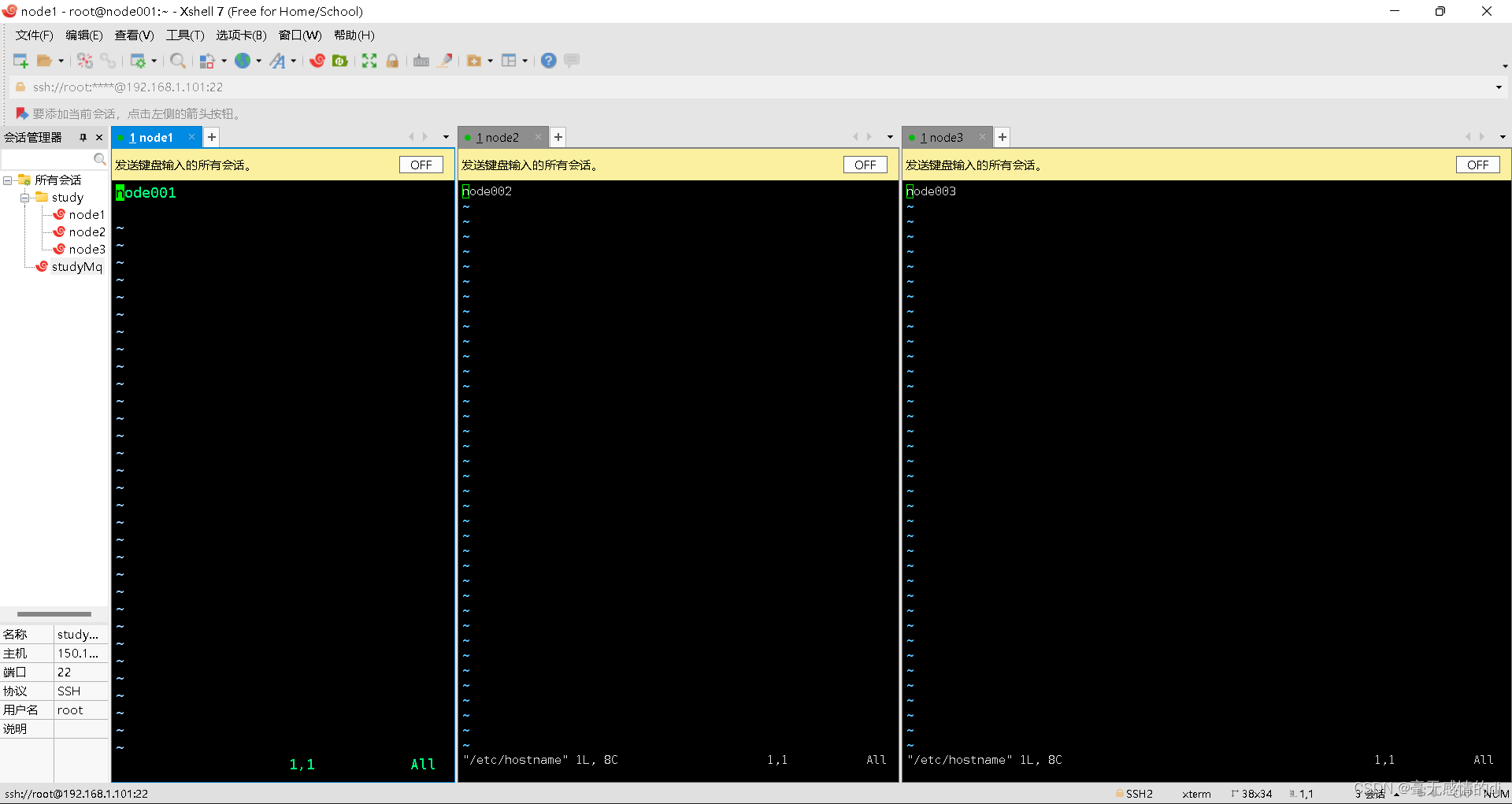
现在我们使用Xshell连接上三台虚拟机

点击工具-->发送键输入到-->所有会话

终端输入:vim /etc/hostname
修改为:
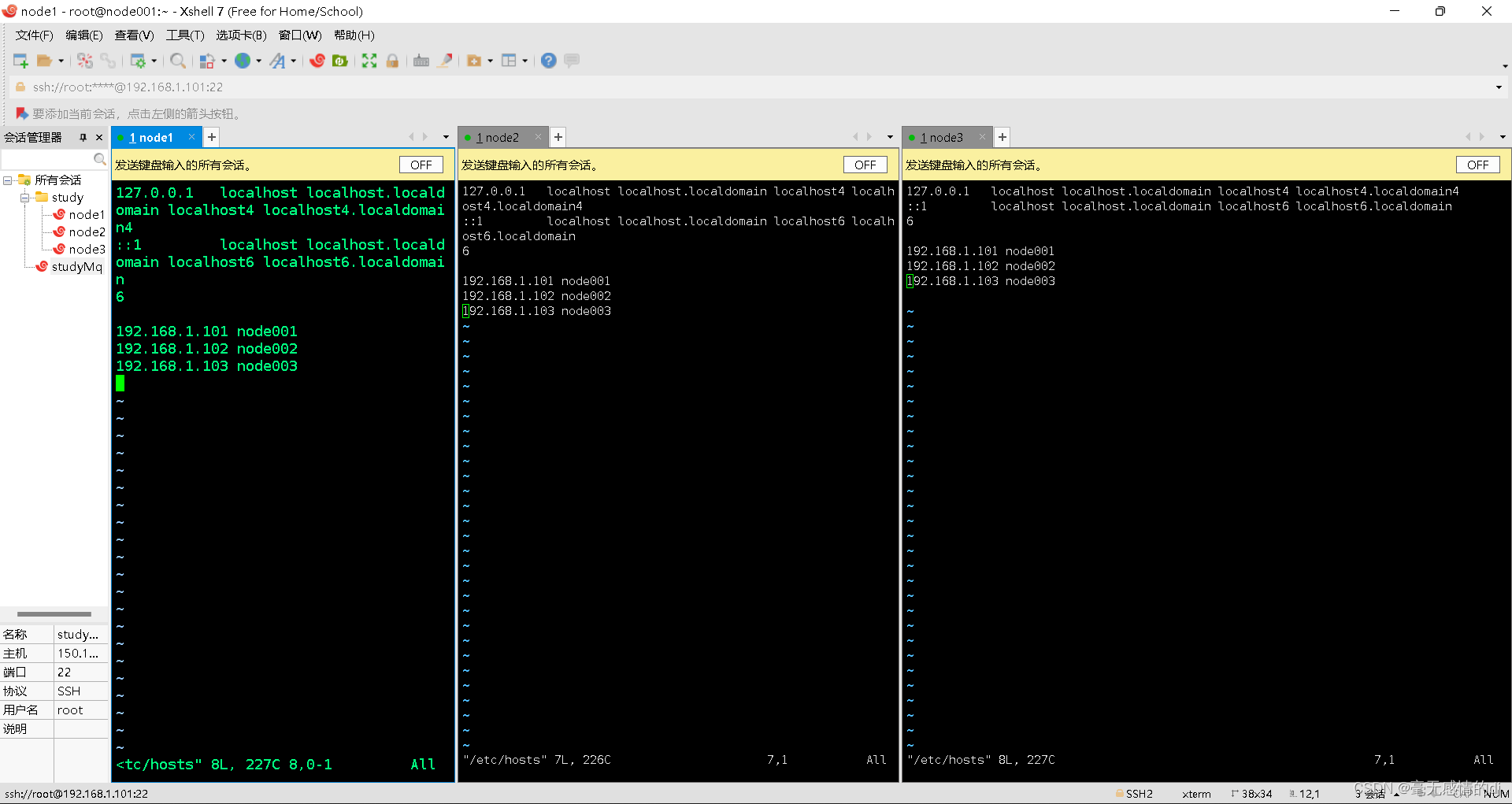
终端输入:vim /etc/hosts
修改为
三台机器同步时间
1、查看当前服务器时间
# date -R
响应为:Mon, 12 Sep 2022 22:11:59 +0800
2、安装ntpdate服务
# yum install ntpdate
3、直接用域名同步中国上海时间 是阿里云的服务器
# timedatectl set-timezone Asia/Shanghai
# ntpdate ntp1.aliyun.com
响应为:12 Sep 22:31:42 ntpdate[6306]: step time server 120.25.115.20 offset 1038.828497 sec
4、查看新时间是否已同步
# date -R
响应为:Mon, 12 Sep 2022 22:32:41 +0800
5.虚拟机之间免密
在我们今后以及本次zookeeper集群搭建如果各个虚拟机之间不能免密访问,那么我们的集群100%搭建不起来。就像高速公路etc通道和普通通道的区别。etc通道肯定是效率更高的吧,而普通通道每次通过都需要给手动给钱,要是钱数不对,还不能对你放行。
公钥和私钥介绍
在非对称加密中,我们会用到两个密钥,一个是公钥,另一个是私钥。
公钥是给别人的,别人持有的;而私钥是你自己的,只能你持有,别人是不可以持有的。
1.首先,我们要知道什么是签名验证算法,什么是加密加密算法。
签名验证算法:用来证明这个消息是自己发的,别人不可以冒充自己发送消息。
加密算法:用来对要发送的消息内容进行加密,不想让别人看见你发送的消息内容。
2.如何进行签名验证,如何进行加密。
签名验证算法中,我们需要使用自己的私钥去对消息摘要数据(哈希值)进行加密,公钥是用来对签名进行验证的。因为只有你持有私钥,因此,别人是无法冒充你,去对消息摘要数据进行加密,进而无法冒充你去发信息,或者对消息进行篡改。因此,它保证了消息的不可抵赖性与不可篡改性。
在加密算法中,别人使用你给他的公钥对它要发生给你的消息进行加密,由于其他人没有你的私钥,是无法进行解密的。因此,他是保证消息的机密性的。
免密操作
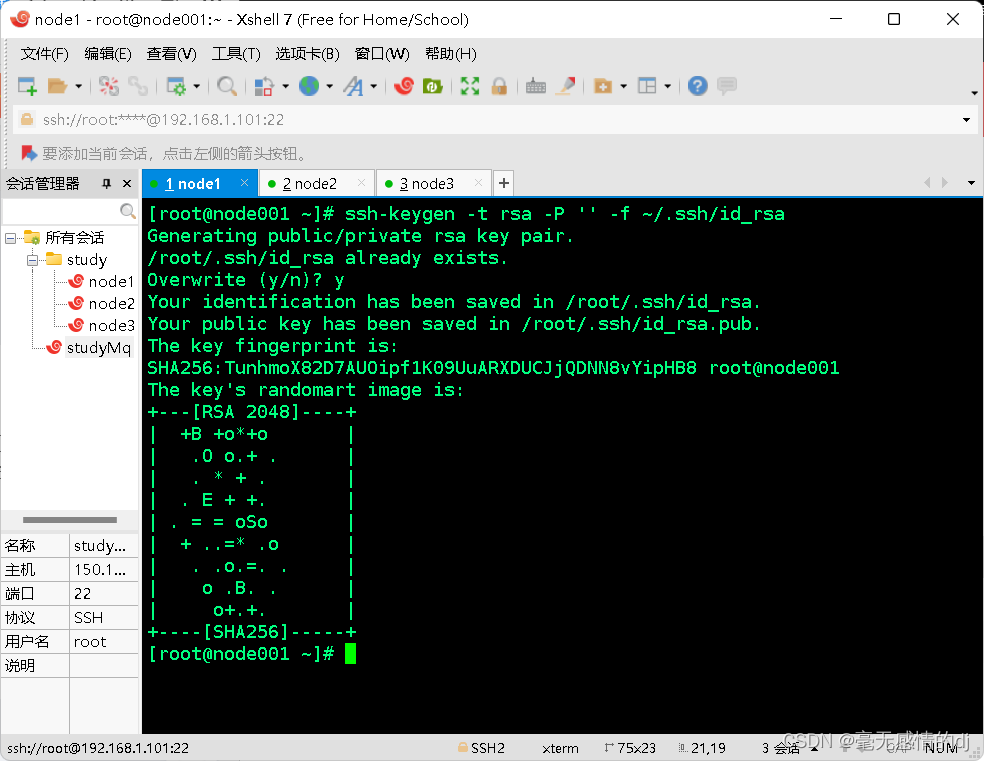
生成公钥私钥:
node001终端输入:ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
查看私钥:cat ~/.ssh/id_rsa

查看公钥:cat ~/.ssh/id_rsa.pub

现在你想要谁可以免密钥登录只需要把公钥传递给对方主机即可
我们先测试一下没有传递公钥的情况:
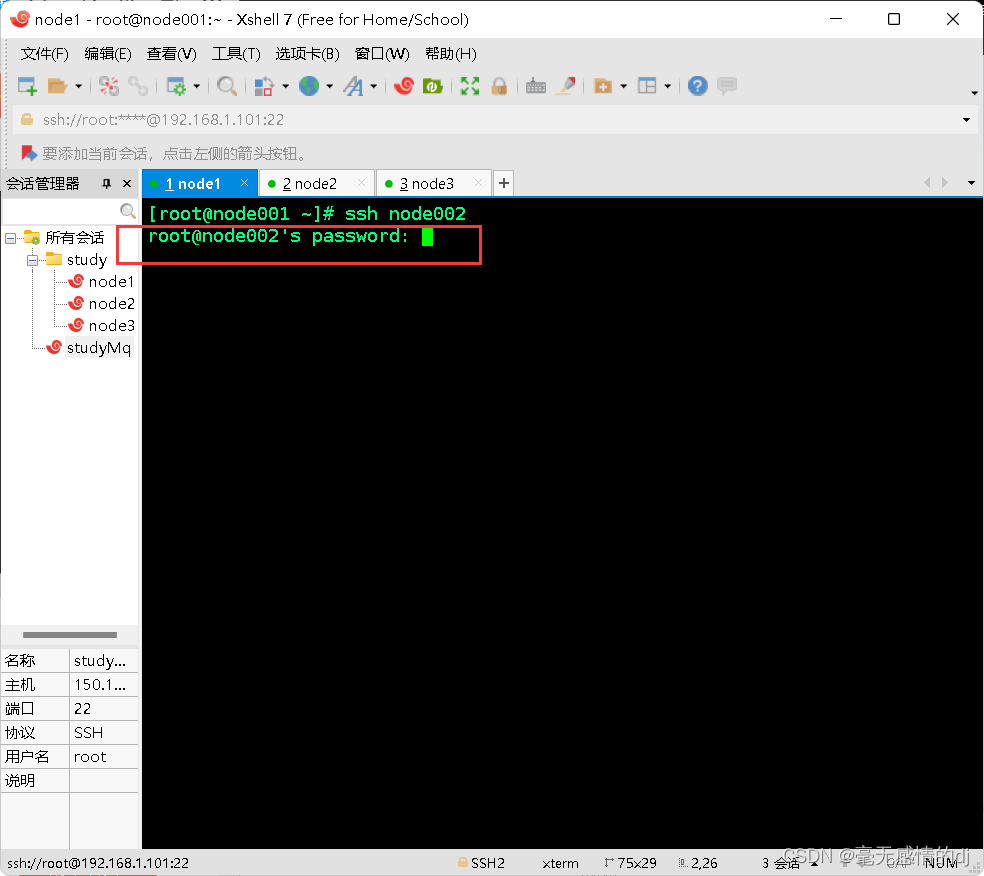
这个时候是需要我们输入密码的。
现在传递公钥,输入命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@node002
注:这次是需要输入密码的。
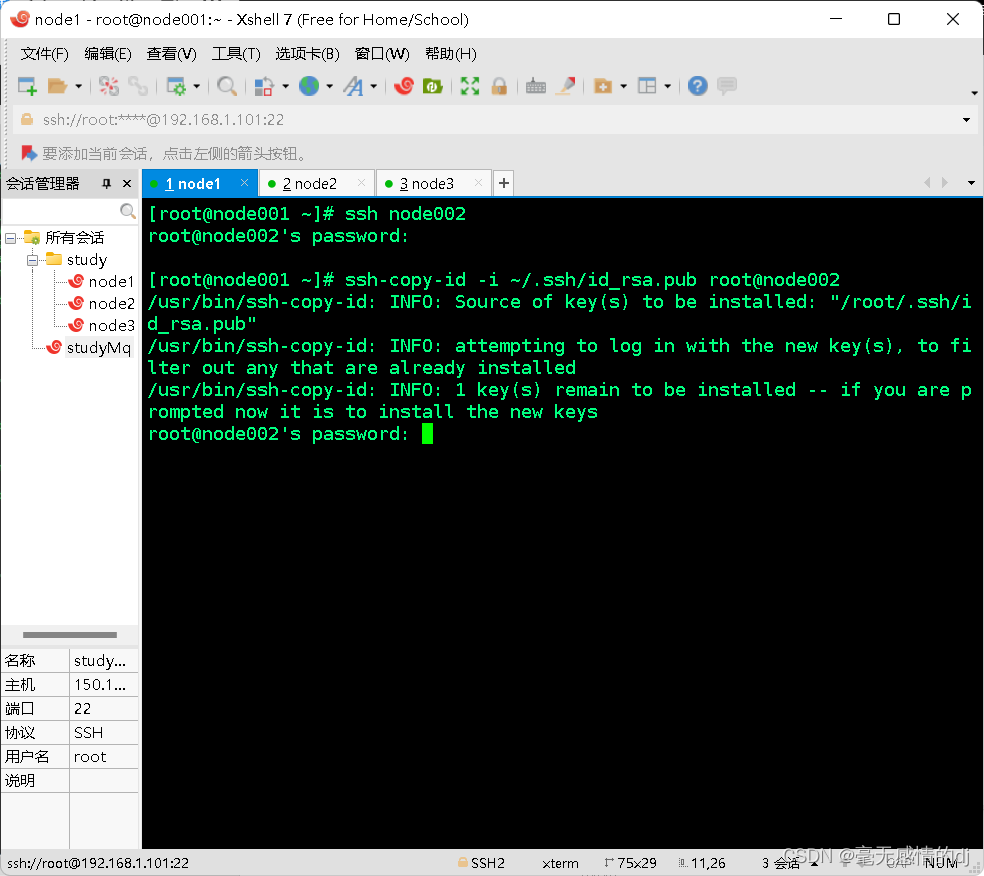
得到响应结果是:
Now try logging into the machine, with: "ssh 'root@node002'" and check to make sure that only the key(s) you wanted were added.
翻译是:现在尝试登录到机器,使用:ssh 'root@node002',并检查以确保只添加了您想要的键。
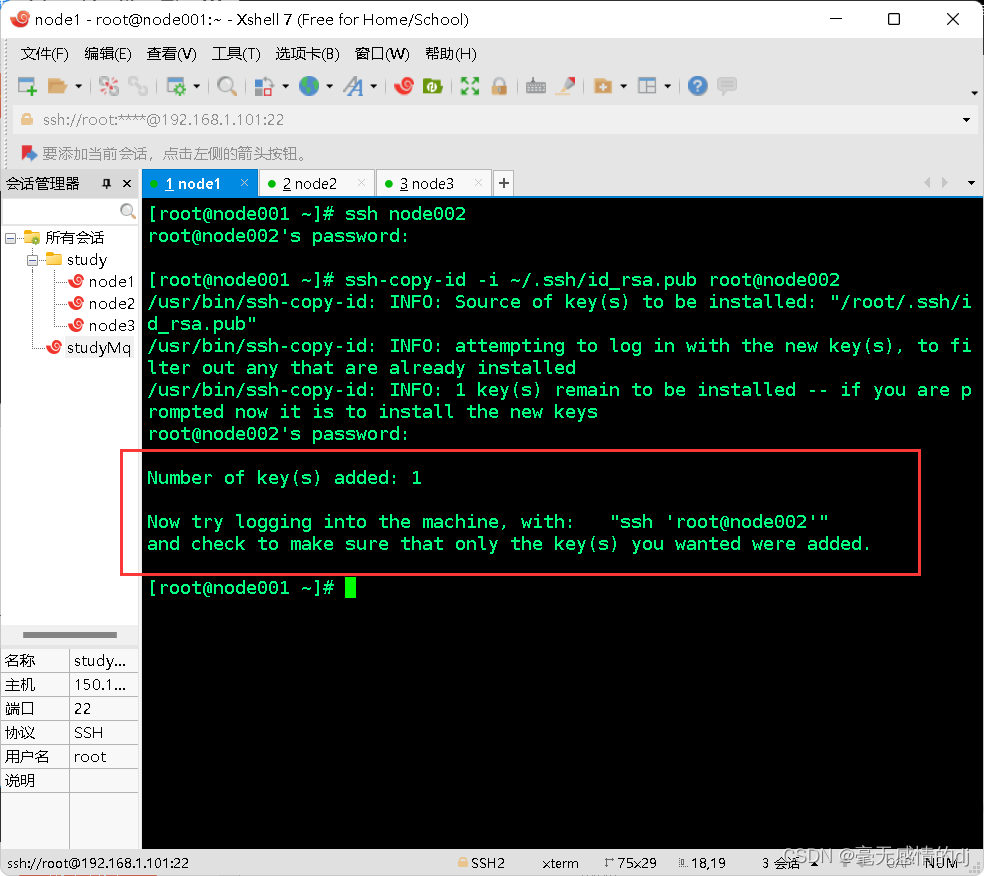
再次登录node002
 已经免密登录成功了。
已经免密登录成功了。
现在我们分别在node002和node003创建公钥私钥:ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
接下来我们需要重复操作:
node002 发送公钥给 node001 :ssh-copy-id -i ~/.ssh/id_rsa.pub root@node001
node001 发送公钥给 node003 :ssh-copy-id -i ~/.ssh/id_rsa.pub root@node003
node003 发送公钥给 node001 :ssh-copy-id -i ~/.ssh/id_rsa.pub root@node001
node002 发送公钥给 node003 :ssh-copy-id -i ~/.ssh/id_rsa.pub root@node003
node003 发送公钥给 node002 :ssh-copy-id -i ~/.ssh/id_rsa.pub root@node002
现在三台机器已经全部实现免密登录的操作了!
6.JDK安装以及环境变量配置
将下载好的jdk安装包传于node001上(下载地址见前文)
可以自行下载xftp进行文件传输或者虚拟机安装:yum -y install lrzsz
终端输入rz进行文件传输。
我这里直接将文件拖入xshell node001窗口也行。
我们以jdk-8u231-linux-x64.rpm为例,
先解压安装包:rpm -ivh jdk-8u231-linux-x64.rpm
然后终端输入:vim /etc/profile
在末行加入:
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64/
export PATH=$JAVA_HOME/bin:$PATH
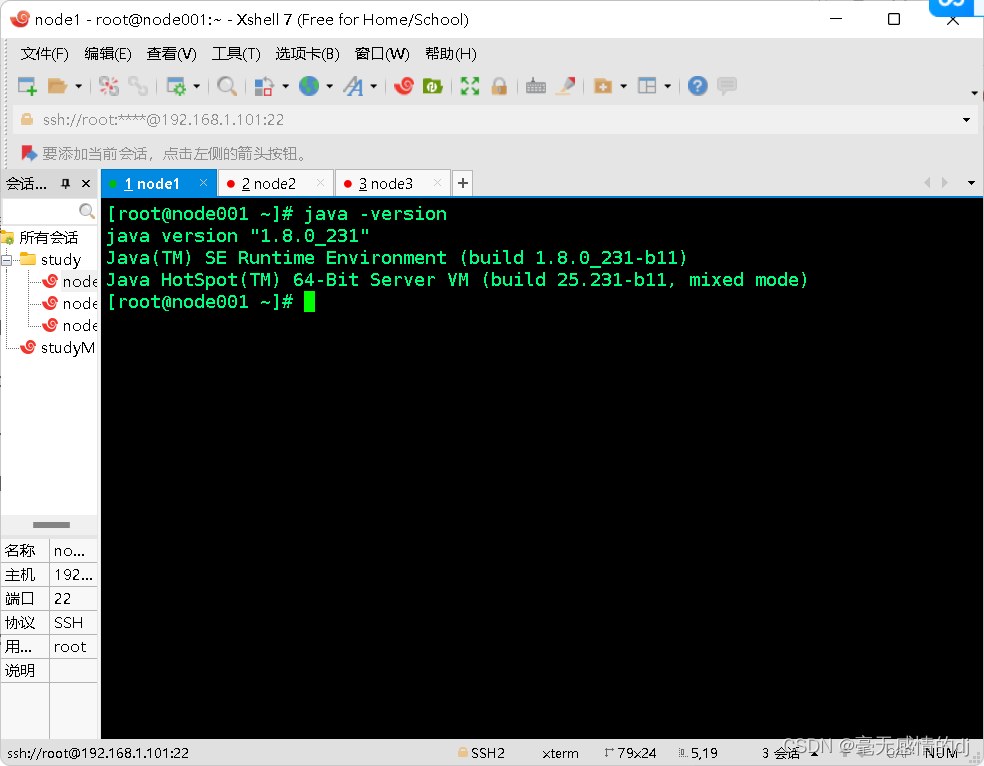
终端输入:java -version,出现下图表示成功。
然后使用scp将处理好的配置文件和java文件传输给node002和node003
scp -r /usr/java root@node002:/usr/
scp /etc/profile root@node002:/etc/
---------------------------------------------------
scp -r /usr/java root@node003:/usr/
scp /etc/profile root@node003:/etc/
正式开始集群搭建
1.上传zookeeper安装包
以zookeeper-3.4.5.tar.gz为例
上传文件到node001后先解压:tar -zxvf zookeeper-3.4.5.tar.gz -C /opt/zookeeper-3.4.5
然后删除安装包文件:rm -rf zookeeper-3.4.5.tar.gz
2.zookeeper配置文件
1.先进入目录:
# cd /opt/zookeeper-3.4.5/conf
2.进入conf目录,复制zoo-sample.cfg重命名为zoo.cfg,通过修改zoo.cfg来对zookeeper进行配置。这个名字是固定的,因为zookeeper启动会检查这个文件,根据这个配置文件里的信息来启动服务。
# cp zoo-sample.cfg zoo.cfg
3.# vim zoo.cfg,此文件中需要修改以下两处:
①dataDir:指定zookeeper将数据保存在哪个目录下,如果不修改,默认在/tmp下,这个目录下的数据有可能会在磁盘空间不足或服务器重启时自动被linux清理,所以一定要修改这个地址。按个人习惯将其修改为自己的管理目录。
dataDir=/var/bdp/zookeeper
②完全分布式:多台机器各自配置,zookeeper有几个节点,就配置几个server。例如本文总共三台主机,于是在配置文件末尾加上下面三行,可以填写ip也可以是/etc/hosts的主机名,建议后者,可以充分解耦
#设置服务器内部通信的地址和zk集群的节点
server.1=node001:2888:3888
server.2=node002:2888:3888
server.3=node003:2888:38884.注意:一定要跟自己的myid配置对应上,否则集群一直处于非正常状态 myid文件中就是N,则对应zoo.cfg 中server.{N} ,关于myid配置,见下一小节 zookeeper服务默认的端口号为2888和3888,2888原子广播端口,3888选举端口,
修改好的zoo.cfg文件如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/var/bdp/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#设置服务器内部通信的地址和zk集群的节点
server.1=node001:2888:3888
server.2=node002:2888:3888
server.3=node003:2888:38883.zookeeper myid配置
先创建上文zoo.cfg中dataDir所对应的文件 :mkdir -p /var/bdp/zookeeper
到dataDir指定目录下生成一个文件叫myid(必须叫这个名字),其中写上一个数字表明当前机器是哪一个编号的机器,注意:本机的myid内容一定要与server.{N}保持一致
终端输入:touch /var/bdp/zookeeper/myid
终端输入:echo 1 >> /var/bdp/zookeeper/myid
这段是将1输出到文件myid中 对应zoo.cfg中server.1
终端输入:cat /var/bdp/zookeeper/myid

操作到这一步node001的所有配置已经完成了。
4.拷贝与修改配置文件
1.复制zookeeper文件到node002和node003:
scp -r /opt/zookeeper-3.4.5 root@node002:/opt/
scp -r /opt/zookeeper-3.4.5 root@node003:/opt/
2.分别在node002和node003创建文件:mkdir -p /var/bdp/zookeeper
3.复制myid文件到node002和node003:
scp /var/bdp/zookeeper/myid root@node002://var/bdp/zookeeper/
scp /var/bdp/zookeeper/myid root@node003://var/bdp/zookeeper/
登录node002输入:echo 2 >> /var/bdp/zookeeper/myid
登录node003输入:echo 3 >> /var/bdp/zookeeper/myid
zookeeper环境变量
3个节点都终端输入:vim /etc/profile
末行添加:
export ZOOKEEPRT_HOME=/opt/zookeeper-3.4.5
export PATH=$ZOOKEEPRT_HOME/bin:$PATH
终端输入:source /etc/profile
终端发送所有会话到3台虚拟机:zkServer.sh start
得到反馈:
JMX enabled by default
Using config: /opt/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
终端输入:zkServer.sh status
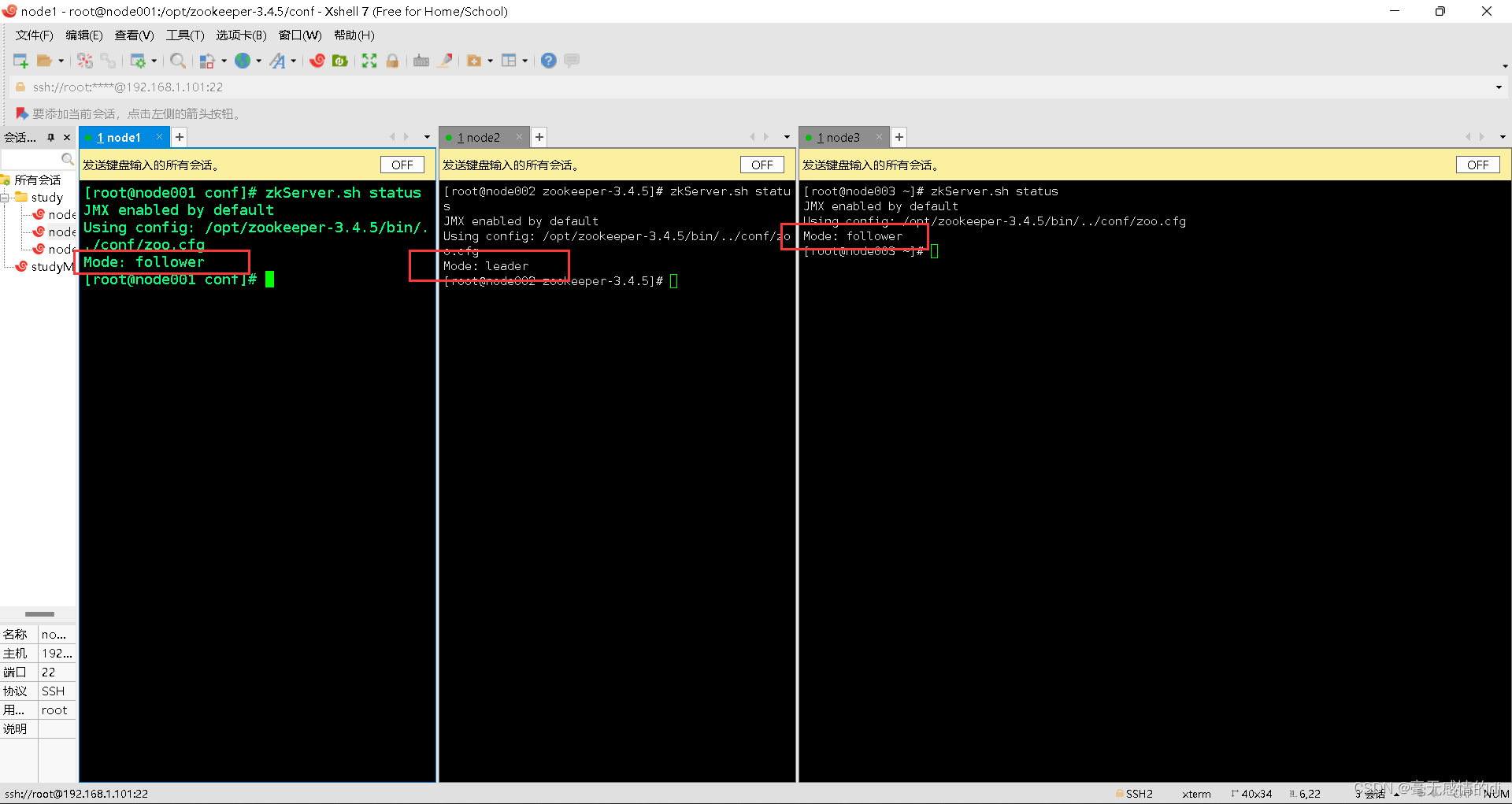
基本命令:
#启动ZK服务:zkServer.sh start
#停止ZK服务:zkServer.sh stop
#重启ZK服务:zkServer.sh restart
#查看ZK服务状态:zkServer.sh status
#我们看到三台主机,会发现某一台被选举为leader,其余两台为follower
启动集群的时候,集群数量启动没有超过一半,状态会有错误提示,当集群启动数量超过一半就会自动转为正常状态,并且此台使集群进入正常工作状态的服务器会成为leader角色,集群中其他服务器的角色为fllower。 zookeeper伪集群模式搭建到此完成。
四、zookeeper存储结构
储存结构
- zookeeper是一个树状结构,维护一个小型的数据节点znode
- 数据以key-value的方式存在,目录是数据的key
- 所有的数据访问都必须以绝对路径的方式呈现
1.一个znode的格式
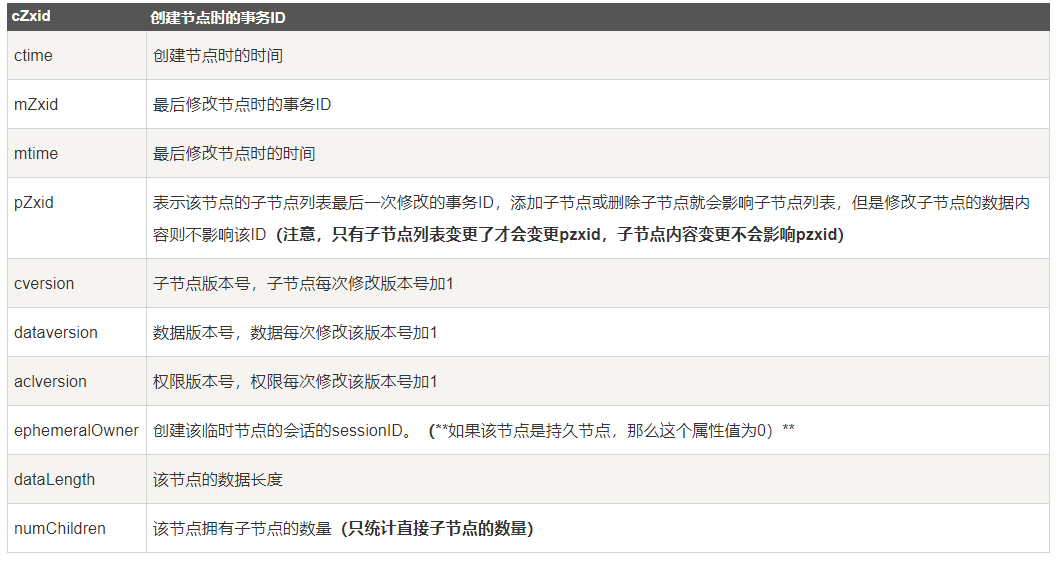
Znode:
(1)在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以向节点存储 数据或者获取数据。
(2)Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点, 我们称之为“znode” Zookeeper 中的数据是按照“树”结构进行存储的。而且 znode 节点还分为 4 中不同 的类型。
(3)每一个 znode 默认能够存储 1MB 的数据(对于记录状态性质的数据来说,够了)
可以使用 zkCli 命令,登录到 Zookeeper 上,并通过 ls、create、delete、get、set 等命令操作这些 znode 节点。
终端输入:zkCli.sh

我们创建一个bdp节点:create /bdp test

可以使用get命令获取节点信息:get /bdp

其余操作不再过多累述。
2. 节点的分类
-
PERSISTENT--持久化目录节点
- 默认创建的就是持久化节点
- 客户端与zookeeper断开连接后,该节点依旧存在。
-
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
- 客户端与zookeeper断开连接后,该节点依旧存在,只是zookeeper给该节点名称进行顺序编号

- 客户端与zookeeper断开连接后,该节点依旧存在,只是zookeeper给该节点名称进行顺序编号
-
EPHEMERAL-临时目录节点
- 客户端与zookeeper断开连接后,该节点被删除
- 可以被所有客户端查看
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
- 客户端与zookeeper断开连接后,该节点被删除,只是zookeeper给该节点名称进行顺序编号
-
Sequential序列化节点
- 使用
create -s /znode value进行创建 - 就是给该节点名称进行顺序编号,不会重复
- 使用
五、zookeeper操作命令
-
启动zookeeper
zkServer.sh start -
登录到zookeeper
zkCli.sh -server node001:2181 -
zookeeper是一个集群,默认登录到了本地,(node001),2181是zookeeper客户端端口。
-
查看某个目录下的子节点
ls /path -
查看某个目录下子节点的详细信息
ls2 /path -
新建节点:
create /bdp test -
查看节点信息:
get /bdp -
修改节点值
set /bdp hello最多1M
-
删除节点
delete /bdp/xxx - 当然也可以使用,
rmr /node强行删除。 -
退出客户端
quit -
帮助命令
help
六、zkServer的监听机制
- 官方说明
- 一个Watch时间是一个一次性的触发器,当被设置了watch的数据发生改变的时候,则服务器将这个改变发送给设置Watch的客户端,以便通知它们。
- 监听机制特点
- 一次性触发数据改变时,一个watch event会被送到client,但是client只会收到一次这样的信息。
- watcher event异步发送。
- 数据监视
- zookeeper有数据监视和子数据监视
- getdata()和exists()设置数据监视
- getchildren()设置子节点监视
- 数据监听只会监听被设置watch,不会监听其子节点的任何变化
监听实现
get /node watch

我们使用xshell新建一个窗口登录到node001的zookeeper
当对/bdp的子节点进行操作时,watch都没有反应,只有对/bdp进行操作时,发watchedEnvent。

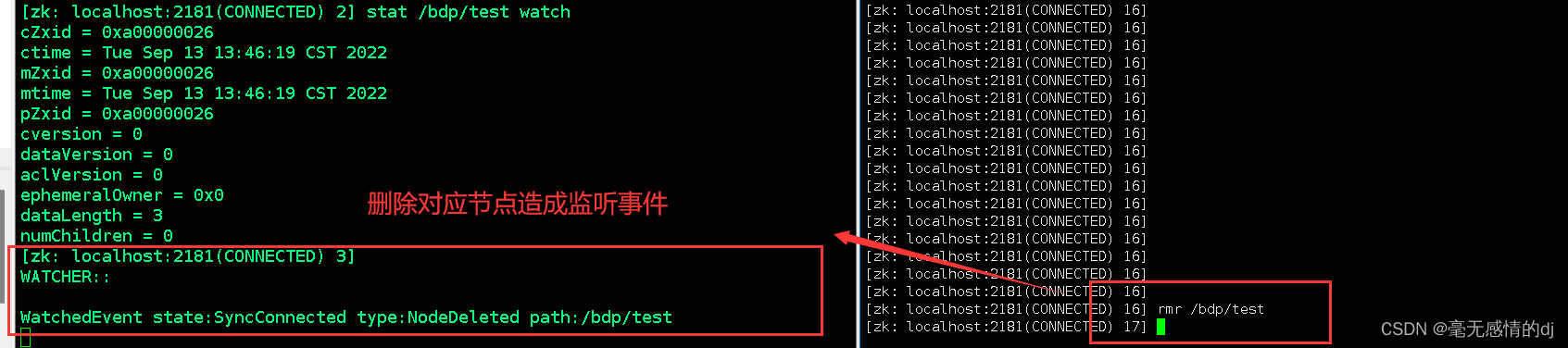
stat /node watch
 新增和删除node的子节点,不会发生watchedEnvent。删除node时发生了。
新增和删除node的子节点,不会发生watchedEnvent。删除node时发生了。
ls /node watch

对其子节点进行监控,新增或删除子节点时,都会发生watchedenvent

七、 ACL权限控制与四字命令
- ACL:Access Control List 访问控制列表
权限设置
概述
-
ACL 权限设置的格式时是scheme: id:permission三段式:
-
授权方式:scheme
-
授权对象:id
-
授予的权限:permission
-
-
特性如下:
- zookeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限
- 每个znode支持设置多种权限控制方案和多个权限
- 子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
例如:
setAcl /test2 ip:192.168.1.101:crwda将/test2的crwad权限授予ip地址为
192.168.1.101的用户
SCHEME 采用何种方式授权
- world:全局权限授予
- auth:代表已经认证通过的用户
- digest:用户名-密码认证方式,这也是业务系统中最常用的。
- ip:使用客户端的主机ip来进行授权
ID
| 权限模式 | 授权对象 |
|---|---|
| IP | 通常是一个IP地址,例如'192.168.1.101' |
| Digest | 自定义,通常是“username:password(username:用户名,password,密码)”,例如"CCC:12311414141414124124124" |
| World | 只有一个id:anyone |
| Auth | 与Digest一致 |
permission 授予什么权限
- ZK的节点有五种操作权限:CREATE(增)、DELETE(删)、READ(查)、WRITE(改)、ADMIN(管理员权限)
- 五种权限中,delete是指对子节点的删除权限,而其他四种权限是对自身节点的操作权限
- CREATE:创建子节点
- DELETE:删除子节点
- READ:读取节点数据及显示子节点列表
- WRITE:可以设置节点数据
- ADMIN:可以设置 节点访问控制列表权限
ACL相关命令
- getAcl path : 读取ACL权限配置
- getAcl /
- setAcl setAcl path acl : 设置ACL权限
- setAcl / world:anyone:wa
- setAcl / auth:libing:123456:rcwda
- addauth scheme auth : 添加认证用户
- addauth digest libing:123456
四字命令
安装nc
yum install nc -y
使用方式
-
在终端输入
echo 四字命令 | nc ip 2181
或:echo 四字命令 | nc node001 2181

可以看到BaseNode的集群配置情况。
如果四字命令不可使用,那么在/zookeeper/conf/zoo.cfg文件最后加上
4lw.commands.whitelist=*
四字命令
| Zookeeper四字命令 | 功能描述 |
|---|---|
| conf | 打印出服务相关配置信息 |
| cons | 列出所有链接到这台服务器的客户端全部连接/绘画详细信息.包括"接受/发送"的包数量,会话id,操作延迟,最后的操作执行等信息 |
| crst | 重置所有连接的连接和会话统计信息 |
| dump | 列出那些比较重要的会话和临时节点 |
| envi | 打印出服务环境的详细信息。 |
| reqs | 列出未经处理的请求 |
| ruok | 测试服务是否处于正确状态。如果确实如此,那么服务返回"imok",否则不做任何相应。 |
| stat | 输出关于性能和连接的客户端的列表。 |
| srst | 重置服务器的统计。 |
| srvr | 列出连接服务器的详细信息 |
| wchs | 列出服务器watch的详细信息。 |
| wchc | 通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表。 |
| wchp | 通过路径列出服务器watch的详细信息。它输出一个与session相关的路径。 |
| mntr | 输出可用于检测集群健康状态的变量列表 |
总结
1.技术方面
zookeeper的理论知识和搭建集群使用的技术都不难,按照文档一步步走是没有问题的,关键在于提起对大数据学习的兴趣,对大数据有一定的了解。
2.心态方面
对于才入坑的小伙伴,接触新东西,最重要的是不要惧怕困难,勇于接受吸纳,遇到不懂的立马或百度或求师,养成积极乐观的学习态度和心态一定能够学好大数据的。
--------------------------------------------------------------------------------
如您对文章有建议或者意见,或者想共同学习的朋友可以通过我的邮箱联系到我。
邮箱:719167291@qq.com
到此就结束了。如有侵权,请联系我,将妥善处理。
参考资料
《从Paxos到Zookeeper》 电子档














 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









