









列表是很特别的,因为每一列都是索引。通常情况下,你不需要考虑创建在HANA创建索引,因为在大多数情况下,查询的执行过程已经是最优的了。然而,对于大数据集,列和索引的查询性能仍然存在差异。
当创建索引的时候,你需要和创建索引之前的性能做一下比较。有可能创建索引之后,性能并没有得到提升,最明智的做法是删除这个索引。
对于大数据量表来说,唯一索引和主键会导致性能问题。对于事实表,一般需要避免增加唯一性约束。但是对于维度表,一般推荐添加主键。
当有多字段过滤查询时,可以创建一个多字段索引,例如
CREATE INDEX idx_trans ON Trans_DTL(Trans_No, Prod_ID);这个索引会对下面这个查询有优化
SELECT SUM(SALES_NET) FROM Trans_DTL WHERE Trans_No=11323 AND Prod_ID=8762;这种混合索引对多字段关联也有优化效果
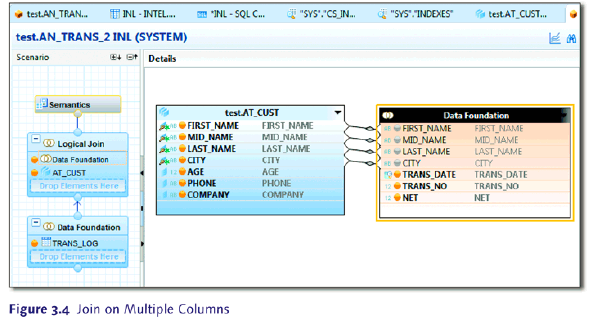
索引创建如下
CREATE INDEX IDX_TRANS_LOG ON Trans_log(First_name,Mid_name,Last_name, City);
CREATE INDEX IDX_Cust_idx ON Cust_inf (First_name,Mid_name,Last_name,City);可以对每个字段都创建索引
CREATE INDEX I DX_TRANS_LOG_F ON Trans_log(First_name) ;
CREATE INDEX I DX_TRANS_LOG_M ON Trans_log(Mid_name) ;
CREATE INDEX I DX_TRANS_LOG_L ON Trans_log(Last_name) ;
CREATE INDEX I DX_TRANS_LOG_C ON Trans_log(City) ;
CREATE INDEX I DX_Cust_i nf_F ON Cust_inf (First_name) ;
CREATE INDEX I DX_Cust_i nf_M ON Cust_inf (Mid_name) ;
CREATE INDEX I DX_Cust_i nf_L ON Cust_inf (Last_name) ;
CREATE INDEX I DX_Cust_i nf_C ON Cust_inf (City) ;不管查询用到哪个字段,都会用到索引,具体的性能如何就需要考虑表的大小等其他因素。你需要做一个测试,来决定是否需要创建这些索引。
还有一个更好的方法就是创建一个计算字段,将这些字段拼接起来,然后两个表通过这个拼接起来的字段做关联
ALTER TABLE Trans_log ADD(FULLNAME VARCHAR(50) GENERATED ALWAYS AS
First_name||Mid_name|| Last_name||City);
ALTER TABLE Cust_inf ADD(FULLNAME VARCHAR(50) GENERATED ALWAYS AS
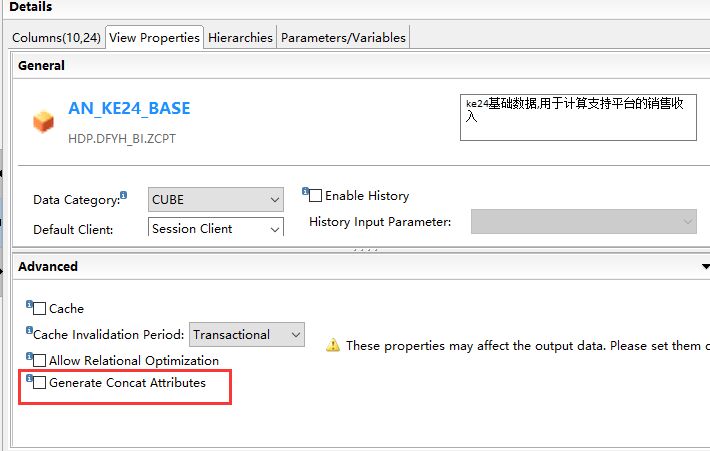
First_name||Mid_name|| Last_name||City) ;如果是使用分析视图的话,可以在勾选GENERATE CONCAT ATTRIBUTES来自动生成计算字段















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









