 关注
关注
 分享
分享
wudl5566
这个作者很懒,什么都没留下…
展开
-
Flink 版本数据湖(hudi)实时数仓---flinkcdc hudi kafak hive
1.架构图2.实现实例2.1 通过flink cdc 的两张表 合并 成一张视图, 同时写入到数据湖(hudi) 中 同时写入到kafka 中2.2 实现思路1.在flinksql 中创建flink cdc 表2.创建视图(用两张表关联后需要的列的结果显示为一张速度)3.创建输出表,关联Hudi表,并且自动同步到Hive表4.查询视图数据,插入到输出表 -- flink 后台实时执行2.3pom 文件需要的类<?xml version="1.0" encoding="UTF原创 2022-02-20 22:08:00 · 7963 阅读 · 0 评论 -
flink cdc 整合 数据湖hudi 同步 hive
1. 版本说明组件版本hudi10.0flink13.5hive3.1.02. 实现效果 通过flink cdc 整合 hudi 到hiveflink cdc 讲解flink cdc 1.2实例flink cdc 2.0 实例原创 2022-02-18 00:44:00 · 5522 阅读 · 5 评论 -
flink kakfa 数据读写到hudi
flink kafka hudi组件版本hudi10.0flink13.51.2.flink lib 需要的jar 包hudi-flink-bundle_2.12-0.10.0.jarflink-sql-connector-kafka_2.12-1.13.5.jarflink-shaded-hadoop-2-uber-2.8.3-10.0.jar下面是所有的jar 包-rw-r--r-- 1 root root 7802399 1月 1 08:27 dor原创 2022-02-13 21:46:40 · 2165 阅读 · 2 评论 -
flinksql 实时查询hudi 的数据
1.版本组件版本hudi10.0flink13.52. 场景:在flink 中新建一张表(t1)插入数据, 然后同时用过另外一张表进行查询(t2) 场景如图3. t1 建表 CREATE TABLE t1( uuid VARCHAR(20), name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) PARTITIONED BY (`part原创 2022-02-07 16:05:30 · 3324 阅读 · 0 评论 -
flink13.5整合hudi10
1. 版本组件版本hudi10.0flink13.52.hudi 源码下载https://github.com/apache/hudi/releases2.1 需要改flink 版本为13.5根目录下面的pom 文件<flink.version>1.13.5</flink.version><hive.version>3.1.0</hive.version><hadoop.version>3.1.原创 2022-02-07 00:19:42 · 1873 阅读 · 0 评论 -
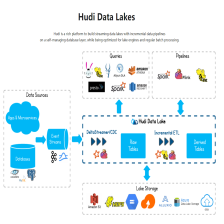
大数据之数据湖---flink 整合hudi
1.hudi 简介 Huid支持流式的读写操作,流数据可以通过Huid的增量来进行数据追加,精准的保存Index位置,如果一旦写入或者读出的时候出现问题,可以进行索引回滚数据,因为在Hudi写入和写出的时候他是要记录元数据信息的。 Hudi最大的特点就是会进行预写日志功能,也就是把所有的操作都先预写,然后一旦发生问题就会先找预写日志Log,进行回滚或者其他操作,所以你会发现在Hudi中,它会写很多Log日志。三大特点:流式读写、自我管理、万物皆日志2.hudi 应用3. 官网https://原创 2021-10-05 23:22:26 · 2627 阅读 · 0 评论