







个人博客请访问 http://www.x0100.top
CAP定理:
CAP定理又称CAP原则,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
接下来我们通过公司实际工作中的一个项目来具体分析CAP原则。
小明在公司奋发图强,经过多年的努力,终于做到了架构师的位置。
架构师的椅子还没坐热,很快就来了一个项目要做架构设计。
老板把小明叫来,谆谆教导说: 小明啊, 数据是我们的宝贵资产,你设计的系统可千万要保证数据不能丢失啊!
小明说老板放心, 这方面我有经验, 一般来讲我们要做数据的冗余处理, 简单的来讲就是给数据做多个副本来保存。 我会设计一个分布式系统, 把数据备份到多个机器节点去。
几天后, 小明给发了一张图, 展示了这个分布式系统是怎么工作的:
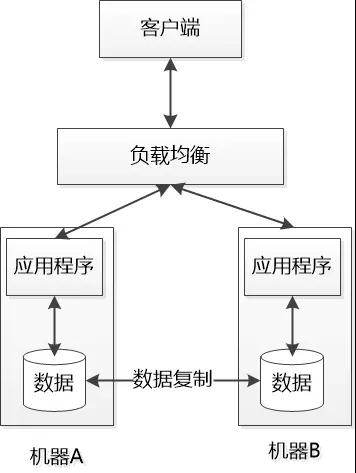
数据副本在不同的机器上做冗余, 中间有数据的复制, 保证数据的同步。
虽然只是两台机器, 但是也构成了一个简单的分布式环境。
老板虽然不懂技术, 但是看到数据在不同的机器之间有备份,也就放心了。
经过几个月的开发和测试,系统顺利上线, 但是大家很快就发现: 分布式系统不像单机系统那么简单, 由于网络的原因, 或者某个机器的原因很容易导致通讯失败,或者节点不可用。
有一天, 用户先访问了左边的机器A , 写入了一条数据, 然后机器A很不幸, 网线被悲催的网管给踢掉了, 这直接导致了两个严重的后果:
1. 负载均衡找不着机器A,认为它死翘翘了, 就要把用户的下一次访问转到机器B去。
2. 数据复制也找不着机器A , 只好罢工。 用户刚写入的数据没法复制到机器B,机器B上还是老数据
怎么办? 虽然这是一次偶然, 把网管臭骂一顿, 插上网线就可以了, 但是谁能保证以后两个机器的通信是一致畅通的呢?
组里的小王说: 我们的机器B 还活着呢, 还能提供服务, 数据复制不到机器B, 不就是少看几条数据嘛, 无伤大雅,不影响大局, 勉强可用, 插上网线后数据复制就会工作, 一切就会恢复正常。
小王无意中选择了系统的可用性(Availability,简称A), 系统能提供服务就好, 数据不一致可以忍受。
小明说: 不行, 老板说了,我们系统的数据极为重要, 数据如果不一致会带来严重后果,所以机器B上的和这些关键数据相关的功能也必须停掉, 必须等到机器A插上网线,数据同步以后才能开工
很明显, 小明遵循老板指示, 把一致性(Consistency, 简称C )放到了首位。
所以问题就很明显了, 在网络节点之间无法通信的情况下, 和数据复制相关的功能, 要么选择可用性(A) , 要么选择一致性(C), 不能同时选择两者。
小明仔细思考了一下, 其实这两种选择的背后其实隐藏着另外一个事实, 那就是网络节点之间无法通信的情况下, 节点被隔离,产生了网络分区, 整个系统仍然是可以工作的, 大胖给它起了个名: 分区容错性(Partition tolerance, 简称P)。
如果选择了可用性(A) + 分区容错性(P) , 就要放弃一致性(C)。
如果选在一致性(C) + 分区容错性(P) , 就得放弃可用性(A) , 对了, 这种情况下,虽然系统的有些功能是不能使用的, 因为需要等待数据的同步, 但是那些和数据同步无关的功能还是可以访问的 , 相当于系统做了功能的降级。
既然有AP和CP, 会不会出现仅仅是CA(一致性+可用性)这种组合呢? 就是没有分区容错性, 只保留可用性和一致性? 仔细想想, 这种情况其实就退化成了单机应用, 没有意义了。
小明觉得自己似乎发现了一个规律: 在一个分布式计算机系统中,一致性(C),可用性(A)和分区容错性(P) 这三种保证无法同时得到满足,最多满足两个。
他决定把找个规律叫做CAP定理, 听起来比较高大上, 显得自己高深莫测。
如果你实在是搞不懂这CAP, 小明会告诉你一个更容易理解的版本: 在一个分布式系统中, 在出现节点之间无法通信(网络分区产生), 你只能选择 可用性 或者 一致性, 没法同时选择他们。
BASE理论:
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。接下来我们着重对BASE中的三要素进行详细讲解。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。
响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
亚马逊首席技术官Werner Vogels在于2008年发表的一篇文章中对最终一致性进行了非常详细的介绍。他认为最终一致性时一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够胡渠道最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟,系统负载和数据复制方案设计等因素。
在实际工程实践中,最终一致性存在以下五类主要变种。
因果一致性:
因果一致性是指,如果进程A在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程A更新后的最新值,即不能发生丢失更新情况。与此同时,与进程A无因果关系的进程C的数据访问则没有这样的限制。
读己之所写:
读己之所写是指,进程A更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者而言,其读取到的数据一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性:
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性:
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
单调写一致性:
单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
以上就是最终一致性的五类常见的变种,在时间系统实践中,可以将其中的若干个变种互相结合起来,以构建一个具有最终一致性的分布式系统。事实上,可以将其中的若干个变种相互结合起来,以构建一个具有最终一致性特性的分布式系统。事实上,最终一致性并不是只有那些大型分布式系统才设计的特性,许多现代的关系型数据库都采用了最终一致性模型。在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制国耻鞥通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于事务日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么狠显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是认为数据订正,关系型数据库还是能搞保证最终数据达到一致——这就是系统提供最终一致性保证的经典案例。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性使相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性与BASE理论往往又会结合在一起使用。














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









