







一、修剪二叉搜索树
牢记递归三要素
- 终止条件
- 递归调用
- 返回值
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
//终止条件
if (root == null) return null;
//递归调用,小于最小值,大于最大值
if (root.val < low) return trimBST(root.right, low, high);
else if (root.val > high) return trimBST(root.left, low, high);
//递归调用,在最小值和最大值范围内 将返回值赋值当前节点的左右子树
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
//返回值
return root;
}
}
二、将有序数组转换为二叉搜索树
参考链接108. 将有序数组转换为二叉搜索树 - 力扣(LeetCode)
class Solution {
//中间左右双指针,不断遍历使整棵树完整
public TreeNode sortedArrayToBST(int[] nums) {
return dfs(nums, 0, nums.length - 1);
}
private TreeNode dfs(int[] nums, int lo, int hi) {
//终止条件
if (lo > hi) {
return null;
}
// 以升序数组的中间元素作为根节点 root。
int mid = lo + (hi - lo) / 2;
TreeNode root = new TreeNode(nums[mid]);
//递归调用: 递归的构建 root 的左子树与右子树。
root.left = dfs(nums, lo, mid - 1);
root.right = dfs(nums, mid + 1, hi);
//返回值
return root;
}
}
三、把二叉搜索树转换为累加树
class Solution {
int sum = 0;
public TreeNode convertBST(TreeNode root) {
//终止条件
if (root == null) {
return null;
}
//递归调用,一直向最右端子树遍历
convertBST(root.right);
sum += root.val;
root.val = sum;
convertBST(root.left);
//返回值
return root;
}
}
参考链接2.2 迭代与递归 - Hello 算法 (hello-algo.com)
复习:使用递归的前提
- 迭代:“自下而上”地解决问题。从最基础的步骤开始,然后不断重复或累加这些步骤,直到任务完成。
- 递归:“自上而下”地解决问题。将原问题分解为更小的子问题,这些子问题和原问题具有相同的形式。接下来将子问题继续分解为更小的子问题,直到基本情况时停止(基本情况的解是已知的)。
以上述求和函数为例,设问题 𝑓(𝑛)=1+2+⋯+𝑛 。
- 迭代:在循环中模拟求和过程,从 1 遍历到 𝑛 ,每轮执行求和操作,即可求得 𝑓(𝑛) 。
- 递归:将问题分解为子问题 𝑓(𝑛)=𝑛+𝑓(𝑛−1) ,不断(递归地)分解下去,直至基本情况 𝑓(1)=1 时终止。
递归类型
-
调用栈:
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等。这将导致两方面的结果。
- 函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间。
- 递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低。
-
尾递归:
有趣的是,如果函数在返回前的最后一步才进行递归调用,则该函数可以被编译器或解释器优化,使其在空间效率上与迭代相当。这种情况被称为尾递归(tail recursion)。
- 普通递归:当函数返回到上一层级的函数后,需要继续执行代码,因此系统需要保存上一层调用的上下文。
- 尾递归:递归调用是函数返回前的最后一个操作,这意味着函数返回到上一层级后,无须继续执行其他操作,因此系统无须保存上一层函数的上下文。
以计算 1+2+⋯+𝑛 为例,我们可以将结果变量
res设为函数参数,从而实现尾递归:/* 尾递归 */ int tailRecur(int n, int res) { // 终止条件 if (n == 0) return res; // 尾递归调用 return tailRecur(n - 1, res + n); } -
递归树
-
当处理与“分治”相关的算法问题时,递归往往比迭代的思路更加直观、代码更加易读。以“斐波那契数列”为例。
-
设斐波那契数列的第 𝑛 个数字为 𝑓(𝑛) ,易得两个结论。
- 数列的前两个数字为 𝑓(1)=0 和 𝑓(2)=1 。
- 数列中的每个数字是前两个数字的和,即 𝑓(𝑛)=𝑓(𝑛−1)+𝑓(𝑛−2) 。
按照递推关系进行递归调用,将前两个数字作为终止条件,便可写出递归代码。调用
fib(n)即可得到斐波那契数列的第 𝑛 个数字:/* 斐波那契数列:递归 */ int fib(int n) { // 终止条件 f(1) = 0, f(2) = 1 if (n == 1 || n == 2) return n - 1; // 递归调用 f(n) = f(n-1) + f(n-2) int res = fib(n - 1) + fib(n - 2); // 返回结果 f(n) return res; } -
观察以上代码,我们在函数内递归调用了两个函数,这意味着从一个调用产生了两个调用分支。如图 2-6 所示,这样不断递归调用下去,最终将产生一棵层数为 𝑛 的递归树(recursion tree)。
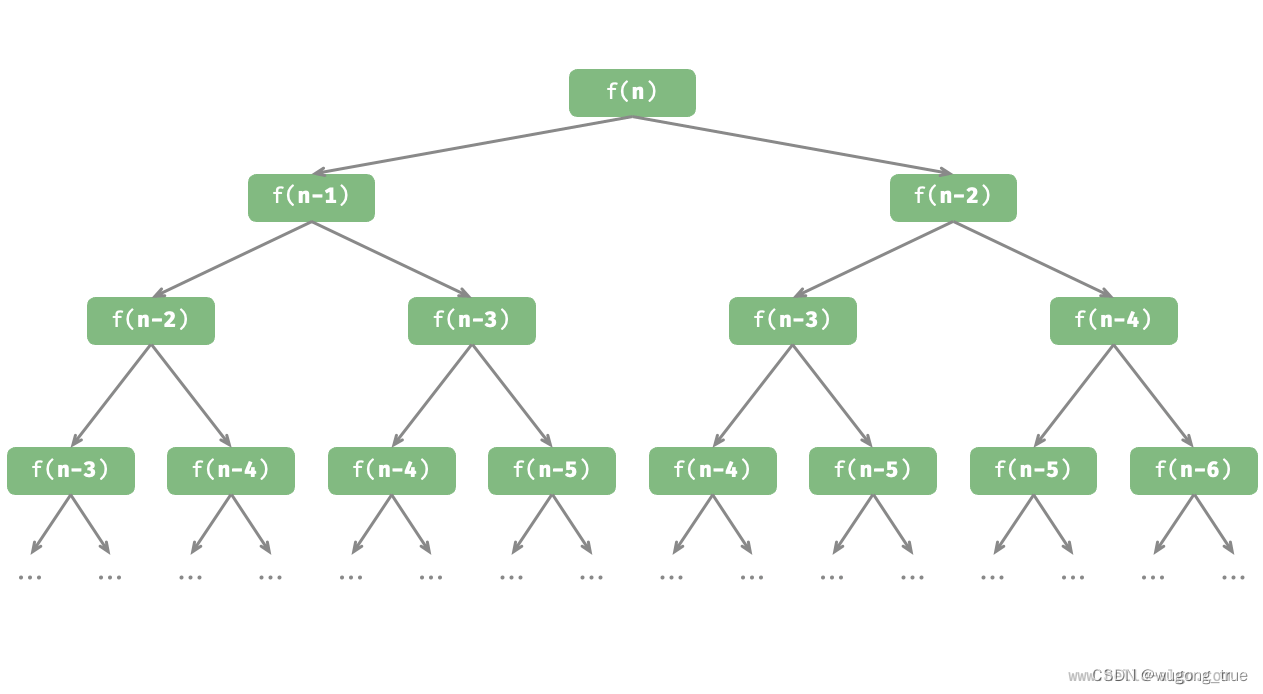
-
从本质上看,递归体现了“将问题分解为更小子问题”的思维范式,这种分治策略至关重要。
- 从算法角度看,搜索、排序、回溯、分治、动态规划等许多重要算法策略直接或间接地应用了这种思维方式。
- 从数据结构角度看,递归天然适合处理链表、树和图的相关问题,因为它们非常适合用分治思想进行分析。
-
-
普通递归:求和操作是在“归”的过程中执行的,每层返回后都要再执行一次求和操作。
-
尾递归:求和操作是在“递”的过程中执行的,“归”的过程只需层层返回。
- 从数据结构角度看,递归天然适合处理链表、树和图的相关问题,因为它们非常适合用分治思想进行分析。
-
普通递归:求和操作是在“归”的过程中执行的,每层返回后都要再执行一次求和操作。
-
尾递归:求和操作是在“递”的过程中执行的,“归”的过程只需层层返回。
















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









