







由于现在企业基本上都使用innodb引擎,所以本文讲的是innodb引擎上的索引。
先思考一个问题,为什么在数据库上加了索引后查询速度变得这么快?
索引是什么?
索引是按照一定结构存放在磁盘里的数据。这种做据结构,是一种能高效检索数据的数据结构。
想象一下,磁盘上那么多数据,要如何快速找到想要的某些数据呢?是不是得像图书馆的书一样,对它们进行编排,比如想要在茫茫书海里找到沈从文的《边城》,我们会走到文学区,再找到中国文学的货架。mysql的索引也类似,但更高级。
二叉平衡树
(1) 我们可以先想象一下,有很多号码球放在地上,你要如何归类摆放,以后才能快速找到某个号码。先思考一会儿再往下看。大家可能会想到二分法,按顺序分成两大份,每份里面又分成两份。
(2) 先来看一种简单的树据结构,二叉平衡树。便于后面理解索引使用的B+树。
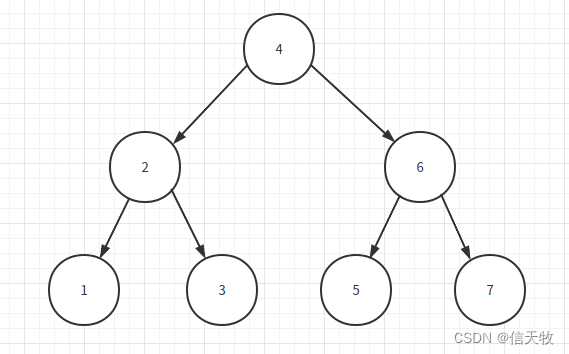
如上图,每个号码球下面分两个叉,左边的球小,右边的球大。如果我们要寻找5号球在哪里,先从入口球4号开始往下寻找,5比4大走右下方遇到6,5比6小往左下方遇到5,就找到了。两三步就准确的找到了。
(3) 看起来,感觉检索数据的能力还不错。但这里有个严重的问题,如果数据量特别大的时候,比如有100万个号码球,这颗树会特别高,枝繁叶茂,检索数据就会一层一层往下检索,很慢很慢。
对应到数据库,上面的数字可以理解成数据库里表的主键id,每个id背后存放了对应的一行数据。
B树:
再来看看B树,它其实是一颗多叉树。也是左边的数字小,右边的数字大。
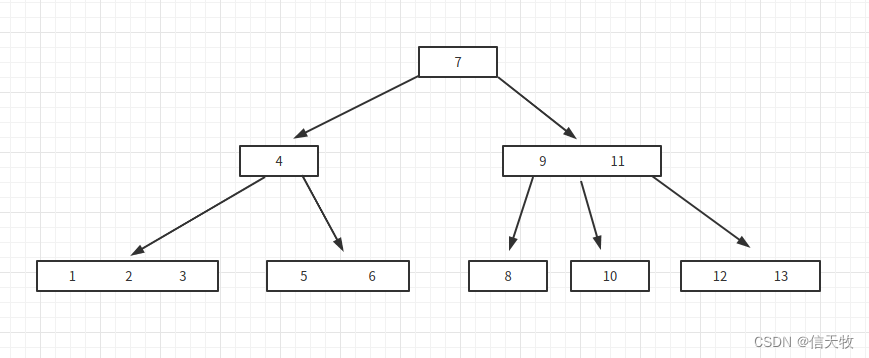
如果想找到8,从入口7开始,8比7大往右下方走,遇到9和11采用二分法,8比9小,往左下方,找到了8
现在能存不少的数据量了,树的高度也大大缩减了。看似已经很好了,然而,大神们认为还有优化的空间。
(1) 这个树据结构不支持数据的范围查找,比如要找 大于等于7 且 小于等于12的所有数据,就只能每个值重新从头开始一个节点一个节点寻找,性能很差。
(2) 由于每个节点都存储了用户的每行数据,所以树的高度,还是会比较高,能不能哪怕是百万千万行甚至是亿级别的数据,树的高度都控制在三四层?
B+树:
最后,找到了完美的方案,树够矮,也支持按范围查询。
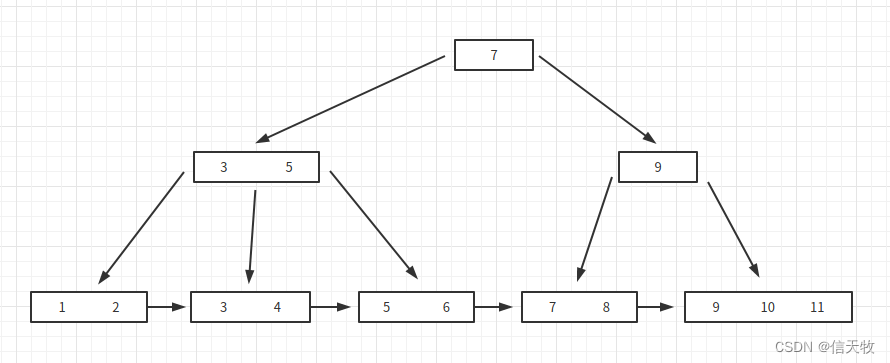
(1) 大家有没有发现什么不一样,长得跟B树好像一样,你再认真瞅瞅。是不是发现了里面出现了重复的数字,并且最下面一排是从小到大连续的所有数字。因为最下面一排包含了所有主键id,我们就可以把每个id对应一行的数据全部存到最下面一排,上面不存数据,只存索引值(主键id)。
(2) 现在来说说刚才B树的两个问题,这里得到了解决。
我们把最下面一排称为叶子节点。由于非叶子节点没存放数据,所以它能存放的索引值就更多,而且是很多很多,树的高度问题解决了。
范围查询的问题,一看便知,最下面一排是连续的,所以当然支持范围查询。
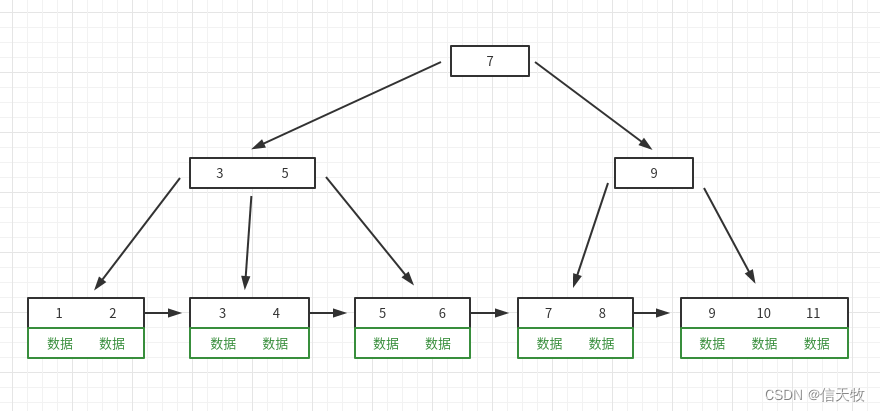
最终索引长这样(一级索引)
如下图,这就是mysql的索引,我们称它为一级索引(也可以叫主键索引、聚集索引)。这也是B+树的样子,也是mysql存放的数据的样子
二级索引
现在来讲讲二级索引,也就是非主键索引,比如你在user表的username字段加了索引,这索引在底层的结构将长这样:
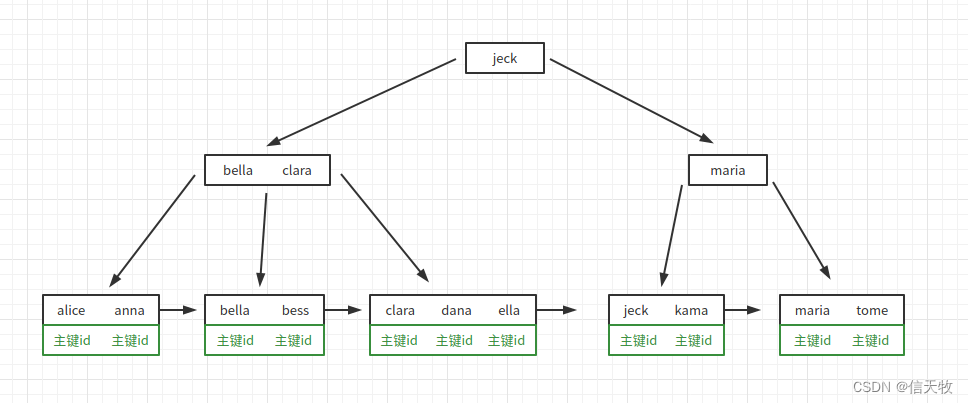
它按照英文字母的顺序从左到右排列,最下面是主键id。比如要查找 username = ‘ella’,按上面讲到的原理,最终获取到的不是具体数据,而是主键id,然后通过主键id再去一级索引里查找到最终的数据。因为索引也是一张表,所以这就叫回表。
什么是联合索引
(1) 先用生活用语讲一个生活例子。比如,你有很多很多衣服,请你把衣服按颜色深浅从左到右一字排开,颜色浅排左边,颜色深排右边。颜色一样的怎么办?不能叠起来,颜色相同时尺码小的放左边,尺码大的放右边。这就是联合索引。
现在要你把白色的26码找出来,很容易对不对?让你把紫色的26到31码全找出,也很容易对不对?如果不指定颜色,直接让你把26到31码的衣服找出来,你就没有什么好办法,只能老老实实从头到尾去找一遍。这就是最左匹配原则。
(2) 再举个正式点儿的例子,给订单表创建一个联合索引,以 user_id product_id create_time三个字段的联合索引
ALTER TABLE `order` ADD INDEX `n_a_p`(`user_id`,`product_id`,`payment_time`) USING BTREE;
先用我们日常生活语言来解释下:数据库里,把所有订单按用户id的大小从左到右一张一张订单排放,如果是同一个用户的订单,则商品id小的放左边,如果是同一个商品,则支付时间小的放左边。
(3) 现在来看图,就很好理解了。联合索引长这样:
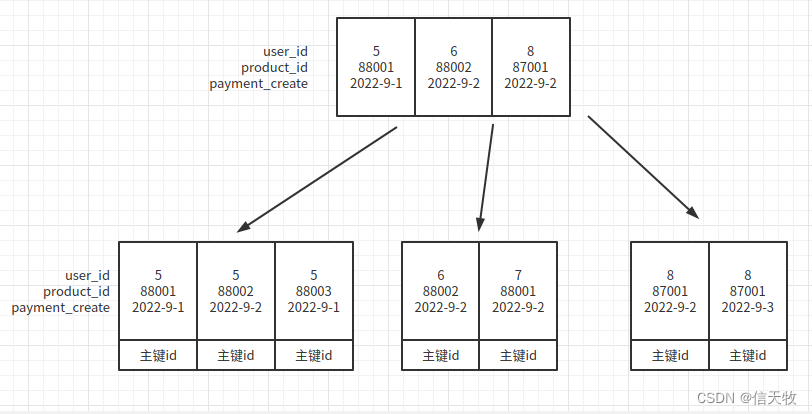
(3) 现在已经明白最左原则是什么了吧?
这个会走索引:select * from order where user_id=8 and product_id=87001;,因为按照约定的规律,很快就能找到名字叫bill并且30岁的人。
这个不走索引:select * from order where product_id=88001;你想找到id为88001的商品,只能从头到尾一个一个去查,没有规律。
这个也不走索引:select * from order where product_id=88002 and payment='2022-9-2'; 理由同上。
什么是覆盖索引?
查询语句指定的字段,刚好在二级索引表里,不用回表,这就是覆盖索引
select product_id,payment_id from where user_id = 5;这里要查询用户id等于5的所有订单的商品id、支付时间,直接在二级索引表里就有这些数据,所以不需要回表。
select * from where user_id = 5;这就需要回表,性能要低一些。
这也是为什么建议大家别用select * …的写法而要指定字段的原因之一。顺便提一下,指定字段,一般数据就少,节约了内存,性能好。
索引,差不多讲完了。准备收尾。
优点:
(1) 减少磁盘IO操作,检索数据快。因为在磁盘中检索数据的次数少。
(2) order by、group by 时,速度快。因为数据结构决定,排好序了。
(3) 支持范围查询。原因同上。
缺点:
(1) 硬盘上多占了空间,数据库变得更大。因为索引也是一份数据,存在磁盘上的数据;
(2) 插入和更新数据时,效率变低。因为同时也需要维护索引数据。
不建议建索引的情况
(1) 数据重复度高的字段,比如性别、发货状态
(2) 数据量少的表
(3) where 条件使用不到的字段
为什么建议主键使用自增整型?
回想一下上面说的索引、B+树,它是按顺序排列好的一组数据。如果你的主键是UUID,插入一条数据时,按照从小到大从左到右的判断后,这个主键会被插入B+树的中间,就会导致树分裂、重新排序,性能就很差。自增整型不会使B+树分裂,每新增一个值的时候就往最右下方安放。
尽量减少索引的数量
千万别说,我每个字段都建了索引,怎么还是这么慢呢?
尽量少用或不用 join 联表
数据库底层对联表的算法很复杂,性能很不好。建议不能超过3个join















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









