







最近使用spark简单的处理一些实际中的场景,感觉简单实用,就记录下来了。
场景运用
部门用户业绩表(1000w测试数据)
用户、部门、业绩
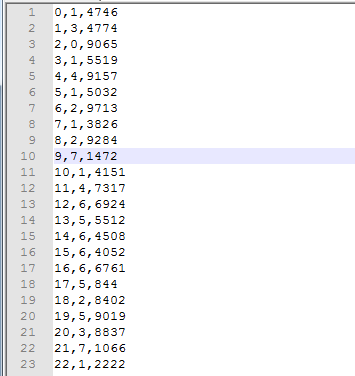
数据加载:
val conf = new SparkConf().setAppName("spark函数").setMaster("local")
val context = new SparkContext(conf)
var data = context.textFile("data.txt")场景1:求每个部门的总业绩,并从大到小排序
data.map(_.split(",")).map(p => (p(1), p(2).toInt)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
//取出部门和业绩字段,对其进行按部门汇总,并进行排序即可。场景2:求每个部门中业绩最高的人
data.map(_.split(",")).map(p => (p(0), p(1), p(2).toInt)).groupBy(_._2)
.map(p => (p._2.map(p => (p._1,p._3)).toArray.maxBy(_._2),p._1))
.sortBy(p => p._1._2, false).map { case ((user, gz), dept) => user + "," + dept + "," + gz }.foreach(println)
//step1:先对部门进行分组
//step2:找出部门中最高业绩和人
//step3:排序,并去除格式加载用户订单表
用户、月份、订单
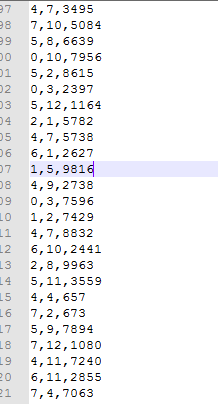
var data1 = context.textFile("/userdt.txt")场景3:求每季度的订单金额
data1.map(_.split(",")).map(p => {
if (p(1).toInt <= 3) {
(1, p(2).toInt)
} else if (p(1).toInt > 3 && p(1).toInt <= 6) {
(2, p(2).toInt)
} else if (p(1).toInt > 6 && p(1).toInt <= 9) {
(3, p(2).toInt)
} else {
(4, p(2).toInt)
}
}).reduceByKey(_ + _).foreach(println)
//这里用if else 对每季度进行了分组,应该可以用match匹配的,个人对match不熟。
//分完组,按组进行汇总即可场景4:求用户每季度订单金额
data1.map(_.split(",")).map(p => {
if (p(1).toInt <= 3) {
(p(0), 1, p(2).toInt)
} else if (p(1).toInt > 3 && p(1).toInt <= 6) {
(p(0), 2, p(2).toInt)
} else if (p(1).toInt > 6 && p(1).toInt <= 9) {
(p(0), 3, p(2).toInt)
} else {
(p(0), 4, p(2).toInt)
}
}).groupBy(p => (p._1, p._2)).map(p => (p._1, p._2.map(p => p._3).reduce(_ + _)))
.map(p => (p._1._1, p._1._2, p._2)).sortBy(p => (p._1, p._2)).foreach(println)
//这里只有月份,有年也是一样,先用filter过滤出那一年,再按季度进行汇总
//根据用户和季度进行分组,再用户和季度的组对金额进行汇总
//格式化数据,并按用户和季度排序场景5:纬度关联,求全国各省份2015年各季度销售业绩
数据表
城市信息表(城市ID,城市,省份)

订单信息表(用户,年份,月份,城市ID,业绩)

var cy = context.textFile("city.txt").map(_.split(",")).map(p => (p(0).toInt, p(2))).collect().toMap
//把城市ID和省份转化成map形式,方便获取
var dd = context.textFile("dingdan.txt").map{p=>
var sp=p.split(",")
var quarter=sp(2).toInt
if(quarter<=3){
quarter=1
}else if(quarter>3 && quarter<=6){
quarter=2
}else if(quarter>6 && quarter<=9){
quarter=3
}else{
quarter=4
}
( sp(1),quarter, sp(3), sp(4))
}.filter(_._1.toInt.equals(2015))
//对月份按季度进行分组,并过滤出2015的订单
var data2 = dd.map(p => (p._1, p._2, cy.getOrElse(p._3.toInt,"其他"),p._4)).groupBy(p=>(p._1,p._2,p._3))
.map(p=>(p._1,p._2.map(_._4.toInt).reduce(_+_))).sortBy(p=>(p._1._3,p._1._1,p._1._2))
.map{case ((year,quarter,area),num)=>area+","+year+","+quarter+","+num}
.foreach(println)
//step1:两表关联,订单的城市ID通过城市纬度表转换成省份
//step2:对年份、季度、省份进行联合分组
//step3:对订单金额进行合计,并按省份、年份、季度进行排序,格式化后输出通过sqlContext(隐式转换的方式)来处理场景,这里只举一个例子
场景:求每个部门中业绩最高的人
val sqlContext=new SQLContext(context)
import sqlContext.implicits._ //隐式转换
case class temptable(id:String,dept:String,sar:Int)
var sql=data.map(_.split(",")).map(p=>temptable(p(0),p(1),p(2).toInt)).toDF()
sql.registerTempTable("deptinfo")
val jh= sqlContext.sql("select a.id,a.sar,a.dept from deptinfo a INNER JOIN (select max(sar) aaa,dept from deptinfo group by dept)b on a.sar=b.aaa and a.dept=b.dept order by a.sar ")
jh.foreach(println)
//把内容转换成临时表,并通过sql直接编写














 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









