






Hadoop 是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
简而言之:
Hadoop是一个开源分布式系统架构
分布式文件系统HDFS——解决大数据存储
分布式计算框架MapReduce——解决大数据计算
分布式资源管理系统YARN
处理海量数据的架构首选
非常快得完成大数据计算任务
已发展成为一-个Hadoop生态圈
为什么使用Hadoop
高扩展性,可伸缩
高可靠性----多副本机制,容错高
低成本.
无共享架构
灵活,可存储任意类型数据
开源,社区活跃
Hadoop发展及版本
Hadoop起源于搜索引擎Apache Nutch
创始人:Doug Cutting
2004年 - 最初版本实施
2008年 - 成为Apache顶级项目
Hadoop发行版本
社区版:Apache Hadoop
Cloudera发行版:CDH
Hortonworks发行版:HDP
Hadoop与关系型数据库对比

Hadoop机理

Hadoop安装及环境配置
首先下载Hadoop,置入虚拟机系统并解压(此处使用的Hadoop是2.6.0版本)

第一步、配置 hadoop-env.sh

第二步、配置core-site.xml

fs.defaultFS配置端口
hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。它默认的位置是在/tmp/{$user}下面,但是在/tmp路径下的存储是不安全的,因为linux一次重启,文件就可能被删除。将其更改后,后续需要重新格式化namenode节点 bin/hadoop namenode -format

第三步、配置hdfs-site.xml

第四步、配置mapred-site.xml

第五步、配置yarn-site.xml

整体步骤:

配置全局变量
命令 vi /etc/profile

添加的全局变量
只需根据自己的hadoop位置修改hadoop_home的值即可
export HADOOP_HOME=/opt/soft/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME

启动hadoop 命令: start-all.sh
查看安装是否成功:
jps命令查看进程
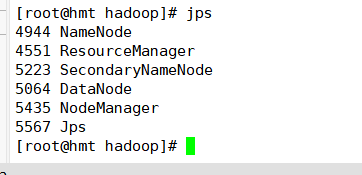
本机访问 http://192.168.56.100:50070 即虚拟机的IP+端口号50070进入监控界面查看
















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









