







MongoDB 开发
MongoDB在数据聚合上有独特的优势:
- 将整合的数据都放在一个document,以空间换取了时间。当然RDBMS也可以整合在一张表里面。这还称不上是颠覆性的优势。关键还是要从无模式来分析。RDBMS的事实表,一旦column固定下来,数据量成年累月的更新,一旦新增一个column会带来很多不必要的开销,比如row overflow, 而Mongo document的更新,你在一个文档中,新增一个子文档,来存储新增的维度表的信息,直观,高效,新增的document直接加载在collection最后,之前的副本删除。
- 有mapreduce的概念:要注意和hadoop的mapreduce的区别。Hadoop的mapreduce是基于分布式的计算框架,有map和reduce两个步骤,简单来说就是先将任务和数据分配到集群中每台计算机上进行运算,接着调用reduce,将计算好的数据聚合在一起。那mongodb的mapreduce,其实也差不多,因为他的mapreduce的input可以是单机的,也可以是sharded的。Sharded的概念,就是分布式存储在集群中的每一台计算机上。而reduce的结果可以是一个document,也可以存储在collection当中,甚至是sharded数据库的collection当中。
以上的两个问题已经引申出来很多的小问题了,比如shard, aggregation, mapreduce 等等。接下来一一将这些问题化解。
Aggregation:
- 聚合的流程框架:像是做ETL一样,数据从一个计算步骤,径流一系列的计算步骤,最终到达一个符合要求的结果集。
- 流程框架中合理的计算表达式:就是指计算步骤的表达,比如归类,分组,计算总和,计算平均等等;
举一个最简单的例子:(摘自mongodb 官方网站)
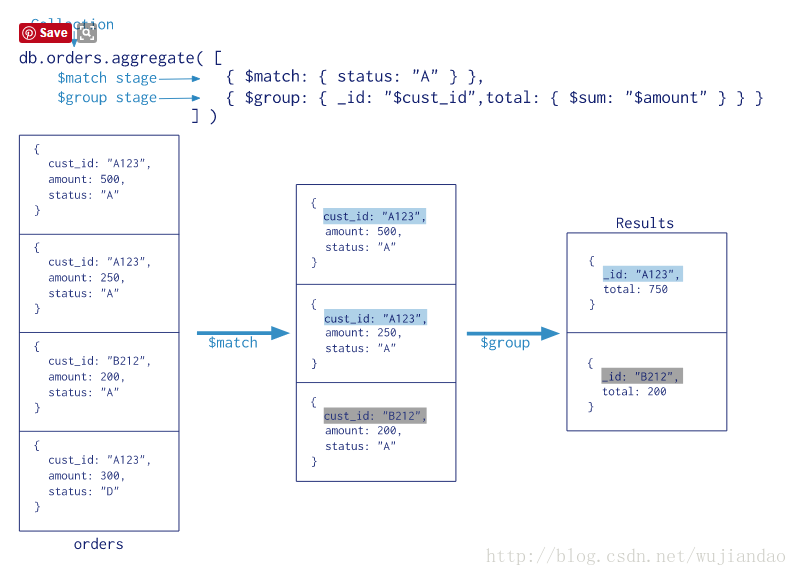
从这个简单的例子中,我们可以看到:
1聚合的框架是:先找到我们需要的document(这里是status等于A的所有document), 然后按照cust_id来计算amount的总量;
2使用的表达式:$match和$group. $match相当于是做查询,$后面跟上关键字就是一个命令或者执行程序(按照ETL中的任务流来理解),用来操作输入的文档
上面是一个简单的数据处理流,我们感兴趣的是,到底有多少这样的数据流命令可以供我们使用呢?这里就需要翻阅MongoDB Online document了,具体的术语称作“Aggregation PipeLine Operators”. 凡是聚合操作,都需要从aggregate()函数开始
暂时可以参考这个地址,但随着MongoDB项目的开发,不保证这个地址长期有效:
我们接着看几个Aggregation PipeLine Operator:
1. $collStats: 使用这个操作符号的时候,一定要放在第一个stage当中(我们把整个数据流分为好几个stage,每一个stage都执行一个计算)。
- 1.1 一个简单的$collStats:
db.expense.aggregate(
{
$collStats: {
latencyStats:{},
storageStats:{}
}
}
)返回的document类似这样:
/* 1 */
{
“ns” : “ecomm.expense”,
“localTime” : ISODate(“2017-05-10T14:19:41.942Z”),
“ns” : “ecomm.expense”,
“latencyStats” : {
“reads” : {
“latency” : NumberLong(8872),
“ops” : NumberLong(2)
},
“writes” : {
“latency” : NumberLong(0),
“ops” : NumberLong(0)
},
“commands” : {
“latency” : NumberLong(0),
“ops” : NumberLong(0)
}
},
“storageStats” : {
“size” : 178600173,
“count” : 1000001,
“avgObjSize” : 178,
“storageSize” : 72847360,
“capped” : false,
“wiredTiger” : {
“metadata” : {
“formatVersion” : 1
},
“creationString” : “access_pattern_hint=none,allocation_size=4KB,app_metadata=(formatVersion=1),block_allocation=best,block_compressor=snappy,cache_resident=false,checksum=on,colgroups=,collator=,columns=,dictionary=0,encryption=(keyid=,name=),exclusive=false,extractor=,format=btree,huffman_key=,huffman_value=,ignore_in_memory_cache_size=false,immutable=false,internal_item_max=0,internal_key_max=0,internal_key_truncate=true,internal_page_max=4KB,key_format=q,key_gap=10,leaf_item_max=0,leaf_key_max=0,leaf_page_max=32KB,leaf_value_max=64MB,log=(enabled=true),lsm=(auto_throttle=true,bloom=true,bloom_bit_count=16,bloom_config=,bloom_hash_count=8,bloom_oldest=false,chunk_count_limit=0,chunk_max=5GB,chunk_size=10MB,merge_max=15,merge_min=0),memory_page_max=10m,os_cache_dirty_max=0,os_cache_max=0,prefix_compression=false,prefix_compression_min=4,source=,split_deepen_min_child=0,split_deepen_per_child=0,split_pct=90,type=file,value_format=u”,
“type” : “file”,
“uri” : “statistics:table:collection-0-4591982809928228630”,
…(这里省去其他)
这里的聚合,相当于是对整个服务器的一个总体统计信息的抽取,并没有实现业务数据层面的聚合,可能会有其他用途,暂不明朗。
文档中说到,针对latencyStats, storageStats以及各自的子文档属性,都是可选的,也就是说,我们可以只查询其中一个感兴趣的属性字段,比如,我们只要查询storage的统计信息,只要这样查询:
db.expense.aggregate( {
$collStats:{
storageStats:{}
} } )
得到这样的结果文档:
{
“ns” : “ecomm.expense”,
“localTime” : ISODate(“2017-05-10T14:35:15.908Z”),
“storageStats” : {
“size” : 178600173,
“count” : 1000001,
“avgObjSize” : 178,
“storageSize” : 72847360,
“capped” : false,
“wiredTiger” : {
“metadata” : {
“formatVersion” : 1
},
“creationString” : “access_pattern_hint=none,allocation_size=4KB,app_metadata=(formatVersion=1),block_allocation=best,block_compressor=snappy,cache_resident=false,checksum=on,colgroups=,collator=,columns=,dictionary=0,encryption=(keyid=,name=),exclusive=false,extractor=,format=btree,huffman_key=,huffman_value=,ignore_in_memory_cache_size=false,immutable=false,internal_item_max=0,internal_key_max=0,internal_key_truncate=true,internal_page_max=4KB,key_format=q,key_gap=10,leaf_item_max=0,leaf_key_max=0,leaf_page_max=32KB,leaf_value_max=64MB,log=(enabled=true),lsm=(auto_throttle=true,bloom=true,bloom_bit_count=16,bloom_config=,bloom_hash_count=8,bloom_oldest=false,chunk_count_limit=0,chunk_max=5GB,chunk_size=10MB,merge_max=15,merge_min=0),memory_page_max=10m,os_cache_dirty_max=0,os_cache_max=0,prefix_compression=false,prefix_compression_min=4,source=,split_deepen_min_child=0,split_deepen_per_child=0,split_pct=90,type=file,value_format=u”,
“type” : “file”,
“uri” : “statistics:table:collection-0-4591982809928228630”,
“LSM” : {
“bloom filter false positives” : 0,
“bloom filter hits” : 0,
“bloom filter misses” : 0,
“bloom filter pages evicted from cache” : 0,
“bloom filter pages read into cache” : 0,
“bloom filters in the LSM tree” : 0,
“chunks in the LSM tree” : 0,
“highest merge generation in the LSM tree” : 0,
“queries that could have benefited from a Bloom filter that did not exist” : 0,
“sleep for LSM checkpoint throttle” : 0,
“sleep for LSM merge throttle” : 0,
“total size of bloom filters” : 0
},
…(其中省去其他冗余部分)
- 1.2 $collStats{}只能是第一个pipeline command,否则出错,我们可以看到错误信息如下:
db.expense.aggregate(
{
$match:{"item":"fund"}
},
{
$collStats:{
storageStats:{}
}
}
)
2 $Project: 用来抽取特定的字段或者自定义表达式的字段
db.expense.aggregate({$project:{"expense_date":1,"item":1,"exp_value":1,"flag":"active","loaded":new Date()}}){
“_id” : ObjectId(“58c4eeb051a694470c175658”),
“expense_date” : ISODate(“2002-10-09T00:00:00.000Z”),
“item” : “fund”,
“exp_value” : 0.0,
“flag” : “active”,
“loaded” : ISODate(“2017-05-10T14:52:34.197Z”)
}
- 2.1 Expressions & $literal
在$project中,我们会逐渐接触到表示式和要直接表达true/false, 1/0的字段,这两类值,经常被解析为是否抽取某一个字段,因此需要特别处理。
我们先看一个没有加$literal表达式的例子:
db.expense.aggregate({$project:{"expense_date":1,"item":1,"exp_value":1,"active":1}}){
“_id” : ObjectId(“58c4eeb051a694470c175658”),
“expense_date” : ISODate(“2002-10-09T00:00:00.000Z”),
“item” : “fund”,
“exp_value” : 0.0
}
再看加上$literal的例子:
db.expense.aggregate({$project:{"expense_date":1,"item":1,"exp_value":1,"active":{$literal:1}}}){
“_id” : ObjectId(“58c4eeb051a694470c175658”),
“expense_date” : ISODate(“2002-10-09T00:00:00.000Z”),
“item” : “fund”,
“exp_value” : 0.0,
“active” : 1.0
}
如果没有active这个字段,我们使用$literal之后就能将这个字段计算并且附到结果集里面。
如果$literal子文档里面加$literal会怎么样呢:
db.expense.aggregate({$project:{"expense_date":1,"comment":{$literal:{$literal:1}}}}){
“_id” : ObjectId(“58c4eeb051a694470c175658”),
“expense_date” : ISODate(“2002-10-09T00:00:00.000Z”),
“comment” : {
“$literal” : 1.0
}
}
$literal其实就是一个表达式,用来执行特殊操作的表达式。更常规的表达式,我们可以选几个来看看:
db.expense.aggregate({$project:{"expense_date":1,"comment":{$literal:{$literal:1}},"exp_value":1,"allamount": {$multiply:[ "$exp_value",100]}}}){
“_id” : ObjectId(“58c4eeb051a694470c175658”),
“expense_date” : ISODate(“2002-10-09T00:00:00.000Z”),
“exp_value” : 0.0,
“comment” : {
“$literal” : 1.0
},
“allamount” : 0.0
}
/* 2 */
{
“_id” : ObjectId(“58c4eeb051a694470c175659”),
“expense_date” : ISODate(“2001-01-01T00:00:00.000Z”),
“exp_value” : 1.0,
“comment” : {
“$literal” : 1.0
},
“allamount” : 100.0
}
这个地方尤其要注意,表达式后面一定是加【】,而不是{}。 而$literal是加{}的,所以和普通的表达式也还有所不同。
















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











