







本文旨在简要介绍2023年PR录用的论文题为“Self-information of radicals: A new clue for zero-shot Chinese character recognition”的主要研究成果。论文以信息论的视角分析了部首在汉字识别中的重要性,提出了一种基于原型学习的特征提取网络,并针对:(1)基于序列匹配的识别方法,提出了汉字不确定性消除框架(CUE);(2)基于属性嵌入的识别方法,提出了一种新颖的部首信息嵌入方法(RIE)。研究表明,本文在绝大多数汉字零样本识别任务的数据集上达到了最先进水平(SOTA)。
一、研究背景
基于部首的零样本汉字识别(ZSCCR)方法可分为两类:基于序列匹配和基于属性嵌入。基于序列匹配的方法要求模型具备出色的部首定位和识别能力,同时模型识别部首的顺序对识别结果具有重要影响。此外,在ZSCCR任务中,以往的方法通常假设所有部首对模型的识别贡献相等,忽略了罕见部首对识别结果的影响。因此,本文提出了汉字不确定性消除框架(CUE)和一种基于信息量的部首信息嵌入方法(RIE)以应对上述问题。
二、前沿知识
表意文字描述序列(IDS)是一种汉字表示法,它包括了汉字的部首以及结构符号。每个汉字都可以用一个独特的IDS表示。对于GB18030标准中的27,533类汉字,总共涵盖了500个部首和12种部首结构。
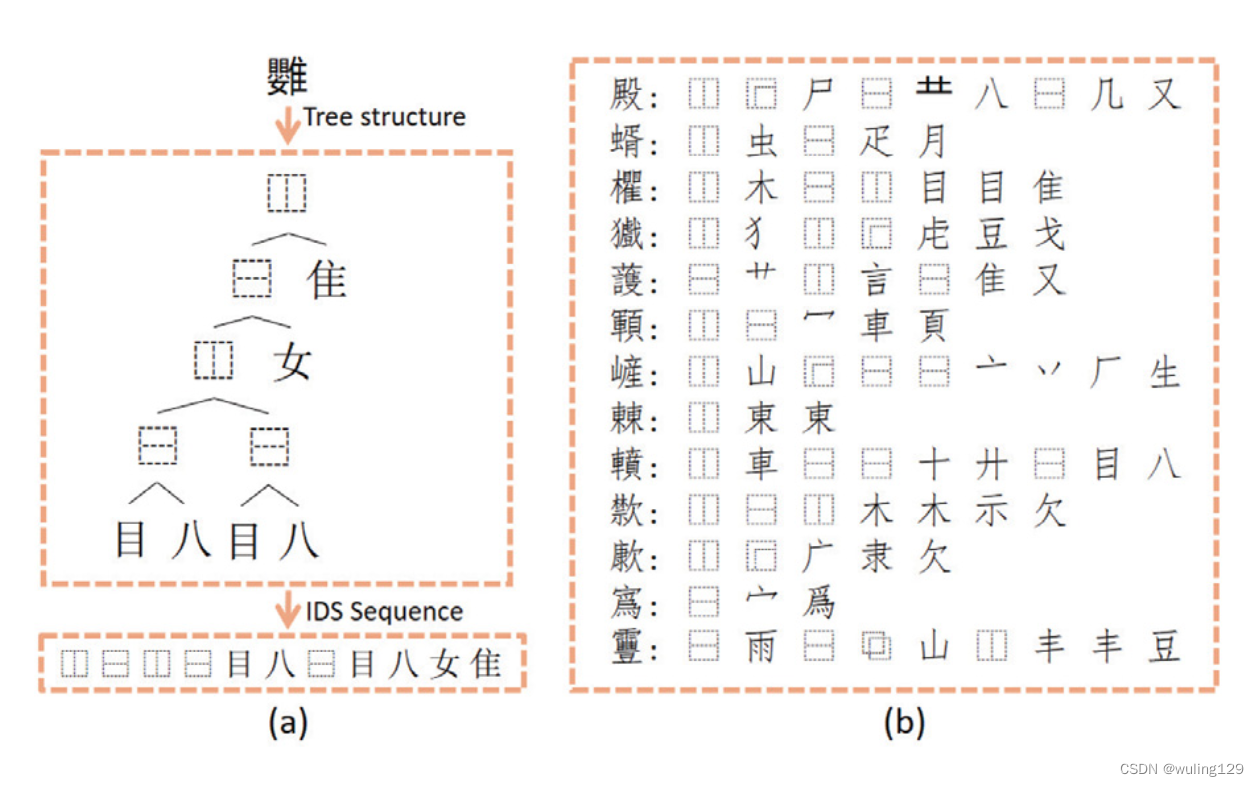
图 1 (a) 汉字到IDS序列的转换过程。(b) IDS字典中13个汉字的IDS序列。
三、方法原理简述
本文提出的方法基于部首的自信息量(SIR)分析了部首在汉字识别中的重要性,并将SIR方法应用到基于序列匹配的方法和基于属性嵌入的方法中,分别提出了字符不确定性消除框架(CUE)和部首信息嵌入法(RIE)。
(1)部首自信息量(SIR)。SIR是从信息论的角度来分析部首在识别过程中的重要性的指标。根据信息论的原理,越是罕见的部首所带来的信息量越大,因此对字符识别的贡献也越显著。SIR的表达方式如下:
![]()
其中代r表部首,p(r)代表部首出现的概率。
(2)无位置标签序列(PCS)。以往的研究通常使用IDS序列作为训练标签,以指导模型的训练过程。然而,IDS序列对部首有严格的顺序约束,这会限制模型按照顺序进行预测,却忽略了模型的不可预测性。因此,本文提出了PCS序列作为训练标签来引导训练过程。简单来说,PCS序列是通过对IDS序列进行排列组合得到的,图2展示了PCS序列的示例。
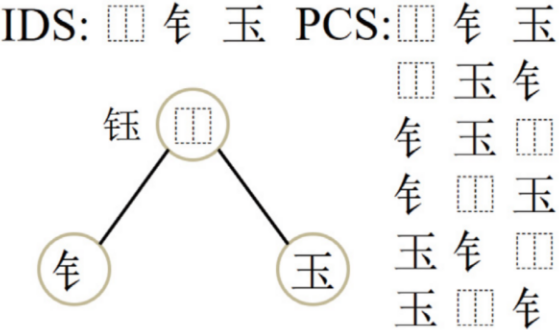
图 2 IDS序列与PCS序列
(3)基于序列匹配的方法(CUE)。图3是本文提出基于序列匹配的方法的整体结构。其中包括两个阶段:部首识别阶段和解码阶段。
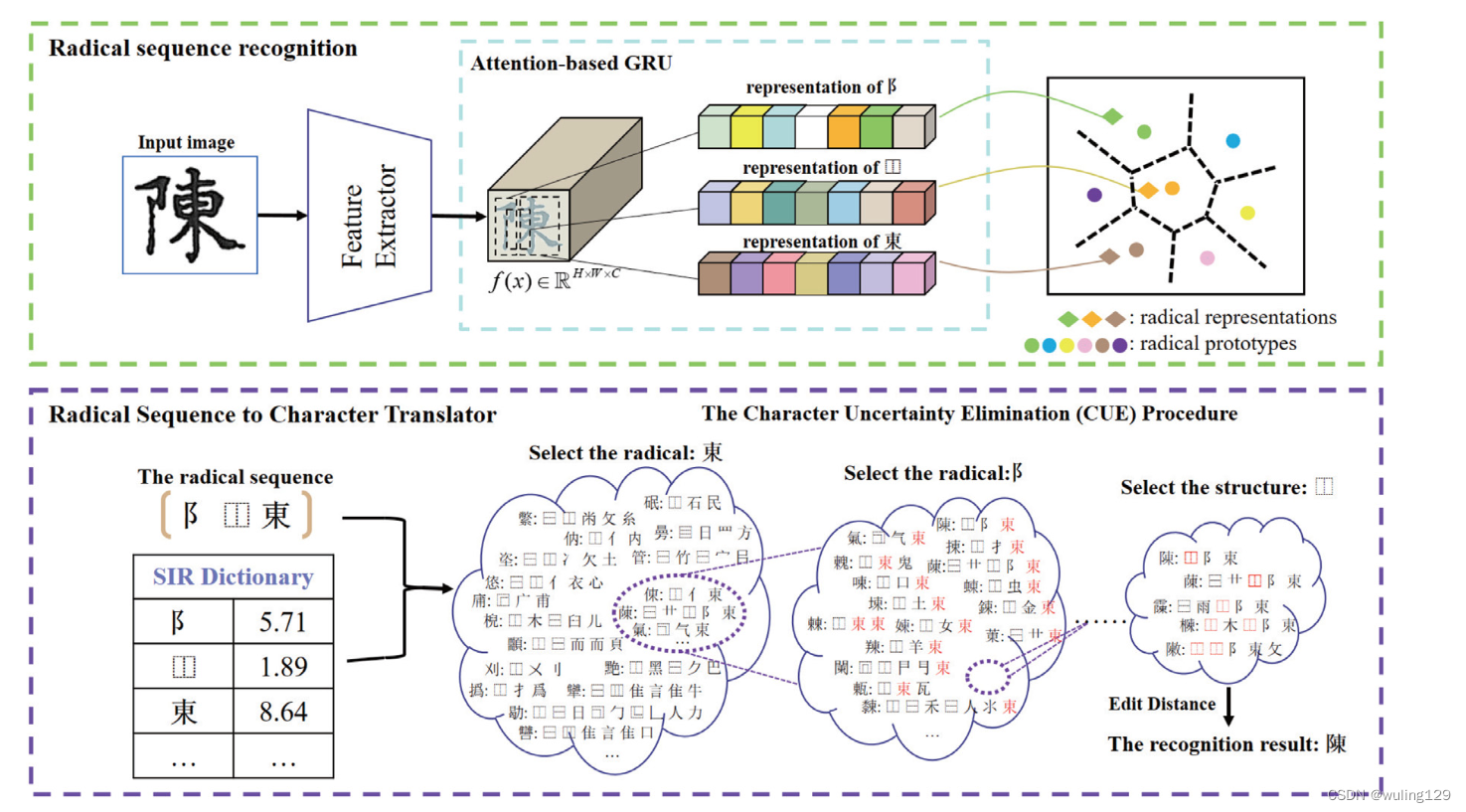
图 3 为 CUE框架图。部首识别网络(上);CUE流程(下)
在部首识别阶段,本文构建了一个基于原型学习的部首提取网络。该网络采用了DenseNet[1]作为局部特征提取器和Non-local Module[2]作为全局特征提取器。这两个特征提取网络的输出被相加并输入到GRU进行解码。最后,解码结果与可训练的部首原型进行匹配,选择编辑距离最小的原型作为输出结果。
在解码阶段,本文提出了CUE方法,用于引导解码过程。根据信息论的原理,字符类别的不确定性(条件熵)可以表示为:
![]()
其中x表示字符样本,C表示所有汉字类别的集合,p(c|x)表示给定给定x的类别c的后验概率。
在中C,用表示候选字符类别集(下称候选集),用
表示非候选字符类别集。初始情况下,
包含所有类别的字符,并假设每类字符的后验概率相等。本文假设候选字符类别集
的后验概率分布服从均匀分布,而非候选字符类别集
的概率为零。因此,字符类别的不确定性可以重写为:
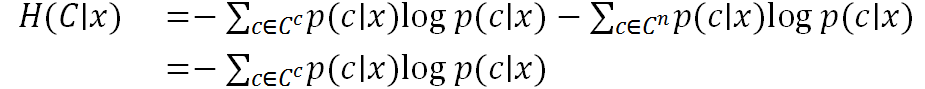
每个部首仅存在于特定的汉字集合中。模型输出的部首序列有助于从候选集中排除不相关的类别,从而改变候选集的分布,逐步减少预测字符的不确定性。字符的不确定性可通过以下公式进行更新。
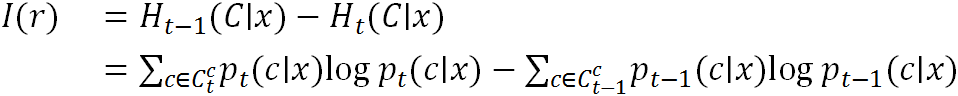
CUE框架的伪代码如图4所示。在每个时间步,迭代选择当前SIR值(信息量)最大的部首,并从候选集中剔除不包含该部首的类别。通过不断地迭代更新候选集,可以逐步减少字符的不确定性,直至候选集中仅剩唯一解。如果在迭代结束时,候选集中仍存在多个解,那么需要使用编辑距离来确定最终的结果。值得注意的是,在大多数情况下,CUE框架并不需要遍历整个预测的部首序列,就可以得到最终结果,如图5所示。

图 4 CUE模块伪代码
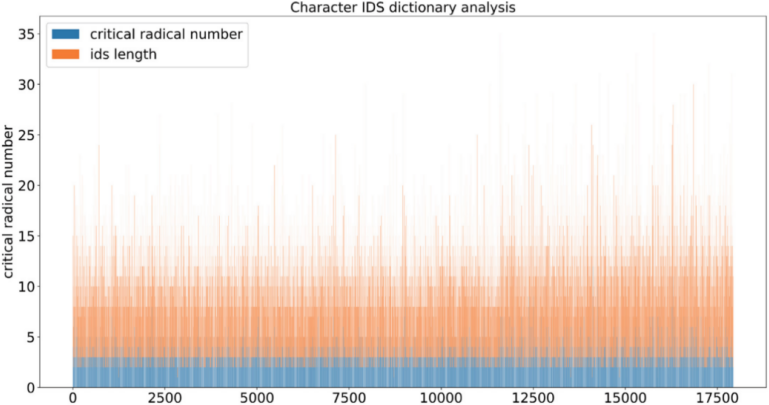
图 5 预测使用的部首数(蓝色) VS 字符的部首数(橙色)
(4)部首信息嵌入法(RIE)。本文以IDS和SIR为基础,提出了一种基于属性嵌入的方法。首先,为每个部首分配了一个One-hot编码,并将其与相应部首的SIR值相乘。接下来,根据IDS将所有部首的编码组合在一起,最终形成了每个字符的独特编码表示。RIE编码的制作过程可以表示为:
![]()
其中表示字符类别c的IDS序列,
表示部首i的SIR值。
四、实验结果
本文在三个常用的ZSCCR数据集上进行了实验,包括HWDB1.0-1.1 [3]、ICDAR2013 [4]和CTW [5]。本文还在AHCDB[6]数据集上评估了模型识别古籍文字的能力。
(1)原型学习和CUE模块的消融实验。

使用基于原型学习的部首提取网络和CUE框架都能提升模型性能。
(2)PCS和Non-local Module的消融实验。
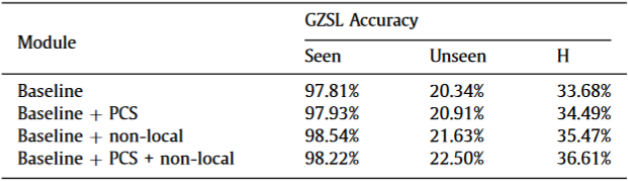
验证了PCS和Non-local Module的有效性。
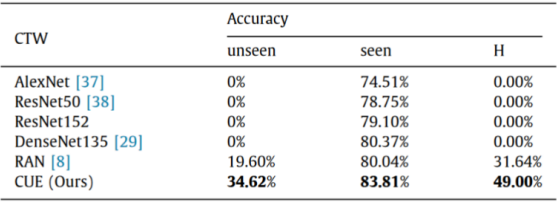
(3)零样本汉字识别实验。本文在ICDAR2013和CTW数据集上进行了零样本汉字识别实验,展示了CUE框架出色的性能。CUE框架的优异性能可能源于两个方面的因素:1)采用了基于原型学习的部首识别网络,提升了模型的鲁棒性;2)结合SIR方法,增强了模型对部首的判别能力。
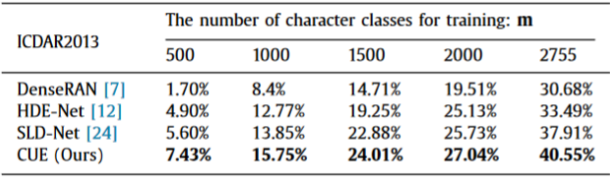
(4)古籍数据集中的部首零样本识别(RZS)实验。RZS问题(即一些部首在训练中未出现过)在古籍文字识别任务中非常常见。因此,本文在AHCDB数据集上进行了RZS实验。实验结果表明,CUE框架的性能明显优于SLD-Net[7]。

(5)古籍数据集中的零样本识别实验。实验结果表明,RIE方法在零样本识别方面表现良好,性能优于HDE-Net[8]。观察实验结果可以发现,当训练数据较少时,RIE方法表现出更佳的性能。然而,随着训练数据的逐渐增加,CUE框架的性能迅速提升,并超过其他方法。这一结果侧面说明了基于序列匹配的方法相较于基于属性嵌入的方法更依赖于训练数据的规模。

(6)已见汉字实验。本文提出的CUE方法可以与以往的SOTA方法达到相近的性能。

五、总结
本文以信息论的视角分析了部首在汉字识别中的重要性,并引入了SIR(部首自信息量)。基于SIR,本文提出了CUE框架,旨在从消除不确定性的角度来识别汉字。此外,本文还将SIR嵌入到汉字的语义向量中,提出了部首信息嵌入法(RIE)。实验结果表明,相较于最先进的方法,本文提出的方法可以实现相当甚至更高水平的性能。
论文地址: https://www.sciencedirect.com/science/article/abs/pii/S0031320323002996


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









