







1下载zookeeper-3.4.5.tar.gz,hbase-1.0.1.1.tar.gz安装包
解压ZooKeeper安装包,并将解压后的文件夹名称改为zookeeper:
(1) 上传ZooKeeper安装包到 /usr/local/hadoop-2.6.0/,我这里使用的是3.4.5版本:
(2) 解压ZooKeeper安装包,并将解压后的文件夹名称改为zookeeper
执行命令
$tar-zvxf zookeeper-3.4.5.tar.gz
$mv zookeeper-3.4.5 zookeeper
同样解压hbase-1.0.1.1.tar.gz 改名 hbase
本机的软件信息如下
hadoop-2.6.0
zookeeper-3.4.6
hbase-1.0.1.1
2集群组成
| ServerName | Hadoop Cluster | Zookeeper | HBase Cluster |
| server1 | Name node & Resource manager,secondary name node | yes | master |
| server2 | Data node & Node manager | yes | Region server |
| server3 | Data node & Node manager | yes | Region server |
| server4 | Data node & Node manager | yes | Region server |
3 配置zookeeper
$cd zookeeper/conf/
$mv zoo-sample.cfg zoo.cfg
3.1修改zoo.cfg内容
tickTime=2000
dataDir=/home/hadoop/zookeeperdata
clientPort=2181
initLimit=5
syncLimit=2
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
server.4=server4:2888:3888
注:
tickTime :心跳时间,单位毫秒。
同时tickTime又是zookeeper中的基本单位,比如后面的initLimit=5就是指5个tickTime时间,在这里是10秒。
dataDir :存储数据信息的本地目录
然后把zookeeper文件夹连同修改后的配置文件通过scp拷贝到另外两台机器(server1,server2,server3)上。
在所有机子上需要创建dataDir中配置的目录
执行命令
$mkdir /home/hadoop/zookeeperdata
3.2设置myid
server1上执行命令$echo ”1” >/home/hadoop/zookeeperdata/myid
server2上执行命令$echo “2” >/home/hadoop/zookeeperdata/myid
server3上执行命令$echo ”3” >/home/hadoop/zookeeperdata/myid
server4上执行命令$echo ”4” >/home/hadoop/zookeeperdata/myid
3.3 启动/关闭
启动执行命令
$cd /usr/local/hadoop-2.6.0/zookeeper
$bin/zkServer.sh start
启动和关闭命令必须到zookeeper集群的每个机器上,没有像start-dfs.sh那样的命令可以一下子把整个集群启动。
关闭执行命令
$bin/zkServer.sh stop
3.4测试zookeeper
$bin/zkServer.sh status
以下是结果示例,可以看到各机器的角色是follower还是leader。
在server1上执行
[hadoop@server1 zookeeper]$ zkServer.sh statusJMX enabled by default
Using config: /usr/local/hadoop-2.6.0/zookeeper/bin/../conf/zoo.cfg
Mode: follower
在server2上执行
[hadoop@server2 ~]$ zkServer.sh statusJMX enabled by default
Using config: /usr/local/hadoop-2.6.0/zookeeper/bin/../conf/zoo.cfg
Mode: follower
在server3上执行
[hadoop@server3 ~]$ zkServer.sh statusJMX enabled by default
Using config: /usr/local/hadoop-2.6.0/zookeeper/bin/../conf/zoo.cfg
Mode: leader
在server4上执行
[hadoop@server4 ~]$ zkServer.sh status
JMX enabled by default
Using config: /usr/local/hadoop-2.6.0/zookeeper/bin/../conf/zoo.cfg
Mode: follower
3.5配置zookeeper环境变量。
由于zookeeper必须单独在每台机器上启动,为了避免每次我们都要切换目录到安装目录去执行bin命令,我们可以配置环境变量,如下:
在/etc/profile下面添加zookeeper环境变量
ZOOKEEPER_HOME=/usr/local/hadoop-2.6.0/zookeeper
PATH=$ZOOKEEPER_HOME/bin:$PATH
export ZOOKEEPER_HOME
export PATH
4安装Hbase
4.1配置hbase-env.sh
$cd /usr/local/hadoop-2.6.0/hbase
进入conf目录里面都是配置文件。
hbase-env.sh
其它不变,export HBASE_MANAGES_ZK=false,这表示不使用hbase自带的zookeeper,而使用外部的zookeeper(这里指我们在上面建的zookeeper),并且将我们的jdk目录填写上去。
export JAVA_HOME=/usr/lib/java/jdk1.8.0_121
export HBASE_MANAGES_ZK=false
4.2 hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://server1:9000/hbase</value>
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>Property from ZooKeeper's config zoo.cfg. The port at which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>server1,server2,server3,server4</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/hbasedata</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
</configuration>4.3 regionservers
server2,server3,server45:hbase启动/关闭
5.1:同样配置hbase 环境变量
HBASE_HOME=/usr/local/hadoop-2.6.0/hbase
PATH=$HBASE_HOME/bin:$PATH
export HBASE_HOME
export PATH
HBASE_HOME=/usr/local/hadoop-2.6.0/hbase
PATH=$HBASE_HOME/bin:$PATH
export HBASE_HOME
export PATH要记得关掉防火墙
执行命令
#systemctl stop firewalld
启动顺序如下
先zookeeper, zkServer.sh start,这个所有机器上都要做
然后启动hadoop, start-dfs.sh, start-yarn.sh,只做首机就行
然后启动hbase, start-hbase.sh,只做首机
然后在每台机器上执行下jps看看是不是都启动了。
关闭顺序
首机执行stop-hbase.sh
每台执行zkServer.sh stop
首机执行stop-yarn.sh
首机执行stop-dfs.sh
然后在每台机器上执行下jps查看进程
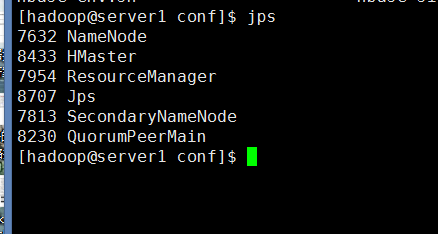
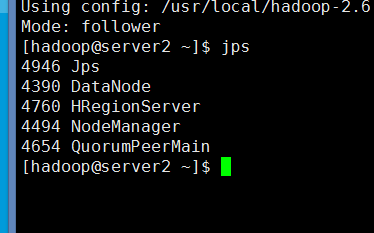
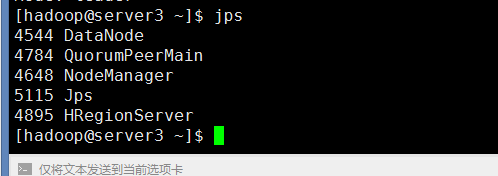
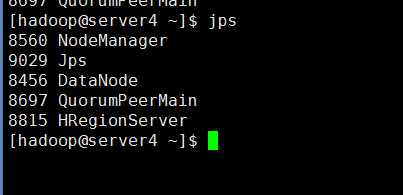
6:测试Hbase
可以用hbase hbck命令来看一下状态。
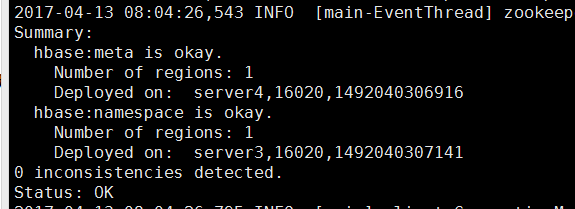
7: 注意事项
HBase集群需要依赖于一个Zookeeperensemble。
HBase集群中的所有节点以及要访问HBase的客户端都需要能够访问到该Zookeeper ensemble。
此外,Zookeeper ensemble一般配置为奇数个节点,并且Hadoop集群、Zookeeper ensemble、HBase集群是三个互相独立的集群,并不需要部署在相同的物理节点上,他们之间是通过网络通信的。
Hbase不需要mapreduce,所以只要start-dfs.sh启动hdfs,然后到zookeeper各节点上启动zookeeper,
最后再hbase-start.sh启动hbase即可.















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









