






 文章讲述了面对工单系统性能问题,通过识别冷热数据并进行分离存储,利用定时触发和实时监控实现数据迁移,以提高查询响应速度。设计了数据标记、迁移过程中的错误处理以及使用场景的解决方案。
文章讲述了面对工单系统性能问题,通过识别冷热数据并进行分离存储,利用定时触发和实时监控实现数据迁移,以提高查询响应速度。设计了数据标记、迁移过程中的错误处理以及使用场景的解决方案。
以下是对《从程序员到架构师》一书的案例整理。
问题场景
1.有一个工单处理系统,数据库采用的是MySQL。运行一段时间后,工单表中的数据达到了几千万,工单处理明细表的数据达到了亿级,导致工单列表页面查询要10s左右才能响应。
2.每天大概产生3万条新工单数据,业务人员会查询未处理的工单,并将工单指派给自己进行处理。
3.已闭环的工单不会再更改,一般闭环超过一个月的工单就很少查询。
需求描述
优化未闭环工单的查询响应时长,在1s内响应。
设计思路
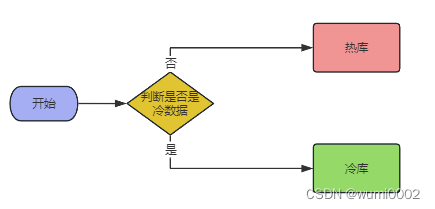
1.工单有两类状态,一个是已闭环,一个是未闭环。业务人员经常查询的是未闭环的工单,而一般闭环超过一个月的工单就不再查询,且这部分数据不会再变动。所以我们将这部分不经常查询且已经固定的数据称之为冷数据,而经常查询且会变更的数据称之为热数据。
2.区分数据之后,我们就可以将冷热数据进行分开存储,将冷数据放到一个新的MySQL数据库中,这样热数据的数据量在几百万以内,加上索引的一些优化,可以达到性能要求。
核心功能
针对这个场景,我们先识别出要实现的核心功能有哪些?
1.如何识别出哪些是冷数据?
2.如何触发数据迁移?
3.如何实现冷热数据分离?
4.历史冷数据如何迁移?
5.如何使用冷热数据?
实现方案
如何识别出哪些是冷数据?
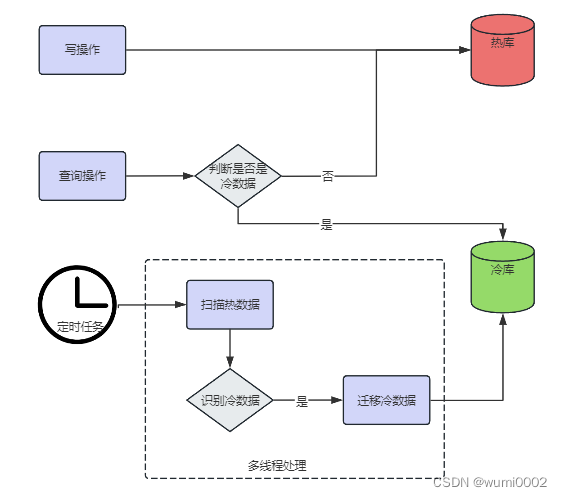
工单表中有【状态】、【关闭时间】字段,通过判断【状态】= 已闭环 and 【当前时间】- 【关闭时间】>= 1个月的数据则为冷数据。
如何触发数据迁移?
常见的数据迁移有两种方式,一种是及时触发,一种是定时触发。
- 及时触发有两种实现方式。
- 一种是侵入到业务代码中,当业务达到数据迁移条件之后,调用数据迁移的方法。优点是迁移实时性高;缺点是代码侵入强,对于业务复杂或者陈旧的系统不友好,代码耦合。
- 另一种是通过监听MySQL日志的方式,当数据表发生变动后,会发布一个消息出来,服务再去消费这个消息,进行数据迁移。优点是迁移的实时性高,不侵入业务代码,可完全独立;缺点是要引入三方中间件,增加了架构的复杂性。
这两种方式都无法进行基于时间的判断。
- 定时触发就是通过定时任务实现,每隔一段时间去扫描数据表,过滤满足迁移条件的数据进行迁移。优点是可以进行基于时间的判断,比如判断闭环时间是否超过一个月;缺点是会迁移会有延迟。
结合这个案例的场景,因为冷数据要是满足闭环时间超过一个月的条件,所以我们通过定时触发的方式来实现数据迁移。
实现实现冷热数据分离?
数据迁移核心步骤有三步:
- 标记冷数据。
在工单表中添加字段data_flag,当满足冷数据条件时,设置data_flag = 1,表示该数据为冷数据。 - 将冷数据迁移至新库中。
- 将冷数据从旧库中删除。
- 如何保证迁移的数据正确、不丢失、不重复?
由于这里要操作两个数据库,无法保证事务性,任意一步都有可能失败,当每一步发生异常的时候,我们应该如何补救呢?
若第一步失败,则在下次定时任务执行的时候,重新标记冷数据。
若第二步失败,则在下次定时任务的执行的时候,查询所有data_flag = 1的数据再做第二步迁移,这里面将包含新标记的冷数据,也包含以前标记但是迁移失败的数据。
若第三步失败,此时冷数据已经迁移至新库中但是还保留在旧库中,那我们在下一次定时任务执行的时候,再做一次第二步的迁移,所以第二步操作要保证幂等性,在插入冷数据之前先判断是否已经插入过。
经过以上的处理,我们就可以保证迁移的数据正确、不丢失、不重复。 - 大数据量情况下如何提升迁移速度?
创建一个线程池,按照线程数量,将待迁移的数据以创建时间为维度进行分区,每个线程负责迁移不同区间的部分数据,确保每个线程处理的数据互不重叠。
历史冷数据如何迁移?
通过定时任务,识别出所有的冷数据,并通过线程池,批量进行迁移。
如何使用冷热数据?
业务上将冷热数据的查询区分开来,要么查询热数据,要么查询冷数据。
方案使用场景
- 数据归档之后就不再修改。
- 不同时读取冷热数据。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









