




 本文深入探讨了Python中字典(dict)的各种特性和用法,包括字典的基本概念、创建方式、常见操作、遍历方法、内置函数及应用场景等。通过具体实例介绍了如何利用字典进行高效的数据处理,如单词计数和网页排名算法。
本文深入探讨了Python中字典(dict)的各种特性和用法,包括字典的基本概念、创建方式、常见操作、遍历方法、内置函数及应用场景等。通过具体实例介绍了如何利用字典进行高效的数据处理,如单词计数和网页排名算法。
引言
今天来梳理一下Python dict 类型的知识点,更多 Python 基础系列,请参考 Python 基础系列大纲
内容提要:
- dict 特征
- dict 创建
- dict 操作
- dict 遍历
- dict 其它方法
- dict 性能
- dict 应用
单词计数
Google 搜索给页面打分
dict 特征
dict 是键值对 item 的集合

dic 是可变的
dic 的 item 可以更新
Key 键是不可变类型而且是唯一的
Key 是一个可变类型

key 不可能是 list, set,因为他们是可变 mutable 类型,不可哈希 hash 的
d1 = {['script']:'java'} # error unhashable type: 'list'
d2 = {{'A', 'B', 'C'}:'all grades'} # error unhashable type: 'list'
key 可以为 bool, str, tuple,int, float
d_bool_key = {True : 5}
d_str_key = {'name': 'kelly'}
d_int_float_key = {9 : 'score', 3.7 : 'gpa'}
d_tuple_key = {('first', 'last') : ('kelly', 'xia')}
Keys 键值是唯一的 UNIQUE
键值相同的情况,最后一个值会覆盖前面的值。

d1 = {'name':'kelly','name':'peter','name':'bob' }
d2 = {'first':'Smith', 'last':'Smith'}
print(d1)
print(d2)
# output:
{'name': 'bob'}
{'first': 'Smith', 'last': 'Smith'}
键值可以是异类 Heterogeneous 类型**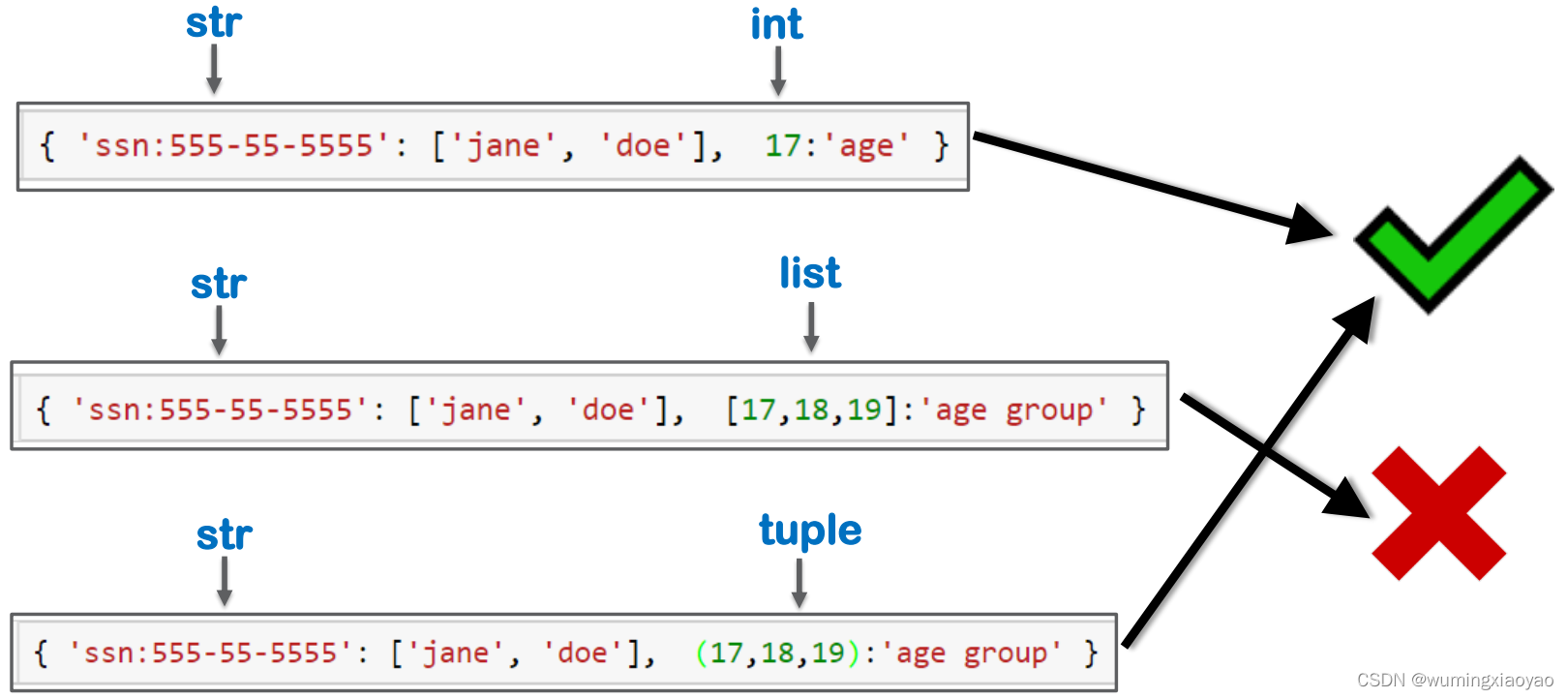
dict 对象 d 中的 key 有 str 和 tuple
d = {'ssn: 555-55-5555':['jane', 'doe'], (16,17,18):'age group'}
print(d)
# output:
# {'ssn: 555-55-5555': ['jane', 'doe'], (16, 17, 18): 'age group'}
Key 键是按插入顺序排的,并不是按字母数字排序
所以不能按 index 索引访问 dict item
dict 创建

-
empty dict
d = dict()
d = {} -
d = {key : value}
d1 = {'key1':'value1', 'key2':'value2'}
d1
# output:
# {'key1': 'value1', 'key2': 'value2'}
不支持: dict(‘key’:‘value’)
d = dict('key':'value')
d
# output:
# File "<ipython-input-640-efaed8bcc2a7>", line 1
# d = dict('key':'value')
# ^
# SyntaxError: invalid syntax
- d=dict(key_name=value_object)
d2 = dict(key1='value1', key2='value2')
d2
# output:
{'key1': 'value1', 'key2': 'value2'}
- d = dict([tuple, tuple])------via tuple list
d_2_tuple_list = dict([('script', 'python'), ('version', 3.8)])
d_1_tuple_list = dict([('script', 'python')])
print('d_2_tuple_list: {}'.format(d_2_tuple_list))
print('d_1_tuple_list: {}'.format(d_1_tuple_list))
# output:
# d_2_tuple_list: {'script': 'python', 'version': 3.8}
# d_1_tuple_list: {'script': 'python'}
- 不支持: d = dict(tuple)
d = dict(('a', 'b'))
d
# output:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-633-423a7c460802> in <module>
----> 1 d = dict(('a', 'b'))
2 d
ValueError: dictionary update sequence element #0 has length 1; 2 is required
- {tuple}----set
d_2_tuple = {('script', 'python'), ('version', 3.8)}
d_1_tuple = {('script', 'python')}
print('d_2_tuple: {}'.format(d_2_tuple))
print('d_1_tuple: {}'.format(d_1_tuple))
# output:
d_2_tuple: {('script', 'python'), ('version', 3.8)}
d_1_tuple: {('script', 'python')}
- 不支持: d = {[tuple, tuple]}
d = {[('script', 'python'), ('version', 3.8)]}
d
# output:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-612-db86a05588ef> in <module>
----> 1 d = {[('script', 'python'), ('version', 3.8)]}
2 d
TypeError: unhashable type: 'list'
- d=dict.fromkeys(key sequence, value)
keys = {'peter', 'bob', 'bruce'}
d1 = dict.fromkeys(keys, ['male', 'smoking', 30])
d2 = dict.fromkeys(keys, 30)
print('d1: {}'.format(d1))
print('d2: {}'.format(d2))
# output:
d1: {'bob': ['male', 'smoking', 30], 'peter': ['male', 'smoking', 30], 'bruce': ['male', 'smoking', 30]}
d2: {'bob': 30, 'peter': 30, 'bruce': 30}
- d = dict(zip(collection1, collection2)
zip_3_3 = zip(['one', 'two', 'three'], [1,2,3])
zip_4_3 = zip(['one', 'two', 'three', 'four'], [1,2,3])
zip_3_4 = zip(['one', 'two', 'three'], [1,2,3,4])
d33 = dict(zip_3_3)
d43 = dict(zip_4_3)
d34 = dict(zip_3_4)
print('d33: {}'.format(d33))
print('d43: {}'.format(d43))
print('d34: {}'.format(d34))
只输出两个 collection 匹配成功的对数
# output:
d33: {'one': 1, 'two': 2, 'three': 3}
d43: {'one': 1, 'two': 2, 'three': 3}
d34: {'one': 1, 'two': 2, 'three': 3}
- 字典的推导式 创建
dic = {str(i) : i*2 for i in range(4)}
print(dic)
# output:
{'0': 0, '1': 2, '2': 4, '3': 6}
作业: 哈哈,巩固成果的时候到了。


dict 操作
访问 Access

图例:

key 不存在会 unknown key error
info_dict = {} # do not miss this statement, or name 'info_dict' is not defined
key = 'name'
info_dict [key] = 'kelly'
print(info_dict [key])
print(info_dict ['unkonwnKey'])
# output:
kelly
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-644-de1581161396> in <module>
3 info_dict [key] = 'kelly'
4 print(info_dict [key])
----> 5 print(info_dict ['unkonwnKey'])
KeyError: 'unkonwnKey'
get(key, [default]) key 找不到对应的 value 会用默认的 value,但是这个默认的 value 是不会加到原来的 dict 里
d = {'first': 'kelly', 'last':'Xu'}
print('d.keys:\n{} '.format(d.keys()))
print('d.values:\n{} '.format(d.values()))
print('d.items:\n{} '.format(d.items()))
print('d.get("first"):\n{} '.format(d.get('first')))
print('d.get("phone"):\n{} '.format(d.get('phone')))
print('d.get("phone", "111-222-333-444"):\n{} '.format(d.get('phone', '111-222-333-444')))
print('d content:\n{}'.format(d))
# output:
d.keys:
dict_keys(['first', 'last'])
d.values:
dict_values(['kelly', 'xu'])
d.items:
dict_items([('first', 'kelly'), ('last', 'xu')])
d.get("first"):
kelly
d.get("phone"):
None
d.get("phone", "111-222-333-444"):
111-222-333-444
d content:
{'first': 'kelly', 'last': 'xia'}
setdefault(key, default=None) 如果 key 存在则返回对应的 value,如果 key 不存在,则设置默认None 或 value, 会自动加入到 dict 里
d = {'first': 'kelly', 'last':'xu'}
print('d.setdefault("first", "lydia"):\n{}'.format(d.setdefault('first', 'lydia')))
print('d.setdefault("age", 18):\n{}'.format(d.setdefault('age', 18)))
print('d.setdefault("cellphone"):\n{}'.format(d.setdefault('cellphone')))
print('afer setting:\n{}'.format(d))
d.setdefault("first", "lydia"):
kelly
d.setdefault("age", 18):
18
d.setdefault("cellphone"):
None
afer setting:
{'first': 'kelly', 'last': 'xu', 'age': 18, 'cellphone': None}
作业:

查询
in 操作符:快速查询一个 Key 是否存在于一个 dict 里
d = {'script':'python'}
print('Is the key "script" in d:\n{}'.format('script' in d))
print('Is the key "version" in d:\n{}'.format('version' in d))
print('Is the value "python" in d:\n{}'.format('python' in d))
只应用到 key上,对 value 无效
# output:
Is the key "script" in d:
True
Is the key "version" in d:
False
Is the value "python" in d:
False
dict 遍历
for key, item in d.items()
d = {'first':'kelly', 'last':'xu'}
for key, item in d.items():
print('{}:{}'.format(key, item))
# output:
first:kelly
last:xu
for key in d.keys()
d = {'first':'kelly', 'last':'xu'}
for key in d.keys():
print('{}:{}'.format(key, d[key]))
# output:
first:kelly
last:xu
for key in d
d = {'first':'kelly', 'last':'xia'}
for key in d:
print('{}:{}'.format(key, d[key]))
# output:
first:kelly
last:xia
for value in d.values(), 但是不能访问key
d = {'first':'kelly', 'last':'xia'}
for value in d.values():
print('{}'.format(value))
# output:
kelly
xia
dict 其它方法
d = dict (name='John', age=20)
| Method | Description | Result |
|---|---|---|
| d.copy () | Return copy, without modifying the original dictionary | d.copy (name=‘John’, age=20) |
| d.clear () | Remove all items | {} |
| del d[key] | Remove an items with a given key del | d[name] |
| d.pop (key, [default]) | Remove and return an element from a dictionary | d.pop (‘age’) |
| d.update () | Update the dictionary with elements from dictionary object | d.update (d1) |
| d.fromkeys (sequence, [value]) | Create a dictionary from sequence as keys w/ value provided keys = {‘1’, ‘2’, ‘3’} | d.fromkeys (keys, 0) |
dict.copy(d)
生成一个新的dict
d = dict (name='John', age=20)
print('original dict:\n id:{}\t content:{}'.format(id(d), d))
d_copy = dict.copy(d)
print('copy dict:\n id:{}\t content:{}'.format(id(d_copy), d_copy))
# output:
original dict:
id:2239127189312 content:{'name': 'John', 'age': 20}
copy dict:
id:2239126915072 content:{'name': 'John', 'age': 20}
del d[key]—没有返回值
d = {'first':'kelly', 'last':'xu'}
del d['first']
d
# output:
{'last': 'xu'}
pop(key) - 移除和返回 value
d = {'first':'kelly', 'last':'xu'}
print('return d.pop("first"):{}'.format(d.pop('first')))
print('d content afer pop:{}'.format(d))
# output:
return d.pop("first"):kelly
d content afer pop:{'last': 'xu'}
d1.update(d2): key 相同时会将 d2 的 value替换 d1的 value,key 不同时,会将 d2的key value加入 d1 中
d1 = {'first':'kelly', 'last':'xu'}
d2 = {'first':'kelly', 'last':'wang', 'age':'18'}
d1.update(d2)
d1
# output:
{'first': 'kelly', 'last': 'wang', 'age': '18'}
dic 性能

作业:

dic 应用
计算单词个数:给定一个字符串,计算单词个数
解决方法:
- 应用 .split() 方法将字符串按空格分隔成数组,应用 .replace() 对单词进行处理(可选)
- 两种方式统计单词个数
用 collections.Counter() 方法
用 .setdefault() 方法 - 按单词字符逆序,打印单词及对应的个数
- 打印前 3 使用最频繁的单词
代码:
from collections import Counter as count_words
# import this
paragraph_str = """
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""
word_list = paragraph_str.split()
print ('Number of words: ' + str(len(word_list)))
# apply different pre-processing
word_list = [x.strip().
replace('.','').
replace(',','').
replace('!','').
replace('?','').
replace('*','').
replace('--','').
replace(':','').
lower() for x in word_list]
print ('Number of words after pre-processing: ' + str(len(word_list)))
# Case 1: use collections.Counter to count identical words
word_counts_dict = count_words (word_list)
print ('Number of unique words: ' + str(len(word_counts_dict)))
print ('\nWord \t Count')
for key in sorted (word_counts_dict.keys(), reverse=True):
print (key + '\t : ' + str(word_counts_dict[key]))
# Case 2: use .setdefaults() method to count identical words
word_dict = {}
for word in word_list:
word_dict.setdefault(word, 0)
word_dict[word] += 1
print("word_dict:{}".format(str(len(word_dict))))
print ('\nTop-3 Most Frequent Words in the Zen of Python:')
print ('is: \t{} {}'.format(word_counts_dict['is'], word_dict['is']))
print ('better: {} {}'.format(word_counts_dict['better'], word_dict['better']))
print ('than: \t{} {}'.format(word_counts_dict['than'], word_dict['than']))
输出:
Number of words: 137
Number of words after pre-processing: 137
Number of unique words: 81
Word Count
you're : 1
way : 2
unless : 2
ugly : 1
to : 5
those : 1
there : 1
the : 5
that : 1
than : 8
temptation : 1
special : 2
sparse : 1
simple : 1
silently : 1
silenced : 1
should : 2
rules : 1
right : 1
refuse : 1
readability : 1
purity : 1
preferably : 1
practicality : 1
pass : 1
only : 1
one : 3
often : 1
of : 2
obvious : 2
now : 2
not : 1
never : 3
nested : 1
namespaces : 1
more : 1
may : 2
let's : 1
it's : 1
it : 2
is : 10
in : 1
implicit : 1
implementation : 2
if : 2
idea : 3
honking : 1
hard : 1
guess : 1
great : 1
good : 1
flat : 1
first : 1
face : 1
explicitly : 1
explicit : 1
explain : 2
errors : 1
enough : 1
easy : 1
dutch : 1
do : 2
dense : 1
counts : 1
complicated : 1
complex : 2
cases : 1
break : 1
better : 8
beautiful : 1
beats : 1
be : 3
bad : 1
at : 1
aren't : 1
are : 1
and : 1
ambiguity : 1
although : 3
a : 2
: 1
word_dict:81
Top-3 Most Frequent Words in the Zen of Python:
is: 10 10
better: 8 8
than: 8 8
Google 搜索给页面打分
Google 搜索引擎基于输入的 links 用网页排名 PageRank 算法给每个页面打分。
输入:页面 list, link 到其它页面,links = [(‘a’, ‘b’), (‘a’, ‘c’), (‘b’, ‘c’)]
输出:每个页面的重要性分数
工作原理:
每个页面初始分数设置为 1
多次迭代算法,一般为 10 次,每次迭代:
每页面计算分数:
page_score[to_page] += 0.85*page_score[from_page]/float(outdegree[from_page])
循环累积加分
代码:
links = [('a','b'),('a','c'),('b','c')]
pages = set()
outdegree = {}
for from_page, to_page in links: # list unpacking
pages.add(from_page)
pages.add(to_page)
if from_page in outdegree:
outdegree[from_page] += 1
else:
outdegree[from_page] = 1
print('\n\tPages: ' + str(pages))
print('\tOutdegree: ' + str(outdegree))
page_score = {}
for page in pages:
page_score[page] = 1
for i in range(10):
for from_page,to_page in links:
page_score[to_page] += 0.85*page_score[from_page]/float(outdegree[from_page])
print('\n\tPage Scores: ' + str(page_score))
输出:
Pages: {'a', 'b', 'c'}
Outdegree: {'a': 2, 'b': 1}
Page Scores: {'a': 1, 'b': 5.249999999999999, 'c': 33.61875}

















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









