







通过性能剖析进行性能优化
1. 基于执行时间的分析:
什么任务的执行时间最长
2. 基于等待时间的分析:
任务在什么地方被阻塞的时间最长

性能剖析
随机进行测试

推荐工具
New Relic
针对 PHP :
XHPROF
IFP (instrumentation for php)
慢查询日志
慢查询日志的性能开销非常低,最需要担心的其实是磁盘空间
如果长期开启慢查询 日志, 需要部署日志轮转 log rotation
mysql 支持把日志记录在表中, 但这样没什么必要,
mysql> show variables like 'slow_query%'
-> ;
+---------------------+--------------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/36fb1fbea618-slow.log |
+---------------------+--------------------------------------+
2 rows in set (0.01 sec)
mysql> show variables like 'long_query_ti%'
-> ;
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.01 sec)
配置:
mysql> set global slow_query_log = 'ON';
Query OK, 0 rows affected (0.00 sec)
mysql> set global slow_query_log_file='/var/lib/mysql/instance-1-slow.log';
Query OK, 0 rows affected (0.01 sec)
mysql> set global long_query_time=2;
Query OK, 0 rows affected (0.00 sec)
永久配置:
/etc/mysql/conf.d/mysql.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/instance-1-slow.log
long_query_time = 2
慢查询日志的样子大概就是下面这样

有时慢查询时间设置不了
改了 long_query_time 后,退出docker , 重新登录 mysql 就行了
不要直接读慢查询日志,会死人的,建议使用对应工具:pt-query-digest
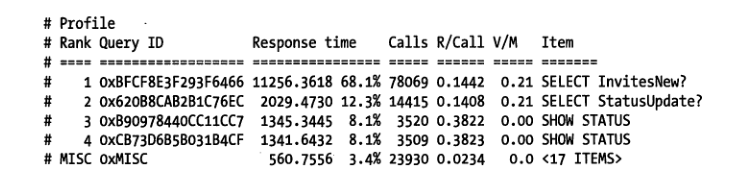
show profile, 默认是关闭的, 可以看更多查询信息,要打开。
运行完查询后 输入 show profiles, 可以看到你使用过的语句查询时间排名
mysql> show profiles;
+----------+------------+----------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------+
| 1 | 0.00096000 | show variables like 'profiling%' |
| 2 | 0.00005900 | select * from user_table |
| 3 | 0.00008125 | show database |
| 4 | 0.00025075 | show databases |
| 5 | 0.00079900 | SELECT DATABASE() |
| 6 | 0.00020850 | show databases |
| 7 | 0.00010500 | show tables |
| 8 | 0.00037750 | show tables |
| 9 | 0.00040675 | select * from tbl_file |
| 10 | 0.00026550 | select * from tbl_file |
| 11 | 0.00027000 | select * from tbl_file |
| 12 | 0.00021125 | select * from tbl_file |
+----------+------------+----------------------------------+
12 rows in set, 1 warning (0.00 sec)
** SHOW PROFILE FOR QUERY 1;**
mysql> SHOW PROFILE FOR QUERY 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000043 |
| checking permissions | 0.000007 |
| Opening tables | 0.000010 |
| init | 0.000037 |
| System lock | 0.000005 |
| optimizing | 0.000002 |
| optimizing | 0.000002 |
| statistics | 0.000007 |
| preparing | 0.000009 |
| statistics | 0.000007 |
| preparing | 0.000003 |
| executing | 0.000005 |
| Sending data | 0.000004 |
| executing | 0.000002 |
| Sending data | 0.000763 |
| end | 0.000005 |
| query end | 0.000004 |
| closing tables | 0.000002 |
| removing tmp table | 0.000003 |
| closing tables | 0.000004 |
| freeing items | 0.000030 |
| cleaning up | 0.000009 |
+----------------------+----------+
22 rows in set, 1 warning (0.00 sec)
SHOW PROFILES 查的其实是INFORMATION_SCHEMA中的数据,所以可以直接查,格式化输入, SHOW PROFILES 本身没有排序功能的

SHOW STATUS
是一种计数器的用法,可以先清空 ,然后再执行语句,再看效果:
mysql> FLUSH STATUS;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM tbl_file ;
...
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%' OR Variable_name LIKE 'create_at';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 1 |
| Handler_read_last | 0 |
| Handler_read_next | 0 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 18 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
18 rows in set (0.00 sec)
比如下面例子:


用explain也可以获取很多信息,但是那是估计的结果,而status是可以获取准确的结果
使用 Performance Schema
间歇性问题: 神龙见首不见尾
一些实际案例:


判断是服务器问题还是单条查询问题
方法一:
手动过一秒执行一次 SHOW GLOBAL STATUS
看看哪些指标变化特别大

方法二 SHOW PROCESSLIST
root@36fb1fbea618:/# mysql -e 'SHOW PROCESSLIST\G' -p |grep State:|sort | uniq -c|sort
-rn
Enter password:
1 State: starting
1 State: Master has sent all binlog to slave; waiting for more updates
1 State:
直接分析日志

总结,
SHOW STATUS, SHOW PROCESSLIST 先做, 没办法了再看日志, 分析日志
捕获诊断数据
1 触发器
2 收集数据的工具
什么是好的 ‘触发器’?
FALSE POSITIVE 误报
FALSE NEGATIVE 漏检
建议指标:
thread runing 的趋势在问题出现时比较明显 ,没有问题时比较平衡
SHOW PROCESSLIST 也比较好用
SHOW INNODB STATUS
下面的代码 查看处于 freeing items 状态的线程数
root >>> mysql -e 'SHOW PROCESSLIST\G' | grep -c "State: freeing items" 20-08-12 8:45
36
要在问题还是苗头的时候捕获,而不要等到木已成舟了才去处理
阈值的设置只要比正常的高一点就行,一般不要设的太高
设置一个时间段,如连续出现5秒钟才报警
需要收集什么样的数据
系统状态
CPU利用率
磁盘使用率
可用空间
ps的输出采样
内存利用率
SHOW STATUS
PROCESSLIST
SHOW INNODB STATUS
等等
小案例
正常情况下 Threads_connected 一般小于15
对于固态硬盘,等待时间不会超过 1/4 秒
show innodb status 已经弃用,改为:
mysql> show engine innodb status \G;


有用的统计表:
information_schema 中有很多有用的表
mysql> show tables like '%STATISTICS';
+--------------------------------------------+
| Tables_in_information_schema (%STATISTICS) |
+--------------------------------------------+
| CLIENT_STATISTICS |
| INDEX_STATISTICS |
| STATISTICS |
| TABLE_STATISTICS |
| THREAD_STATISTICS |
| USER_STATISTICS |
+--------------------------------------------+
6 rows in set (0.00 sec)
可以查找使用的最多和最少的表和索引
可以看看复制用户的CONNECTED_TIME 和 BUSY_TIME
使用 strace
strace 打开后,会监测实际系统调用时间:
他度量的是实际时间,有可以没有占用CPU资源而只是纯粹的等待
但是注意这样会对性能有一定的占用
















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









