







传统的IO编程
传统的IO编程能够实现客户端和服务端的通信,但是确实阻塞IO。
下面我们通过一个简单的例子来看一下:客户端每隔两秒发送一个带有时间戳的"hello world"给服务端,服务端收到之后打印出来。
ServerSocket serverSocket = new ServerSocket(9999);
while(true){
try{
//阻塞方法获取新的连接
Socket socket = serverSocket.accept();
new Thread(()->{
try{
int len;
byte[] data = new byte[1024];
InputStream is = socket.getInputStream();
//按照字节流大方式读取数据
while( (len=is.read(data)) != -1){
System.out.println(new String(data, 0, len));
}
}catch(Exception e){
e.printStackTrace();
}
}).start();
}catch(Exception e){
e.printStackTrace();
}
}server端首先创建一个serverSocket来监听9999端口,每当获取新的连接时,就会给每个连接创建一个新的线程,该线程负责从该连接中读取数据,从而实现多线程服务端和客户端的通信。
try{
Socket socket = new Socket(9999);
while(true){
socket.getOutputStream().write( (new Date() + ": hello world").getBytes());
Thread.sleep(2000);
}
}catch(Exception e){
e.printStackTrace();
}客户端每隔2s向服务端写一个带有时间戳的"hello world"。
IO编程模型在客户端较少的情况下运行良好,但是对于客户端比较多的业务来说,单机服务端可能需要支撑上千万的连接,IO模型就不太合适了,原因如下:
1. 线程资源受限:线程是操作系统中非常宝贵的资源,同一时刻有大量的线程处于阻塞状态时时非常严重的资源浪费,操作系统耗不起;
NIO是对阻塞IO的改进,它是非阻塞的IO。下面来描述一下NIO是如何解决上面三个问题的。
NIO 编程模型中,新来一个连接不再创建一个新的线程,而是可以把这条连接直接绑定到某个固定的线程,然后这条连接所有的读写都由这个线程来负责,那么他是怎么做到的?我们用一幅图来对比一下 IO 与 NIO。

如上图所示,IO 模型中,一个连接来了,会创建一个线程,对应一个 while 死循环,死循环的目的就是不断监测这条连接上是否有数据可以读,大多数情况下,1w 个连接里面同一时刻只有少量的连接有数据可读,因此,很多个 while 死循环都白白浪费掉了,因为读不出啥数据。
而在 NIO 模型中,他把这么多 while 死循环变成一个while死循环,这个死循环由一个线程控制,那么他又是如何做到一个线程,一个 while 死循环就能监测1w个连接是否有数据可读的呢? 这就是 NIO 模型中 selector 的作用,一条连接来了之后,现在不创建一个 while 死循环去监听是否有数据可读了,而是直接把这条连接注册到 selector 上,然后,通过检查这个 selector,就可以批量监测出有数据可读的连接,进而读取数据。



由于 NIO 模型中线程数量大大降低,线程切换效率因此也大幅度提高。
IO读写是面向流的,一次性只能从流中读取一个或者多个字节,并且在读完之后,流无法再读取,需要自己缓存数据,而NIO的读写是面向Buffer的,可以随意的读取任何一个字节数据,不需要自己混缓存数据,这一切只需要移动读写指针即可。

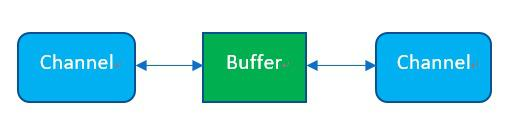
Buffer 作为 IO 流中数据的缓冲区,而 Channel 则作为 socket 的 IO 流与 Buffer 的传输通道。客户端 socket 与服务端 socket 之间的 IO 传输不直接把数据交给 CPU 使用,而是先经过 Channel 通道把数据保存到 Buffer,然后 CPU 直接从 Buffer 区读写数据,一次可以读写更多的内容。
使用 Buffer 提高 IO 效率的原因(这里与IO流里面的 BufferedXXStream、BufferedReader、BufferedWriter 提高性能的原理一样):IO 的耗时主要花在数据传输的路上,普通的 IO 是一个字节一个字节地传输,而采用了 Buffer 的话,通过 Buffer 封装的方法(比如一次读一行,则以行为单位传输而不是一个字节一次进行传输)就可以实现“一大块字节”的传输。
选择器,实现一个单独的线程来监控多个注册在她上面的信道Channel,通过一定的选择机制,实现多路复用的效果。
多路复用是指使用单线程也可以通过轮询监控的方式实现多线程类似的效果。简单的说就是,通过选择机制,使用一个单独的线程很容易来管理多个通道。
简单讲完了NIO相对于IO的优点之后,我们接下来系统的学习一下NIO中Buffer、Selector、Channel的使用方法,最后根据掌握知识使用NIO的方案替换掉IO的方案。
缓冲区是一个用于特定基本数据类型的容器。由 java.nio 包定义的,所有缓冲区都是 Buffer 抽象类的子类。 Java NIO 中的 Buffer 主要用于与 NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的。
1. 容量capacity: 表示Buffer的最大数据容量,缓冲区容量不能为负,并且创建之后不能更改。如果写入的数据超出了capacity,就会触发异常。
2. 限制limit: 第一个不应该读取或写入的数据的索引,即位于 limit 后的数据 不可读写。缓冲区的限制不能为负,并且不能大于其容量。
3. 位置position: 下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制。
4. 标记 (mark)与重置 (reset): 标记是一个索引,通过 Buffer 中的 mark() 方法指定Buffer 中一个特定的position,之后可以通过调用 reset() 方法恢复到这个position。
mark、position、limit、capacity遵守以下不变式: 0 <= mark <= position <= limit <= capacity
接下来我们以ByteBuffer为例,来详细的了解一下Buffer的用法。
ByteBuffer同样是一个抽象类,我们通过allocate方法,最终创建的是HeapByteBuffer对象。
static ByteBuffer allocate(int capacity) 分配一个新的byte型缓冲区static ByteBuffer allocateDirect(int capacity)
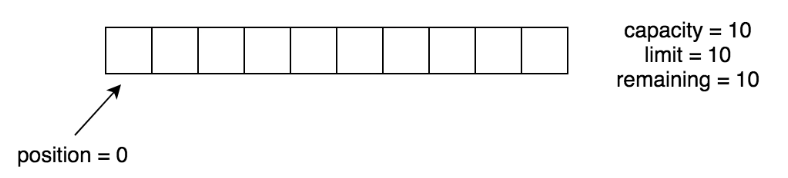
分配一个新的字节缓冲区,同allocate不同的是,缓冲区每一个字节都被初始化为0ByteBuffer buffer = ByteBuffer.allocate(10);此时我们关注一下capacity、position、limit、remaining值得变化。
positon:0 remaining:10 limit:10 capacity:10
//remainning = limit - positioncapacity表示容量的大小,为初始化是传入的值的大小,之后便不会变化。positon指向即将要操作的位置。在写状态下limit表示可写的空间的大小。remaining表示剩余可写空间的大小。
1. abstract ByteBuffer put(byte b):将字节b写入缓冲区当前的位置position,然后position+1
2. abstract ByteBuffer put(ByteBuffer src),将src中可读的部分(也就是position到limit)写入当前的缓冲区
3. ByteBuffer put(byte[] src, int offset, int length),把字节数组src从offset开始的length字节写入缓冲区当前的位置position,然后position位置后移length个位置。
4. final ByteBuffer put(byte[] src):把字节数组src写入缓冲区当前的位置position。
String str = "ABC";
byte[] bytes = str.getBytes();
buffer.put(bytes);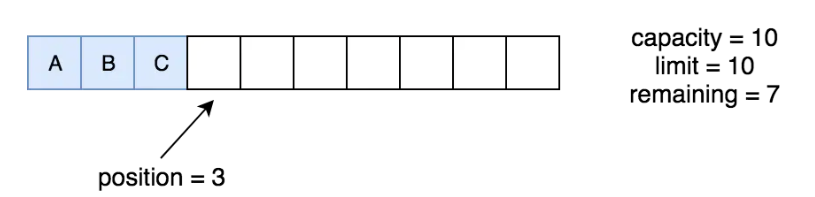
put完之后,我们尝试从buffer中读一些数据,flip方法是将写模式变成读模式,它的实现如下。(将刚刚写入的数据读出)
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;//清除mark
return this;
}可以看到它把position的值变成了0,把position的值赋给了limit,表示从起始位置开始读,来看一下调用之后值的变化。
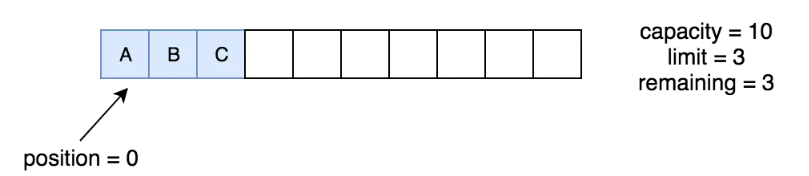
position变成了0,limit变成了原来position的值,也就是3。remaining也为3,capacity不变。
1. abstract byte get():从缓冲区中读取当前位置position的字节,然后position后移一个位置
2. ByteBuffer get(byte[] dst):将字节缓冲区中的内容读出,存入字节数组dst中
3. ByteBuffer get(byte[] dst, int offset, int length):把字节缓冲区中内容读出,存入字节数组dst中。
Byte byte1 = buffer.get();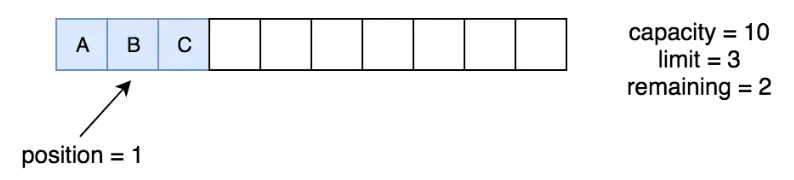
这里调用一下mark,mark之后不会有变化,只是会把position的值赋值给mark,我们看下它的实现代码。注意。此时mark的值变成了1,后边会用到这个值。
public final Buffer mark() {
mark = position;
return this;
}buffer.mark();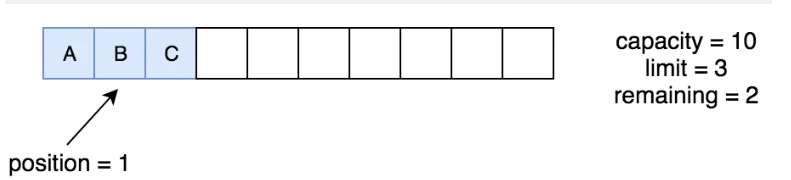
还记得前面,我们调用mark,把position的值赋值给mark。这次我们来调用reset,它的作用是把之前mark的值重新赋值给position。它的实现如下:
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}Byte byte2 = buffer.get();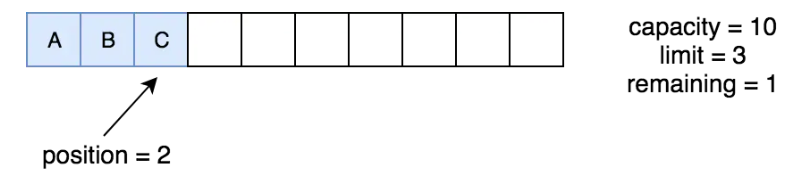
buffer.reset()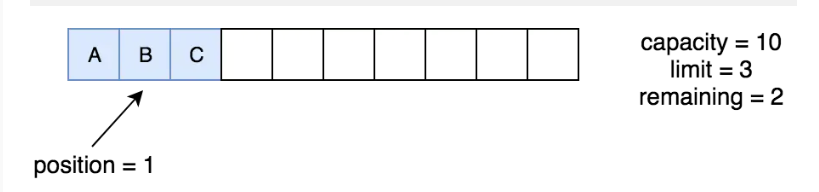
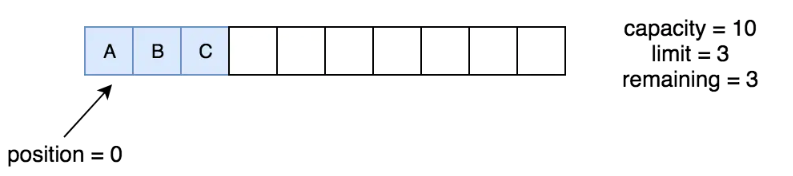
在读了一些数据之后,如果我们想重新读怎么办?可以用rewind,它会把position的值置为0,同时mark值恢复为-1。
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
最后我们来看一下clear的用法,clear会把position、limit、capacity恢复到初始状态,它的实现如下:
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
} 
------------------------------------------------------------------
Selector、Channel的介绍见IO到NIO的前因后果,以及NIO的用法(2)——Selector、Channel















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









