







倒排索引是全文检索的主要方式
通过分词将 内容分成一个个的单词,将每个单词拿出来做key,value则是这个单词所在的文章ID
比如我们有如下MySQL数据库:
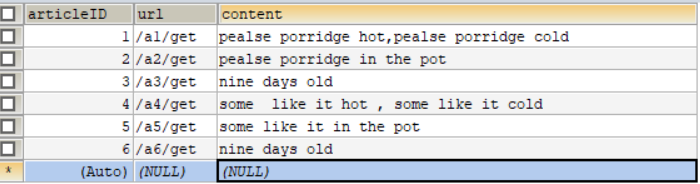
我们如果要进行搜索, 一般都是用 关键词来搜索content的,比如我们要搜索文章内有hot这个单词的文章URL,那么就需要 使用 select url from article where content like '%hot%'这样的语句来搜索。
但是由于B+树索引只能支持前缀进行查找,如 hot%,前缀搜索才能使用索引来进行快速查找。由于一般情况下都不是前缀查找,所以无法使用索引,那么就变成了全表查找,这样效率是很慢的。
全文检索(Full-Text Search)
由于B+树不能很好的完成搜索的操作,那么就出现了全文检索。全文检索是将存储于数据库中的整本书或整篇文章中的任何内容信息查找出来的技术。
倒排索引(inverted index)
全文检索使用倒排索引进行实现。倒排索引和B+树索引一样,也是一种索引结构。它在辅助表(倒排表)中存储了单词与单词自身在一个或多个文档中所在位置之间的映射: {单词,单词所在文档的ID}
对于上面的article数据表,那么它的辅助表(倒排表)就是:
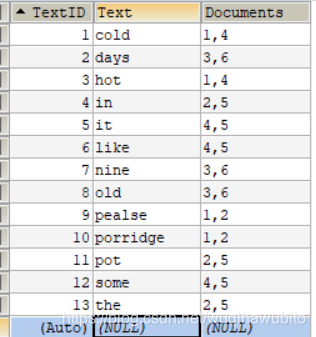
如图,content字段里的所有词都取出来作为Text字段的值,然后 documents存放的是文档ID,如上面的cold就出现在 1和4这两个文章中。
分词器
对content字段里的一段话进行取词需要用到分词器,它可以将将一段话分成一个个的单词
分析器:
作用:
- 将一块文本分成适合于倒排索引的独立的词条
- 将这些词条统一化为标准格式以提高他们的
可搜索性
分析器实际上是将三个功能封装到了一个包里:
- 字符过滤器:
首先,字符串按顺序通过每个字符过滤器,用处是在分词前整理字符串,一个字符过滤器可以用来去掉HTML,或者将 & 转换成 and - 分词器:
字符串被 分词器分为 单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条 - Token 过滤器:
词条按顺序通过每个 token过滤器。这个过程可能会改变词条(例如,小写化单词),删除词条(如 a ,and ,the 这种无用词),或者增加 词条
上面的倒排表是我们自己完全根据内容分出的,如果用分析器进行分词,那么可能会不一致
总结
有了倒排表之后,我们可以对倒排表添加B+树索引,在搜索时对关键词使用索引快速查找,然后得到 articleID之后也能更快的查找到 文章URL,这比直接使用全表查找要快得多。所以搜索引擎都用倒排索引进行全文检索















 4854
4854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









