







4.1 为什么慢
了解查询的生命周期,清楚查询的时间消耗情况对于优化查询有很大意义。
4.2 慢查询基础:优化数据访问
查询性能低下最基本的原因是访问数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不常见。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,可以用下面的两个步骤来分析:
1.确认应用程序是否检索大量超过需要的数据。
2.确认MySQL服务器层是否在分析大量超过需要的数据行。
4.2.1 请求了不必要的数据
有些查询会请求超过实际需要的数据,然后这些多余的数据会被应用程序丢弃。这会给MySQL服务器带来额外的负担,并增加网络开销;另外也会消耗应用服务器的CPU和内存资源。如:
查询不需要的记录。
多表关联时返回全部列。
总是取出全部列。
重复查询相同数据。
4.2.2 扫描额外记录
在确定只返回需要的数据以后,接下来应该看看查询的为了返回结果是否扫描了过多的数据。对于MySQL,最简单地衡量查询开销的三个指标如下:响应时间;返回行数;扫描行数。
4.3 重构查询方式
在优化有问题的查询时,目标应该是找到一个更优的方法获得实际需要的结果,而不一定总是需要MySQL获取一模一样的结果集。有时候,可以将查询转换一种写法让其返回一样的结果,但是性能更好。但也可以通过修改应用代码,用另一种方式完成查询。
4.3.1 一个复杂查询还是多个简单查询
在其他条件都相同的时候,使用尽可能少的查询,但是有时候分解是很有必要。
4.3.2 切分查询
有时候对于一个大查询需要分治,将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
4.3.3 分解关联查询
很多高性能的应用都会对关联查询进行分解。简单地,可以对每一个表进行一次单表查询,然后将结果在应用程序中进行关联。
4.4 查询执行的基础
查询执行的路径:
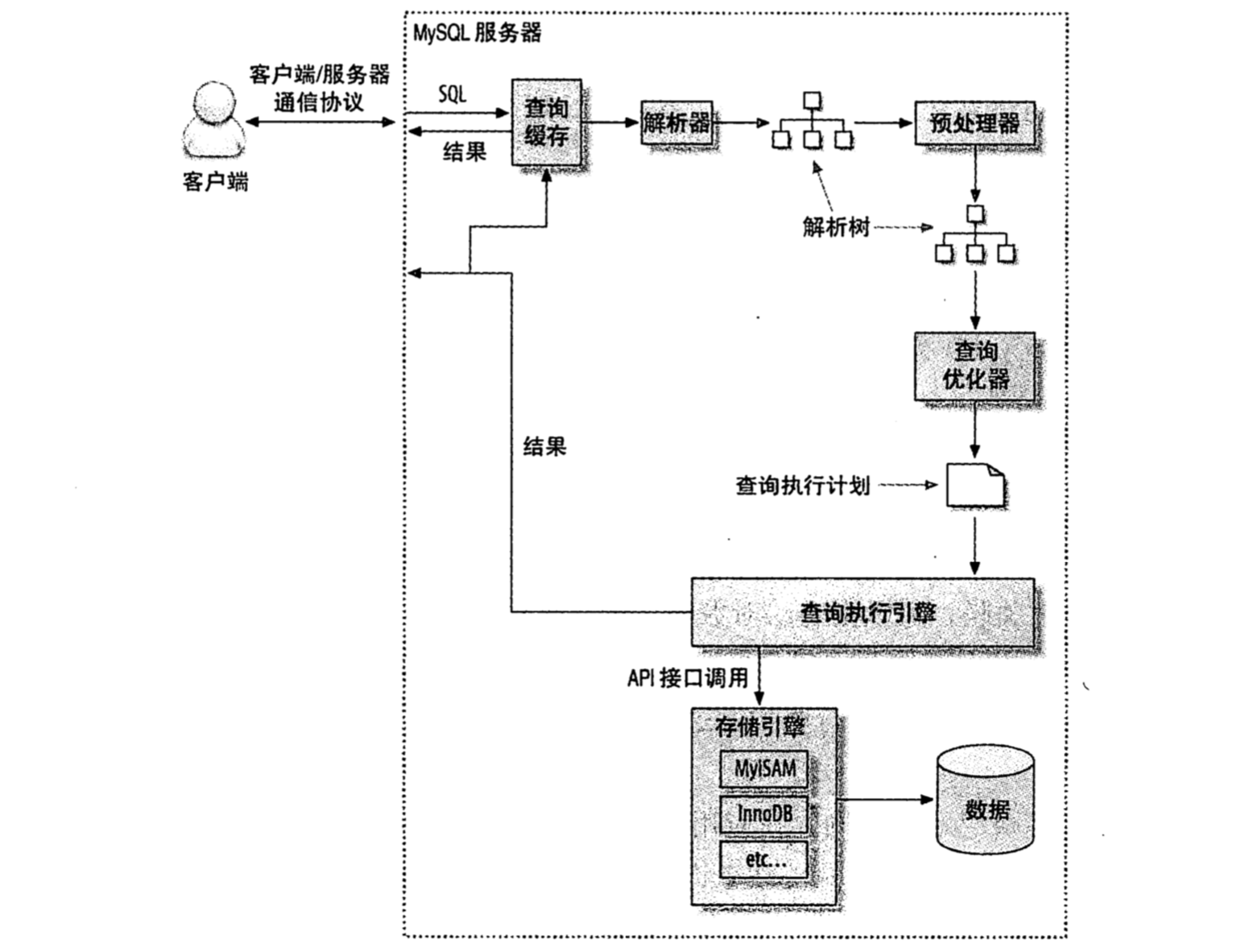
4.4.1 MySQL客户端/服务器通信协议
半双工,在任意一个时刻,要么是由服务器向客户端发送数据,要么是由客户端像服务器发送数据,这两个动作不能同时发生。所以,我们也不能将一个消息切成小块独立发送。
4.4.2 查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,MySQL会优先检查是否命中缓存中的数据。检查是通过一个对大小写敏感的哈希查找实现的。查找与缓存中即使有一个字节不同,也不能匹配。
4.4.3 查询优化
MySQL优化查询器是一个非常复杂的部件,他使用了很多优化策略来生成一个最优的执行计划。可分为两种,一种是静态优化,一种是动态优化。静态优化可以直接对解析树进行分析,并完成优化。静态优化不依赖于特别的数值。静态优化在第一次完成后就一直有效,即使使用不同的参数重新进行查询也不会发生变化。可以认为是一种“编译时优化”。相反,,动态优化则与查询的上下文有关,也可能和其他很多因素有关。这需要在每次查询的时候都进行评估,可以认为这是“运行时优化”。
4.4.4 查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎将根据这个计划来完成整个查询。这里的执行计划是一个数据结构,而不是和很多其他的关系型数据库那样会生成对应的字节码。
4.4.5 返回结果给客户端
查询执行的最后一个阶段是将查询结果返回给客户端。 即使查询不需要返回结果集给客户端,MySQL仍会返回这个查询的一些信息。
4.5 查询优化器的局限性
MySQL的万能“嵌套循环”并不是对每种查询都是最优的。不过MySQL的查询优化器只对少部分查询不适用,而往往可以通过改写查询让MySQL高效地完成工作。
4.5.1 关联子查询
两点:一是不需要听取那些关于子查询的“绝对真理”,二是应该用测试来验证对子查询的执行计划和响应时间的假设。
4.5.2 UNION的限制
如果希望UNION的各个子句能够根据limit只取部分结果集,或者希望能够先排好序再合并结果集的话,就需要在UNION的各个子句中分别使用这些子句。
4.5.3 索引合并优化
当where子句中包含多个复杂条件的时候,MySQL能够访问单个表的多个索引以合并交叉过滤的方式来定位需要查找的行。
4.5.4 等值传递
某些时候,等值传递会带来意想不到的额外消耗。
4.5.5 并行执行
MySQL无法利用多核特性执行并行查询。
4.5.6 哈希关联
MySQL并不支持哈希关系,所有关联都是嵌套循环关联。不过,可以通过建立一个哈希索引来间接实现哈希关联。如果使用的是Memory引擎,索引都是哈希索引,关联也类似哈希关联。另外,MariaDB已经实现了真正的哈希关联。
4.5.7 松散索引扫描
MySQL并不支持,也就无法按照不连续的方式扫描一个索引。通常,MySQL索引扫描需要先定义一个起点和终点,即使需要的数据只是这段索引中很少的几个,MySQL仍需扫描这段索引中的每一个条目。
4.6 查询优化器的提示(hint)
如果对优化器的执行计划不满意,可以用优化器提供的几个提示来控制最终的执行计划。
4.7 优化特定类型的查询
4.7.1 优化count
使用count(*),使用近似值。
4.7.2 优化关联查询
确保on和using子句的列上有索引。
确保任何group by和order by的表达式只涉及到表中的一个列。
当升级MySQL时要注意,关联语法、运算符优先级等其他可能发生变化的地方。
4.7.3 优化子查询
尽可能使用关联查询代替。
4.7.4 优化group by和distinct
使用索引。
4.7.5 优化limit分页
尽可能使用索引覆盖扫描,而不是查询所有的列。
4.7.6 优化SQL_CALC_FOUND_ROWS
将具体的页数换成下一页按钮;先获取并缓存较多的数据。
4.7.7 优化UNION
经常需要手工地将where,limit,order by等子句下推到UNION的各个子查询中,以便优化器可以利用这些条件进行优化。














 5613
5613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









