







关于HashMap的工作原理与实现的好文章不少,推荐几个:
http://blog.csdn.net/u010887744/article/details/50346257
http://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/
http://blog.csdn.net/vking_wang/article/details/14166593
对着HashMap的源码来看理解的会更好,JDK的版本不同具体的实现原理也有所不同,新版本都是在有所改进,减少碰撞,同时更少的rehash,这么做都是为了更高的效率和更少的bug。我是用jdk1.7学习的,jdk版本不是重点,重点对其中的原理理解即可。
1.实现
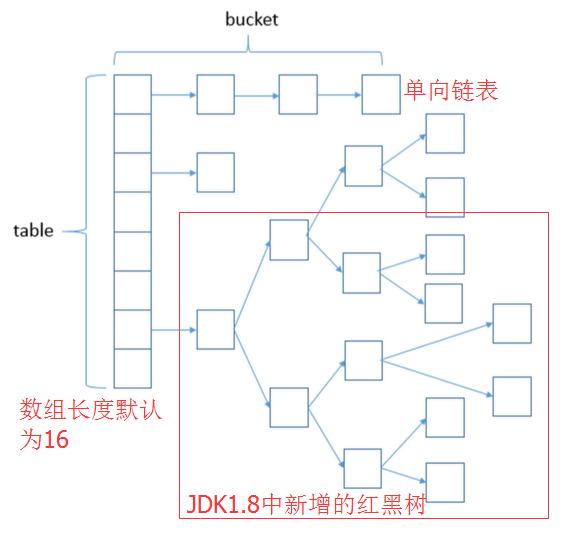
HashMap是采用数组+单向链表的方式实现的。这样做结合了数组寻址容易和链表插入删除快的有点。HashMap也可以理解为链表的数组,也是哈希表的一种实现方法-拉链法。在JDK8里,新增默认为8的閥值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
2.原理
2.1 put,即HashMap.put(K,V)方法。
首先需要确认该数据元素在数组中位置。数组的默认长度是16(assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";).
先用key计算h,然后用h和length-1按位与所得的值即为该数据数组在数组中的index(位置)。
k即为key
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);return h & (length-1);//index,在数组中的位置然后将该数据放在单向链表中。
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);//此e为上一个单向链表的第一个元素这句可以看出新元素是单向链表的第一个元素,并且指向上一个保存在该单向链表的第一个元素,这一过程称为碰撞(我的理解)。
resize
当多个key向HashMap中put的时候,碰撞就可能会变得频繁,可能某个单向链表会变得很长,get元素的时候查找效率就会降低。JDK中是这样解决的:
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);loadFactor初始值是0.75
threshold是阈值。初始值16*0.75=8.
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









