







 本文介绍了使用Python实现强化学习中贝尔曼最优公式的方法,通过网格世界案例详细展示了如何求解状态值和行动值,以及利用Contractionmappingtheorem进行迭代优化策略的过程。最终通过迭代100次得到最优策略和状态值。
本文介绍了使用Python实现强化学习中贝尔曼最优公式的方法,通过网格世界案例详细展示了如何求解状态值和行动值,以及利用Contractionmappingtheorem进行迭代优化策略的过程。最终通过迭代100次得到最优策略和状态值。
强化学习原理python篇03——贝尔曼最优公式)
本章全篇参考赵世钰老师的教材 Mathmatical-Foundation-of-Reinforcement-Learning Optimal State Values and Bellman Optimality Equation章节,请各位结合阅读,本合集只专注于数学概念的代码实现。
例子
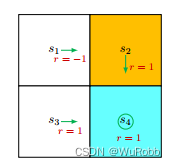
对于网格世界这样一个例子,其贝尔曼公式中的R和P为
R = np.array([-1, 1, 1, 1]).reshape(-1, 1)
P = np.array(
[
[0, 1, 0, 0],
[0, 0, 0, 1],
[0, 0, 0, 1],
[0, 0, 0, 1],
])
求解状态值
给定 γ = 0.9 \gamma=0.9 γ=0.9,利用上一节的解析解求解公式得到状态值
closed_form_solution(R, P, 0.9)
array([[ 8.],
[10.],
[10.],
[10.]])
求解行动值
q π ( s 1 ; a 1 ) = − 1 + γ v π ( s 1 ) = 6.2 q π ( s 1 ; a 2 ) = − 1 + γ v π ( s 2 ) = 8 q π ( s 1 ; a 3 ) = 0 + γ v π ( s 3 ) = 9 q π ( s 1 ; a 4 ) = − 1 + γ v π ( s 1 ) = 6.2 q π ( s 1 ; a 5 ) = 0 + γ v π ( s 1 ) = 7.2 \begin{align*} q_π(s_1; a_1) =& −1 + γv_π(s_1) = 6.2\\ q_π(s_1; a_2) =& −1 + γv_π(s_2) = 8\\ q_π(s_1; a_3) =& 0 + γv_π(s_3) = 9\\ q_π(s_1; a_4) =& −1 + γv_π(s_1) = 6.2\\ q_π(s_1; a_5) =& 0 + γv_π(s_1) = 7.2 \end{align*} qπ(s1;a1)=qπ(s1;a2)=qπ(s1;a3)=qπ(s1;a4)=qπ(s1;a5)=−1+γvπ(s1)=6.2−1+γvπ(s2)=80+γvπ(s3)=9−1+γvπ(s1)=6.20+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









