






6.6预期的Sarsa
考虑与Q学习一样的学习算法,除了考虑到当前策略下每个动作的可能性,它使用预期值而不是最大化下一个状态 - 动作对。 也就是说,考虑具有更新规则的算法
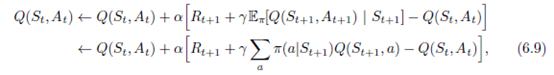
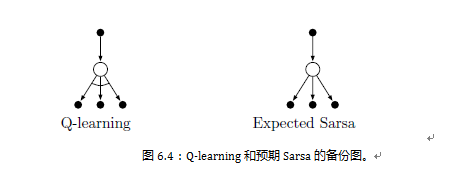
但这遵循Q学习的模式。 给定下一个状态St + 1,该算法在确定性方向上与Sarsa在移位中移动的方向相同,因此称为Erpected Sarsa。 其备份图如图6.4右侧所示。

图6.3:作为α的函数的TD控制方法对于cliff行走任务的临时和渐近性能。 所有算法都使用ε-greedy policy 且ε= 0.1。 渐近性能是平均超过100,000集,而临时性能是前100集的平均值。 这些数据分别是临时和渐近情况的平均超过50,000和10次运行。 实心圆圈标志着每种方法的最佳临时性能。 改编自van Seijen等人。(2009年)。
预期的Sarsa在计算上比Sarsa更复杂,但作为回报,它消除了由于随机选择At + 1而导致的方差。 考虑到相同的经验,我们可能期望它的表现略好于Sarsa,事实上它通常确实如此。图6.3显示了与Sarsa和Q-learning相比,预期Sarsa的悬崖行走任务的总结果。 预期的Sarsa保留了Sarsa比 Q-learning在这个问题上的显着优势。 此外,预期的Sarsa在步长大小参数a的广泛值范围内显示出比Sarsa显着的改善。 在cliff行走中,状态转换都是确定性的,并且所有随机性都来自策略。 在这种情况下,预期的Sarsa可以安全地设置α= 1而不会导致渐近性能的任何退化,而Sarsa只能在长期运行时以小的α值表现良好,短期表现较差。 在这个和其他例子中,预期的Sarsa相对于Sarsa具有一致的经验优势。
在这些cliff行走结果中,预期的Sarsa被用于on-policy,但一般来说,它可能使用与目标政策不同的政策来产生行为,在这种情况下,它成为一种off-policy算法。 例如,假设π是贪婪的政策,而行为更具探索性; 然后预期Sarsa正是Q-学习。 在这个意义上,预期的Sarsa包含并概括了Q学习,同时可靠地改善了Sarsa。 除了额外的计算成本之外,预期的Sarsa可能完全支配其他更着名的TD控制算法。
6.7最大化偏差和双重学习
到目前为止,我们讨论的所有控制算法都涉及最大化其目标策略的构建。例如,在Q-learning中,目标策略是给定当前操作值的贪婪策略,其中使用max定义,而在Sarsa中,策略通常是ε-greedy,这也涉及最大化操作。在这些算法中,最大估计值被隐含地用作最大值的估计值,这可能导致明显的正偏差。要了解原因,请考虑单个状态s,其中有许多动作a的真值q(s,a),都是零,但其估计值Q(s,a)是不确定的,因此分布在一些零以上,一些在零以下。真值的最大值为零,但估计的最大值为正,一个正偏差。我们称这种最大化偏差。
例6.7:最大化偏差示例 图6.5中显示的小型MDP提供了一个简单示例,说明最大化偏差如何损害TD控制算法的性能。 MDP有两个非终端状态A和B.剧集总是从A开始,可以选择左右两个动作。动作右立即转换到终端状态,奖励和返回零。左侧动作转换为B,也有零奖励,从中有许多可能的动作,所有这些动作都会导致立即终止,并从正态分布中获得奖励,平均值为-0.1,方差为1.0。因此,从左边开始的任何轨迹的预期回报是-0.1,因此在状态A中向左移动总是错误的。然而,我们的控制方法可能有利于左,因为最大化偏差使B看起来具有正值。图6.5显示,带有ε-greedy动作选择的Q-学习最初学会强烈支持左边动作。即使在渐近线上,Q-学习也比我们的参数设置中的最佳动作大约多5%(ε = 0.1,α= 0.1,γ= 1)。

是否存在避免最大化偏差的算法?首先,考虑一个强盗案例,其中我们对许多行为中的每一个的价值进行嘈杂估计,获得作为每个行动的所有游戏所获得的奖励的样本平均值。如上所述,如果我们使用估计的最大值作为真值的最大值的估计,那么将存在正的最大化偏差。查看问题的一种方法是,由于使用相同的样本(游戏)来确定最大化动作并估计其值。假设我们将戏剧划分为两组,并用它们来学习两个独立的估计,称之为Q1(a)和Q2(a),对于所有的aϵ A,每个估计都是真值q(a).我们可以使用一个估计值,比如Q1,确定最大化动作A*= argmaxa Q1(a),另一个,Q2,以提供其值的估计值Q2(A*)= Q2(argmaxa Q1(a))。在E [Q2(A*)] = q(A*)的意义上,该估计将是无偏的。我们也可以重复这个过程,两个估计的作用相反,产生第二个无偏估计Q1(argmaxa Q2(a))。这是双重学习的想法。请注意,虽然我们学习了两个估计值,但每次估计只会更新一个估算值;双重学习使内存要求加倍,但不会增加每步的计算量。
双重学习的想法自然地延伸到完整MDPs的算法。例如,类似于Q-学习的双学习算法,称为双Q-学习,将时间步长分为两步,可能通过在每一步上翻转硬币。如果硬币出现,那么更新就是
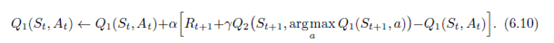
如果硬币出现尾部,则在Q1和Q2切换时进行相同的更新,以便更新Q2。 两个近似值函数完全对称地处理。 行为策略可以使用行为值估计。 例如,“双Q学习的政策可以基于两个动作 - 值估计的平均值(或总和)。双Q学习的完整算法在下面的框中给出。这是用于产生图6.5中的结果的算法。在这个例子中,双重学习似乎消除了最大化偏差造成的伤害。当然还有Sarsa和Expected Sarsa的双重版本。

练习6.13具有ε-greedy目标策略的双预期Sarsa的更新方程是什么?
6.8游戏,afterstates和其他特殊情况
在本书中,我们尝试对一系列任务提出统一的方法,但当然总是有一些特殊的任务可以通过专门的方式得到更好的处理。例如,我们的一般方法涉及学习一个动作-值函数,但是在第一章中我们提出了一种学习玩tic-tac-toe的TD方法,它学到的东西更像是一个状态值函数。如果我们仔细观察那个例子,很明显,在那里学到的函数既没有动作值函数也没有通常意义上的状态值函数。传统的状态值函数评估代理可以选择操作的状态,但是在代理移动之后,井字游戏中使用的状态值函数评估板位置。让我们称这些为afterstates,并把它们的价值函数称为afterstates价值函数。当我们了解环境动态的初始部分但不一定了解完整的动态时,afterstates是有用的。例如,在游戏中,我们通常知道动作的直接效果。我们知道每次可能的象棋移动会产生什么样的位置,但不知道我们的对手将如何回复。 Afterstate值函数是利用这种知识的自然方式,从而产生更有效的学习方法。
从tic-tac-toe示例中可以明显看出,根据afterstates设计算法的效率更高。传统的动作值函数将从位置映射并移动到值的估计值。但是许多位置-移动对产生相同的结果位置,如下例所示:

在这种情况下,位置-移动对是不同的,但产生相同的“afterposition”,因此必须具有相同的值。传统的行动-价值函数必须分别评估两个对,而后验值函数将立即同等地评估两个对。任何关于左侧位置移动对的学习都会立即转移到右侧的位置。
afterstates出现在许多任务中,而不仅仅是游戏。例如,在排队任务中,有一些操作,例如将客户分配给服务器,拒绝客户或丢弃信息。在这种情况下,行动实际上是根据其直接影响来定义的,这些影响是完全已知的。
不可能描述所有可能的专业问题和相应的专业学习算法。但是,本书中提出的原则应该广泛应用。例如,仍然可以根据广义策略迭代恰当地描述afterstate方法,其中策略和(afterstate)值函数以基本相同的方式交互。在许多情况下,人们仍将面临政策和政策方法之间的选择,以管理持续探索的需要。
练习6.14描述杰克汽车租赁(例4.2)的任务如何在余震方面重新制定。就这一具体任务而言,为什么这样的重新制定可能会加速融合?
6.9总结
在本章中,我们介绍了一种新的学习方法,即时间差异(TD)学习,并展示了如何将其应用于强化学习问题。像往常一样,我们将整体问题分为预测问题和控制问题。TD方法是用于解决预测问题的蒙特卡罗方法的替代方法。在这两种情况下,控制问题的扩展都是通过我们从动态编程中抽象出来的通用策略迭代(GPI)的概念。这就是近似策略和价值函数应该以这样一种方式相互作用的想法,即它们都朝着最佳值移动。
构成GPI的两个过程之一是驱动值函数以准确地预测当前策略的回报;这是预测问题。另一个过程驱动策略在本地改进(例如,相对于当前值函数是ε-greedy)。当第一个过程基于经验时,出现了关于保持充分探索的复杂性。我们可以根据TD控制方法进行分类。他们是否通过使用on-policy或off-policy方法处理这种并发症。Sarsa是一种on-policy上的方法,Q-learning是一种off-policy方法。我们在此提出的预期Sarsa也是一种政策方法。还有第三种方法可以扩展TD方法来控制我们在本章中没有包含的方法,称为actor–critic方法。这些方法在第13章中有详细介绍。
本章介绍的方法是目前使用最广泛的强化学习方法。这可能是由于它们非常简单:它们可以在线应用,只需极少的计算量,就可以通过与环境的交互来体验;它们可以通过可以用小型计算机程序实现的单个方程几乎完全表达。在接下来的几章中,我们扩展了这些算法,使它们更复杂,功能更强大。
所有新算法将保留这里介绍的算法的本质:它们将能够在线处理经验,计算相对较少,并且它们将由TD错误驱动。本章介绍的TD方法的特殊情况应正确地称为one-step, tabular, model-free TD方法。在接下来的两章中,我们将它们扩展为n步形式(蒙特卡罗方法的链接)和包含环境模型的形式(计划和动态编程的链接)。然后,在本书的第二部分,我们将它们扩展到各种形式的函数逼近而不是表格(深度学习和人工神经网络的链接)。
最后,在本章中,我们完全在强化学习问题的背景下讨论了TD方法,但TD方法实际上比这更普遍。它们是学习对动力系统进行长期预测的一般方法。例如,TD方法可能与预测财务数据,寿命,选举结果,天气模式,动物行为,发电站需求或客户购买有关。只有当TD方法被分析为纯粹的预测方法时,不管它们在强化学习中的用途如何,它们的理论性质才能得到很好的理解。即便如此,TD学习方法的这些其他潜在应用尚未得到广泛探索。
书目和历史评论















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









