







 固定长度的数据包。为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。以指定字符串为包的结束标志。当字节流中遇到特殊的符号值时就认为到一个包的结尾。header + body格式。这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中含有一个字段来表明包体有多大。
固定长度的数据包。为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。以指定字符串为包的结束标志。当字节流中遇到特殊的符号值时就认为到一个包的结尾。header + body格式。这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中含有一个字段来表明包体有多大。
目录
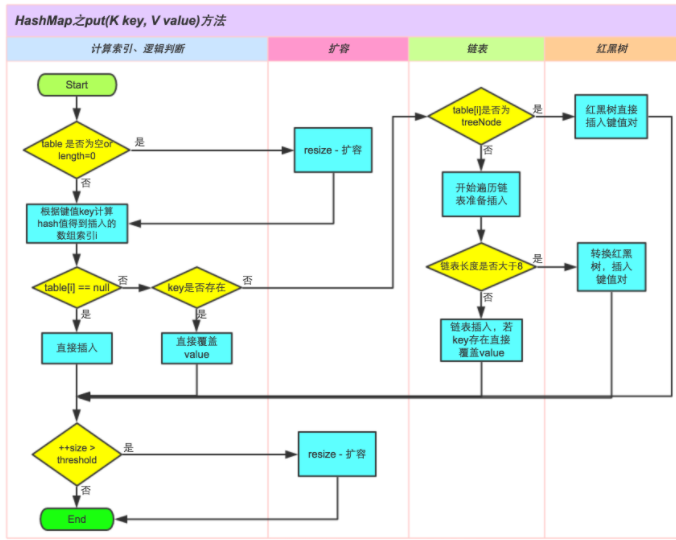
HashMap的put方法
put方法过程:
- 如果table没有初始化就先进行初始化过程
- 使用hash算法计算key的索引
- 判断索引处有没有存在元素,没有就直接插入
- 如果索引处存在元素,则遍历插入,有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入
- 链表的数量大于阈值8,就要转换成红黑树的结构
- 添加成功后会检查是否需要扩容
HashMap的扩容过程
1.8扩容机制:当元素个数大于threshold时,会进行扩容,使用2倍容量的数组代替原有数组。采用尾插入的方式将原数组元素拷贝到新数组。1.8扩容之后链表元素相对位置没有变化,而1.7扩容之后链表元素会倒置。
由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因是数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标计算。也就是说,在元素拷贝过程不需要重新计算元素在数组中的位置,只需要看看原来的hash值新增的那个bit是1还是0,是0的话索引没变,是1的话索引变成“原索引+oldCap”(根据e.hash & (oldCap - 1) == 0判断) 。
这样可以省去重新计算hash值的时间,而且由于新增的1bit是0还是1可以认为是随机的,因此resize的过程会均匀的把之前的冲突的节点分散到新的bucket。
自定义协议怎么解决粘包问题
- 固定长度的数据包。为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。
- 以指定字符串为包的结束标志。当字节流中遇到特殊的符号值时就认为到一个包的结尾。
- header + body格式。这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中含有一个字段来表明包体有多大。
LeetCode129题(求根节点到叶节点数字之和)
深度优先搜索。从根节点开始,遍历每个节点,如果遇到叶子节点,则将叶子节点对应的数字加到数字之和。如果当前节点不是叶子节点,则计算其子节点对应的数字,然后对子节点递归遍历。
没有困难的题目,只有勇敢的刷题人!
// 输入: [1,2,3]
// 1
// / \
// 2 3
// 输出: 25
class Solution {
public int sumNumbers(TreeNode root) {
if (root == null) {
return 0;
}
return sumNumbersHelper(root, 0);
}
private int sumNumbersHelper(TreeNode node, int sum) {
if (node == null) {
return 0;
}
if (sum > Integer.MAX_VALUE / 10 || (sum == Integer.MAX_VALUE / 10 && node.val > Integer.MAX_VALUE % 10)) {
throw new IllegalArgumentException("exceed max int value");
}
sum = sum * 10 + node.val;
if (node.left == null && node.right == null) {
return sum;
}
return sumNumbersHelper(node.right, sum) + sumNumbersHelper(node.left, sum);
}
}
MySQL的索引结构
MySQL 数据库使用最多的索引类型是BTREE索引,底层基于B+树数据结构来实现。
B+ 树是基于B 树和叶子节点顺序访问指针进行实现,它具有B树的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ 树中,节点中的 key 从左到右递增排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。

进行查找操作时,首先在根节点进行二分查找,找到key所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的数据项。
为什么用B+树
B+树的特点就是够矮够胖,能有效地减少访问节点次数从而提高性能。
二叉树:二分查找树,虽然也有很好的查找性能log2N,但是当N比较大的时候,树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差。最坏的情况会退化成链表。所以,B+树更适合作为MySQL索引结构。
B树:因为B+的分支结点存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,而由于B+树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可。所以B+树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以B+树更适合用于数据库索引。
having的作用
having 用来分组查询后指定一些条件来输出查询结果,having作用和where类似,但是having只能用在group by场合,并且必须位于group by之后order by之前。
SELECT cust_id, COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
聚簇索引
聚集索引的叶子节点就是整张表的行记录。InnoDB 主键使用的是聚簇索引。聚集索引要比非聚集索引查询效率高很多。聚集索引叶子节点的存储是逻辑上连续的,使用双向链表连接,叶子节点按照主键的顺
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









