







1.构建mahout要的系统事先安装(本人使用)
JDK1.7版本
hadoop-0.20.2(hadoop-0.20.2.tar.gz)
2.安装
mahout-distribution-0.9.tar.gz
下载:http://mirrors.hust.edu.cn/apache/mahout/0.9/
解压:tar zxvf mahout-distribution-0.9.tar.gz
修改环境变量:vi /etc/profile
export MAHOUT_HOME=/home/hadoop/mahout-distribution-0.9(添加)
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$MAVEN_HOME/bin:$MAHOUT_HOME/bin:$PATH(修改红色地方)
测试:
mahout-distribution-0.9/bin 运行:./mahout -help(打印出mahout所有的算法)
如果出现以下信息,说明安装成功
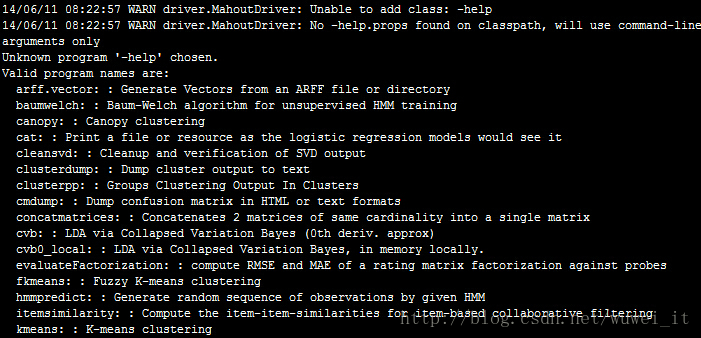
测试运行算法
a.启动hadoop,hadoop-0.20.2/bin/,./start-all.sh
b.查看是否启动成功:jps,如果出现以下数据,说明hadoop启动成功
-bash-3.2$ jps
28200 SecondaryNameNode
28285 JobTracker
31978 Jps
27957 NameNode
28088 DataNode
28394 TaskTrackerc.下载一个文件synthetic_control.data,
下载地址http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data,并把这个文件放在$MAHOUT_HOME目录下。
d. 创建测试目录testdata,并把数据导入到这个testdata目录中(这里的目录的名字只能是testdata)
hadoop fs -mkdir testdata
hadoop fs -ls(查看)
结果:
Found 2 items drwxr-xr-x - root supergroup 0 2014-06-11 08:06 /user/hadoop/output drwxr-xr-x - root supergroup 0 2014-06-11 08:01 /user/hadoop/testdata
hadoop fs -put /home/hadoop/mahout-distribution-0.9/synthetic_control.data testdata(导入测试数据)
hadoop jar /home/hadoop/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job如果出现java.io.IOException: Not a file: hdfs://localhost:9000/user/admin/ testdata
执行命令:bin/hadoop fs -put testdata/ testdata(本地的testdata目录上传到HDFS上)
hadoop fs -ls output(查看结果)
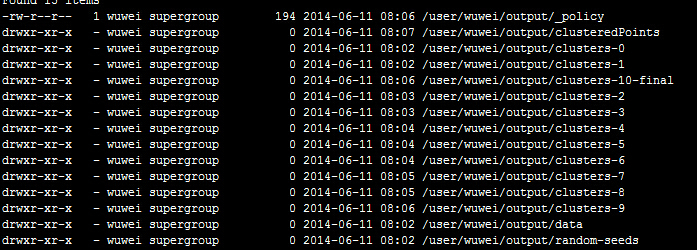
f.查看结果
$HADOOP_HOME/bin/hadoop fs -lsr output
$HADOOP_HOME/bin/hadoop fs -get output $MAHOUT_HOME/examples(将结果从分布式文件系统上导下来)
$cd $MAHOUT_HOME/examples/output
$ls
如果看到以下结果那么算法运行成功,你的安装也就成功了。
clusteredPoints clusters-0 clusters-1 clusters-10 clusters-2 clusters-3 clusters-4 clusters-5 clusters-6 clusters-7 clusters-8 clusters-9 data
备注:
/user/hadop/output/data:存放的是原始数据,这个文件夹下的文件可以用mahout vectordump来读取,原始数据是向量形式的,其它的都只能用mahout seqdumper来读取,向量文件也可以用mahout seqdumper来读取,只是用vectordump读取出来的是数字结果,没有对应的key,用seqdumper读出来的可以看到key,即对应的url,而value读出来的是一个类描述,而不是数组向量。
命令:
mahout vectordump -i /user/hadoop/output/data/part-m-00000
mahout seqdumper -i /user/hadoop/output/data/part-m-00000
有的书上或者资料上要运行下面命令,我在mahout0.9版本测试通不过(可能的原因是版本问题)。
查看job运行情况(hadoop):
http://localhost:50030/jobtracker.jsp(MapReduce的Web页面)
http://10.101.0.69:50070/dfshealth.jsp(HDFS的Web页面)















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









