









安装Hadoop集群
Spark3.3.1的安装软件包是基于Hadoop3.3+的,为了保持兼容性,这里选择使用Hadoop3.3版本。
安装Hadoop
Hadoop软件安装
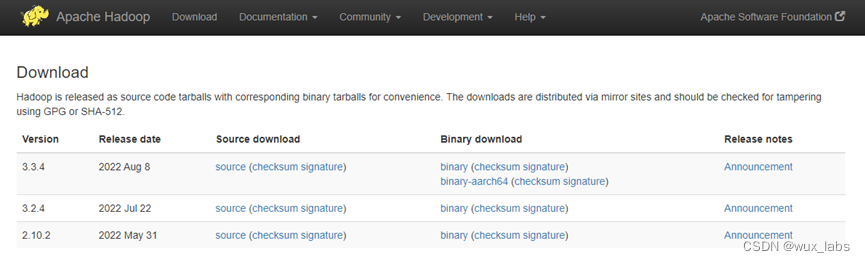
从如图所示的Hadoop下载页面下载Hadoop3.3.4的二进制文件,然后将安装包上传到Linux服务器上。
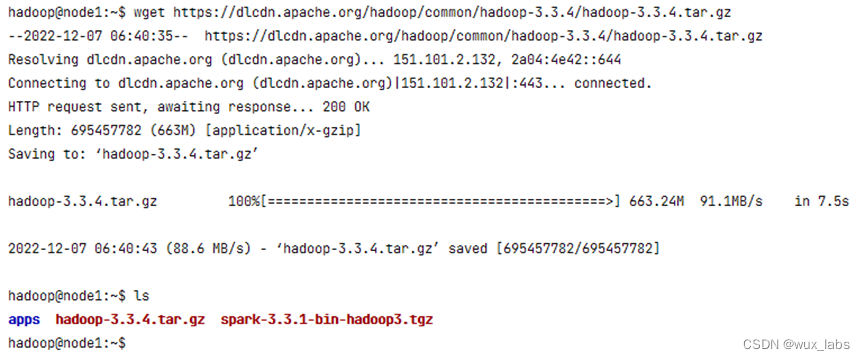
也可以复制下载链接,在服务器上通过wget进行下载。
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
Hadoop的安装也非常简单,解压软件安装包、配置环境变量即可。
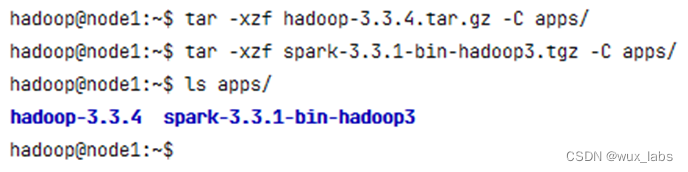
需要在集群的每个节点上都安装Hadoop,可以复制软件安装包到每个节点进行分别安装,也可以将安装好软件的apps目录同步到每个节点上。
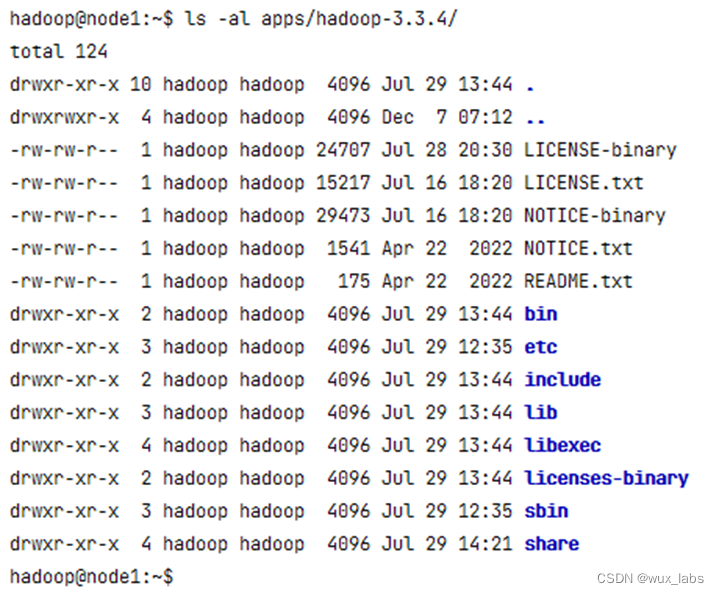
下图展示了Hadoop的目录结构,其中:bin目录下存放的是Hadoop相关的常用命令,比如操作HDFS分布式文件系统的hdfs命令,以及hadoop、yarn等命令;etc目录下存放的是Hadoop的配置文件,对HDFS、MapReduce、Yarn以及集群节点列表的配置都在这个里面;sbin目录下存放的是管理集群相关的命令,比如启动集群、启动HDFS、启动Yarn、停止集群等的命令;share目录下存放了一些Hadoop的相关资源,比如文档以及各个模块的Jar包。
配置免密登录
Hadoop集群的运行,需要各个节点之间实现免密登录,可按照上一节中配置免密登录的步骤配置节点间的免密登录。
$ ssh-keygen -t rsa
$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
$ scp -r .ssh hadoop@node1:~/
$ scp -r .ssh hadoop@node2:~/
$ scp -r .ssh hadoop@node3:~/
$ ssh node1
$ ssh node2
$ ssh node3
配置环境变量
在集群的每个节点上都配置Hadoop的环境变量,Hadoop集群在启动的时候可以使用start-all.sh一次性启动集群中的HDFS和Yarn,为了能够正常使用该命令,需要将其路径配置到环境变量中。
$ vi .bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.4
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置Hadoop集群
Hadoop软件安装完成后,每个节点上的Hadoop都是独立的软件,需要进行配置才能组成Hadoop集群。Hadoop的配置文件在$HADOOP_HOME/etc/hadoop目录下,主要配置文件有6个:hadoop-env.sh主要配置Hadoop环境相关的信息,比如安装路径、配置文件路径等;core-site.xml是Hadoop的核心配置文件,主要配置了Hadoop的NameNode的地址、Hadoop产生的文件目录等信息;hdfs-site.xml是HDFS分布式文件系统相关的配置文件,主要配置了文件的副本数、HDFS文件系统在本地对应的目录等;mapred-site.xml是关于MapReduce的配置文件,主要配置MapReduce在哪里运行;yarn-site.xml是Yarn相关的配置文件,主要配置了Yarn的管理节点ResourceManager的地址、NodeManager获取数据的方式等;workers是集群中节点列表的配置文件,只有在这个文件里面配置了的节点才会加入到Hadoop集群中,否则就是一个独立节点。这几个配置文件如果不存在,可以通过复制配置模板的方式创建,也可以通过创建新文件的方式创建。需要保证在集群的每个节点上这6个配置保持同步,可以在每个节点单独配置,也可以在一个节点上配置完成后同步到其他节点。
hadoop-env.sh配置
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME= /usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.4
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export HADOOP_LOG_DIR=/home/hadoop/logs/hadoop
core-site.xml配置
$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/works/hadoop/temp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml配置
$ vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/works/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/works/hadoop/hdfs/data</value>
</property>
</configuration>
mapred-site.xml配置
$ vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
yarn-site.xml配置
$ vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
workers配置
$ vi $HADOOP_HOME/etc/hadoop/workers
node1
node2
node3
启动Hadoop集群
在所有节点上都安装完成Hadoop软件,完成所有节点的环境变量、配置文件的配置,在启动集群之前还需要进行NameNode的格式化操作,在NameNode所在的node1节点上执行格式化命令。
$ hdfs namenode -format
NameNode格式化完成后,在node1上执行集群启动命令start-all.sh启动Hadoop集群,包括HDFS和Yarn。下图展示了Hadoop集群的启动过程。
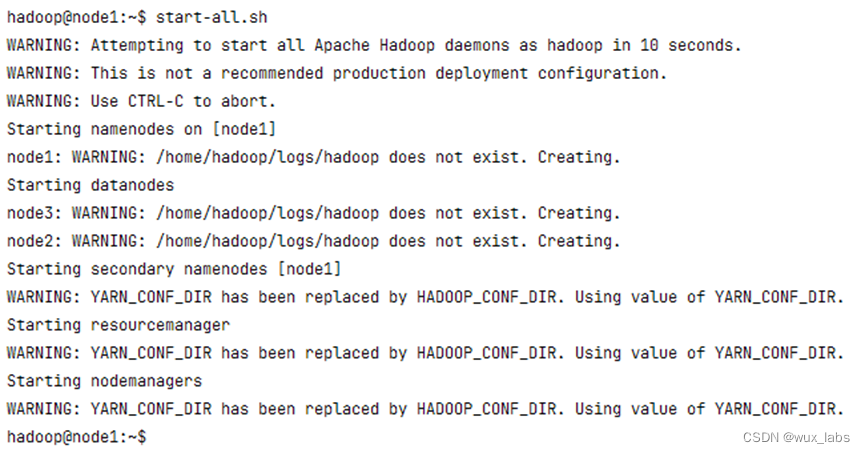
下图展示了Hadoop集群启动后各个节点的进程信息。对于HDFS分布式文件系统,每个节点都是DataNode,node1是NameNode;对于Yarn资源调度框架,每个节点都是NodeManager,node1是ResourceManager。
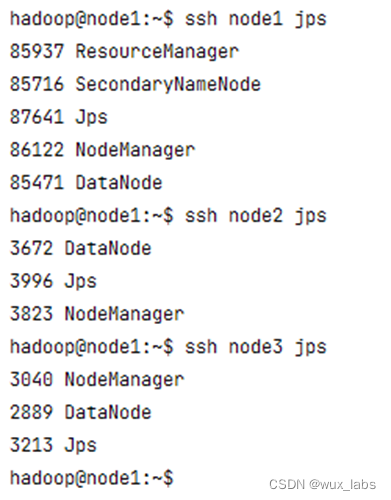
Hadoop3中HDFS的Web端口默认是9870,通过浏览器可以访问Web界面。下图展示了集群的概览信息。
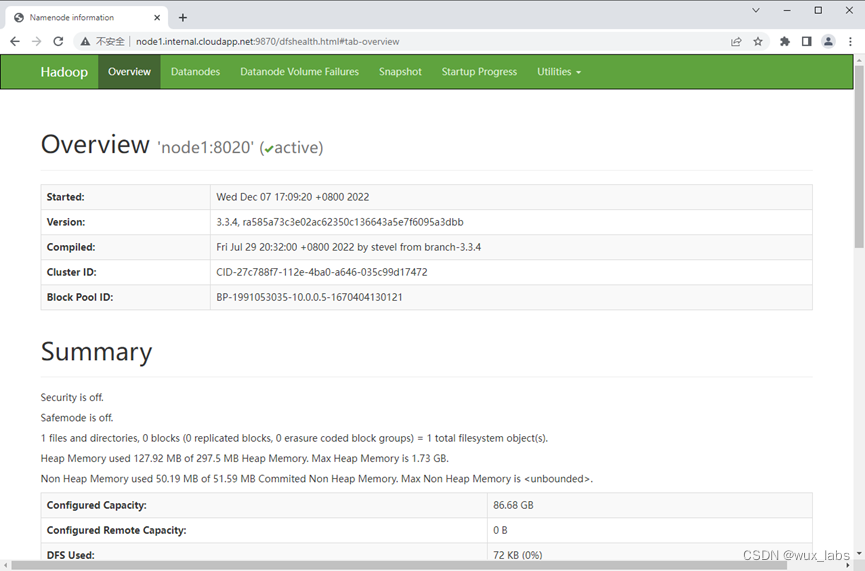
集群中DataNode的列表。
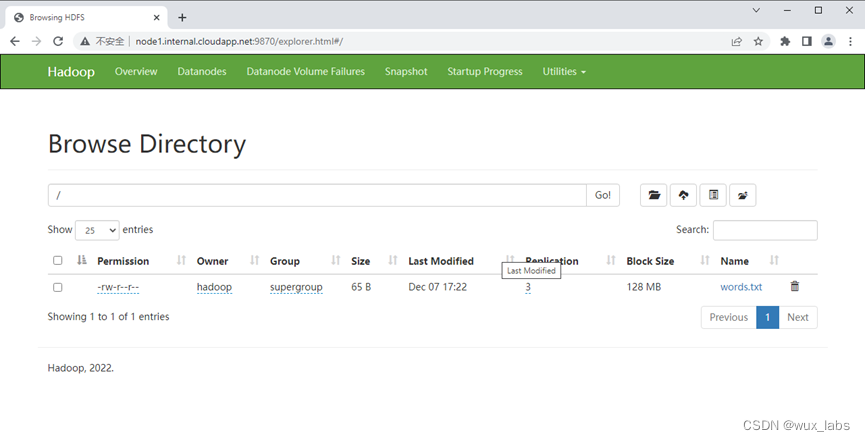
可以通过hdfs命令将words.txt文件上传到HDFS分布式文件系统上。
$ hdfs dfs -put words.txt /
通过Web界面浏览HDFS分布式文件系统上的文件。
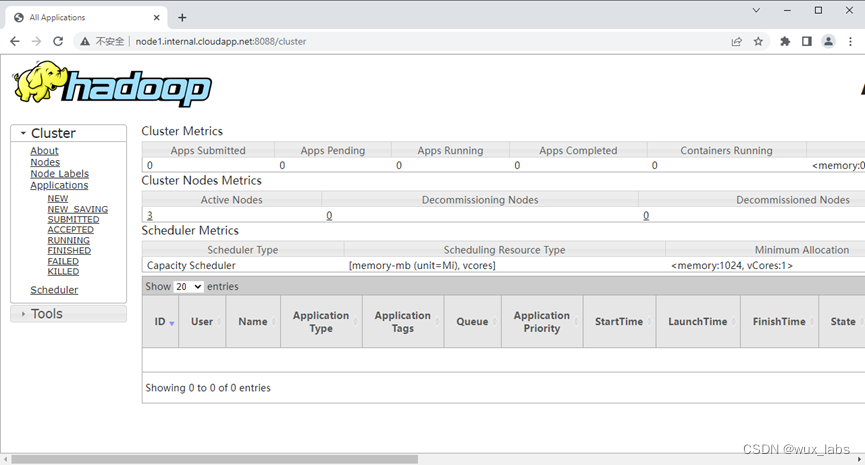
Yarn的Web界面的默认端口是8088,使用浏览器访问该端口可以查看Yarn的信息。
自此,Hadoop集群安装完成。
















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











