







这个题目是典型的利用tarjan算法求取最近公共祖先的题目
#include<cstdio>
using namespace std;
const int mm=1111111;
const int mn=1111;
int t[mm],p[mm];
int h[mn],q[mn],f[mn],sum[mn];
bool vis[mn];
int i,j,k,c,e,n;
int find(int u)
{
if(f[u]==u)return u;
else return f[u]=find(f[u]);
}
bool tarjan(int u)
{
int i,v;
for(i=q[u];i;i=p[i])
if(vis[v=t[i]])++sum[find(v)];
vis[f[u]=u]=1;
for(i=h[u];i;i=p[i])
if(!vis[v=t[i]])tarjan(v),f[v]=u;
return 0;
}
inline bool get(int &a)
{
char c;
while(((c=getchar())<'0'||c>'9')&&c!=EOF);
if(c==EOF)return 0;
for(a=0;c>='0'&&c<='9';c=getchar())a=a*10+c-'0';
return 1;
}
int main()
{
while(get(n))
{
for(i=1;i<=n;++i)sum[i]=h[i]=q[i]=f[i]=vis[i]=0;
for(c=e=1;c<=n;++c)
{
get(i),get(k);
while(k--)get(j),++f[t[e]=j],p[e]=h[i],h[i]=e++;
}
get(k);
while(k--)
{
get(i),get(j);
t[e]=j,p[e]=q[i],q[i]=e++;
t[e]=i,p[e]=q[j],q[j]=e++;
}
for(i=1;i<=n;++i)
if(!f[i])tarjan(i);
for(i=1;i<=n;++i)
if(sum[i])printf("%d:%d\n",i,sum[i]);
}
return 0;
} 上面的这个算法优化的比较厉害,但是需要很高的理解能力和基础才能写出
对于最近公共祖先问题,我们先来看这样一个性质,当两个节点(u,v)的最近公共祖先是x时,那么我们可以确定的说,当进行后序遍历的时候,必然先访问完x的所有子树,然后才会返回到x所在的节点。这个性质就是我们使用Tarjan算法解决最近公共祖先问题的核心思想。
同时我们会想这个怎么能够保证是最近的公共祖先呢?我们这样看,因为我们是逐渐向上回溯的,所以我们每次访问完某个节点x的一棵子树,我们就将该子树所有节点放进该节点x所在的集合,并且我们设置这个集合所有元素的祖先是该节点x。那么到我们完成对一个节点的所有子树的访问时,我们将这个节点标记为已经找到了祖先的点。
这个时候就体现了Tarjan采用离线的方式解决最近公共祖先的问题特点所在了,所以这个时候就体现了这一点。假设我们刚刚已经完成访问的节点是a,那么我们看与其一同被询问的另外一个点b是否已经被访问过了,若已经被访问过了,那么这个时候最近公共祖先必然是b所在集合对应的祖先c,因为我们对a的访问就是从最近公共祖先c转过来的,并且在从c的子树b转向a的时候,我们已经将b的祖先置为了c,同时这个c也是a的祖先,那么c必然是a、b的最近公共祖先。
对于一棵子树所有节点,祖先都是该子树的根节点,所以我们在回溯的时候,时常要更新整个子树的祖先,为了方便处理,我们使用并查集维护一个集合的祖先。总的时间复杂度是O(n+q)的,因为dfs是O(n)的,然后对于询问的处理大概就是O(q)的。
这就是离线的Tarjan算法,可能说起来比较难说清楚,但是写起来还是比较好写。下面贴上我在POJ 1470上过的题的代码,简单的LCA问题的求解。
/*
author UESTC_Nowitzki
*/
#include <iostream>
#include <cstring>
#include <cstdio>
#include <cstdlib>
#include <vector>
using namespace std;
const int MAX=1000;
int indegree[MAX];
int ancestor[MAX];
int set[MAX];
int vis[MAX];
int time[MAX];
vector<int> adj[MAX];
vector<int> que[MAX];
void init(int n)
{
memset(time,0,sizeof(time));
memset(vis,0,sizeof(vis));
memset(indegree,0,sizeof(indegree));
for(int i=1;i<=n;i++)
{
adj[i].clear();
que[i].clear();
set[i]=i;
ancestor[i]=i;
}
}
int find(int k)
{
int r=k;
while(set[r]!=r)
r=set[r];
int i=k,j;
while(set[i]!=r)
{
j=set[i];
set[i]=r;
i=j;
}
return r;
}
void dfs(int i)
{
int len=adj[i].size();
for(int j=0;j<len;j++)
{
int son=adj[i][j];
dfs(son);
set[son]=i;
ancestor[find(i)]=i;
}
vis[i]=1;
len=que[i].size();
for(int j=0;j<len;j++)
{
int son=que[i][j];
if(vis[son])
{
int ans=ancestor[find(son)];
time[ans]++;
}
}
}
int main()
{
int n,i,t,a,b;
while(scanf("%d",&n)!=EOF)
{
init(n);
for(i=0;i<n;i++)
{
scanf("%d:(%d)",&a,&t);
while(t--)
{
scanf("%d",&b);
indegree[b]++;
adj[a].push_back(b);
}
}
scanf("%d",&t);
while(t--)
{
while(getchar()!='(');
scanf("%d%d",&a,&b);
que[a].push_back(b);
que[b].push_back(a);
}
while(getchar()!=')');
for(i=1;i<=n;i++)
{
if(indegree[i]==0)
{
// printf("root=%d\n",i);
dfs(i);
break;
}
}
for(i=1;i<=n;i++)
{
if(time[i]>0)
printf("%d:%d\n",i,time[i]);
}
}
return 0;
} 其实这些个有着固定解法的题目都是有模板的。
这些模板是需要掌握和理解的东西。
#include<iostream>
#include<algorithm>
#include<cstdio>
#include<vector>
using namespace std;
#define MAX 10001
int f[MAX];
int r[MAX];
int indegree[MAX];
int visit[MAX];
vector<int> hash[MAX],Qes[MAX];
int ancestor[MAX];
void init(int n)
{
int i;
for(i=1;i<=n;i++)
{
r[i]=1;
f[i]=i;
indegree[i]=0;
visit[i]=0;
ancestor[i]=0;
hash[i].clear();
Qes[i].clear();
}
}
int find(int n)
{
if(f[n]==n)
return n;
else
f[n]=find(f[n]);
return f[n];
}//查找函数,并压缩路径
int Union(int x,int y)
{
int a=find(x);
int b=find(y);
if(a==b)
return 0;
else if(r[a]<=r[b])
{
f[a]=b;
r[b]+=r[a];
}
else
{
f[b]=a;
r[a]+=r[b];
}
return 1;
}//合并函数,如果属于同一分支则返回0,成功合并返回1
void LCA(int u)
{
ancestor[u]=u;
int i,size = hash[u].size();
for(i=0;i<size;i++)
{
LCA(hash[u][i]);
Union(u,hash[u][i]);
ancestor[find(u)]=u;
}
visit[u]=1;
size = Qes[u].size();
for(i=0;i<size;i++)
{
if(visit[Qes[u][i]]==1)
{
printf("%d\n",ancestor[find(Qes[u][i])]);
return;
}
}
}
int main()
{
int testcase;
int n;
int i,j;
scanf("%d",&testcase);
for(i=1;i<=testcase;i++)
{
scanf("%d",&n);
init(n);
int s,t;
for(j=1;j<=n-1;j++)
{
scanf("%d%d",&s,&t);
hash[s].push_back(t);
indegree[t]++;
}
scanf("%d%d",&s,&t);
Qes[s].push_back(t);
Qes[t].push_back(s);
for(j=1;j<=n;j++)
{
if(indegree[j]==0)
{
LCA(j);
break;
}
}
}
return 0;
}
这个解法也是对的,但是有很多冗余在里面的
关于tarjan的离线算法求解LCA的算法,下面进行模拟求解
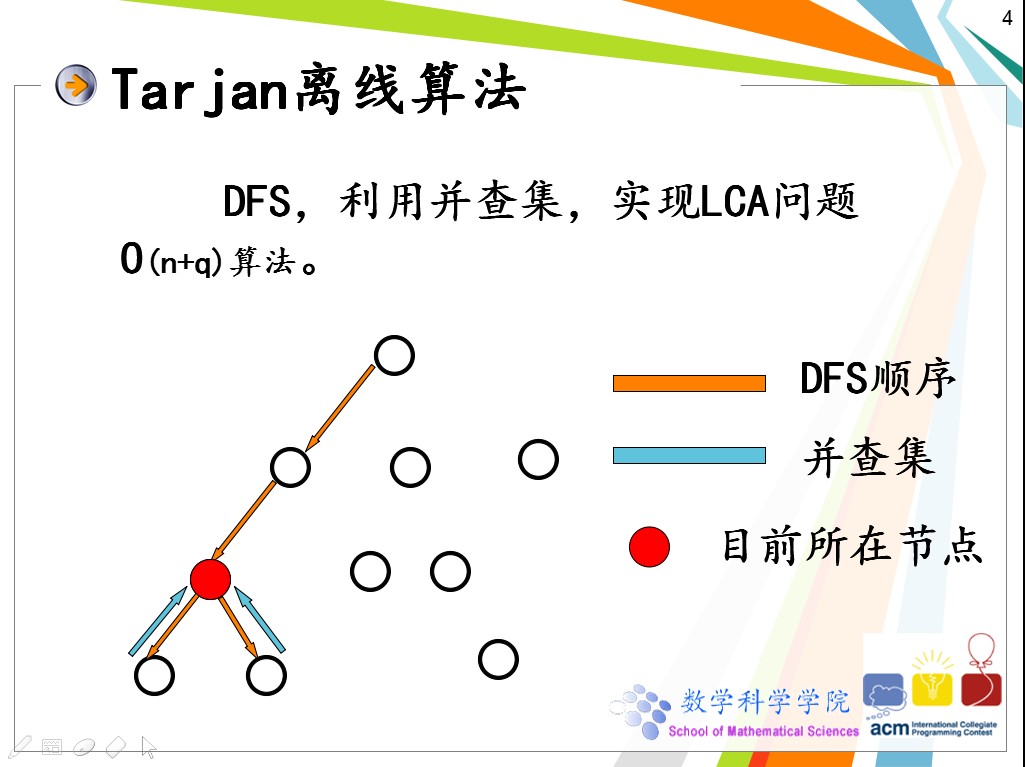
比如求取最左下面两个点的LCA 下面进行模拟
LCA会为所有要查询的节点建立一个邻接表,是以链表的形式储存
1 首先找到根节点
2 其次通过根节点向下遍历,有点像后序遍历树的操作(其实就是)
3在每一次遍历的时候要进行下面的操作
(1)将儿子节点放入递归循环中
(2)将儿子节点的并查集标志值设置为父亲
3 将节点的祖先设置为本身
在将一个节点的儿子节点遍历结束之后
进行查询的判断,首先这个节点必然已经被访问过了
然后判断是否有要查询的查询对包含此节点并且另外一个节点也已经被访问过了
如果被访问过了,那么就可以输出另外一个节点父节点的祖先
就是二者的最近祖先















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









