









Intro
有一天我在写爬虫。
其实也说不上是爬虫,就是打开浏览器上网,觉得页面有些数据挺有意思,就打开开发者工具,在 Network/Console 中通过 javascript 原生的 fetch 方法 批量、自动地请求一些web资源。
其中有一个关节,是以下的需求:
有一些字符串格式的HTML源码,需要将其转换为 document 对象(DOM对象),
这样我就可以在 console 直接使用选择器(selector)对该HTML文档的文本内容进行过滤清洗处理。
QA
问题来了,如何将 字符串格式的HTML源码 转化为 document类型的DOM对象 ?
答案分两种情况:
cheerio- 在 node 编程环境(需要有相关的类库支持)DOMParser在浏览器控制台(需要有原生 javascript 的 API 支持)
DOMParser 在 console 的使用
MDN DOMParser https://developer.mozilla.org/zh-CN/docs/Web/API/DOMParser
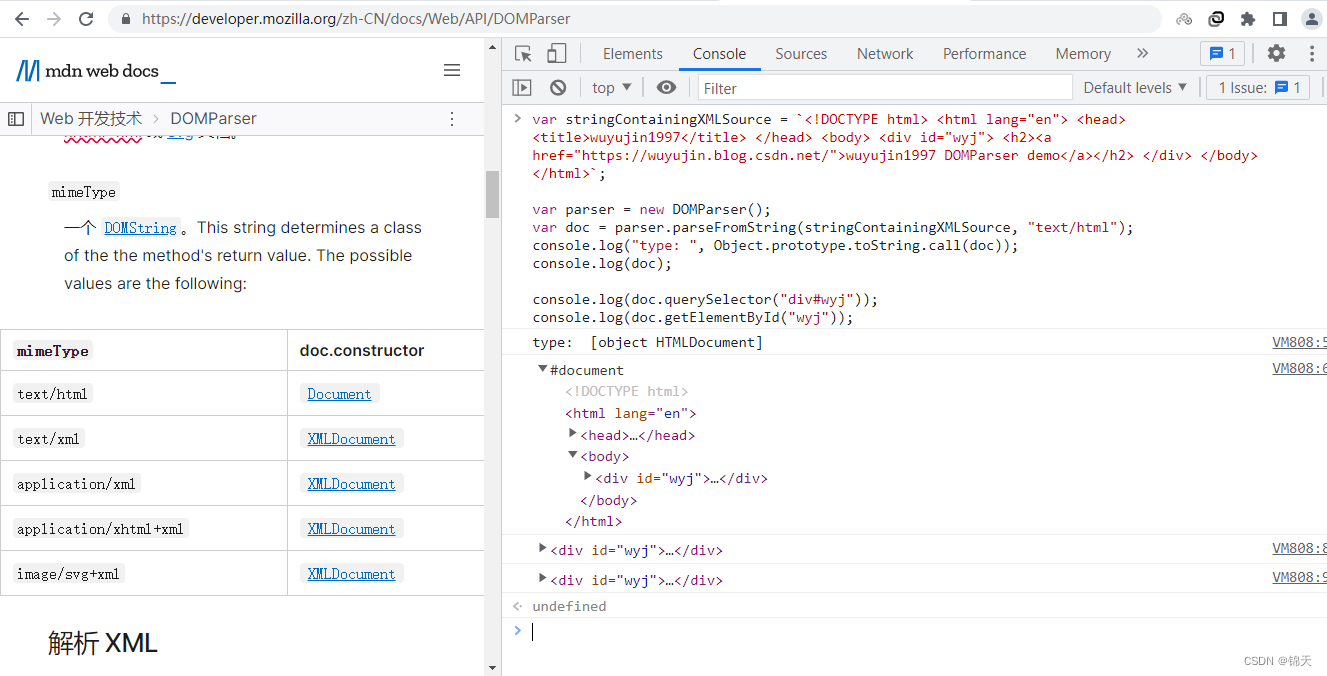
var stringContainingXMLSource = `<!DOCTYPE html> <html lang="en"> <head> <title>wuyujin1997</title> </head> <body> <div id="wyj"> <h2><a href="https://wuyujin.blog.csdn.net/">wuyujin1997 DOMParser demo</a></h2> </div> </body> </html>`;
var parser = new DOMParser();
var doc = parser.parseFromString(stringContainingXMLSource, "text/html");
// 这个 doc 对象就是整个HTML文档的 DOM对象
console.log("type: ", Object.prototype.toString.call(doc));
console.log(doc);
// document 的 DOM对象 可以开始调用原生API通过选择器对子节点进行操作了。
console.log(doc.querySelector("div#wyj"));
console.log(doc.getElementById("wyj"));
 这个 DOMParser 不止可以解析 html,也可以解析 xml。
这个 DOMParser 不止可以解析 html,也可以解析 xml。
不同类型下的 mimeType 见下表:
"mimeType"
"text/html"
"text/xml"
"application/xml"
"application/xhtml+xml"
"image/svg+xml"
cheerio 在 node 项目中的使用
https://cheerio.js.org/
https://www.npmjs.com/package/cheerio
var cheerio = require("cheerio");
var htmlSourceString = `<!DOCTYPE html> <html lang="en"> <head> <title>wuyujin1997</title> </head> <body> <div id="wyj"> <h2><a href="https://wuyujin.blog.csdn.net/">wuyujin1997 DOMParser demo</a></h2> </div> </body> </html>`;
var cheerioOptions = {
xml: {
withDomLvl1: true,
normalizeWhitespace: false,
xmlMode: true,
decodeEntities: true,
},
};
const $ = cheerio.load(htmlSourceString, cheerioOptions);
console.log($.html());
console.log($.text());
var myDiv = $("div#wyj");
// 用选择器获取的DOM节点对象 也可以调用 .html() .text()
Reference
DOMParser 是从字符串格式的HTML源码中解析出一个document类型的DOM对象。
而 XMLSerializer 的作用则正好相反。
当然,有了document 或其他DOM节点,想获取内容,还有 innerText innerHTML outerText outerHTML 等dom对象的成员属性可以使用。
innerHTML, innerText, outerHTML, outerText的区别
- 邱仲麟 明代北京的瘟疫与帝国医疗体系的应变
- 99藏书网 夜谭十记
这个网站对于 network response 中的HTML源码做了一些DOM节点顺序的技术处理。
测试
邱仲麟 明代北京的瘟疫与帝国医疗体系的应变 https://www.docin.com/p-1077305105.html
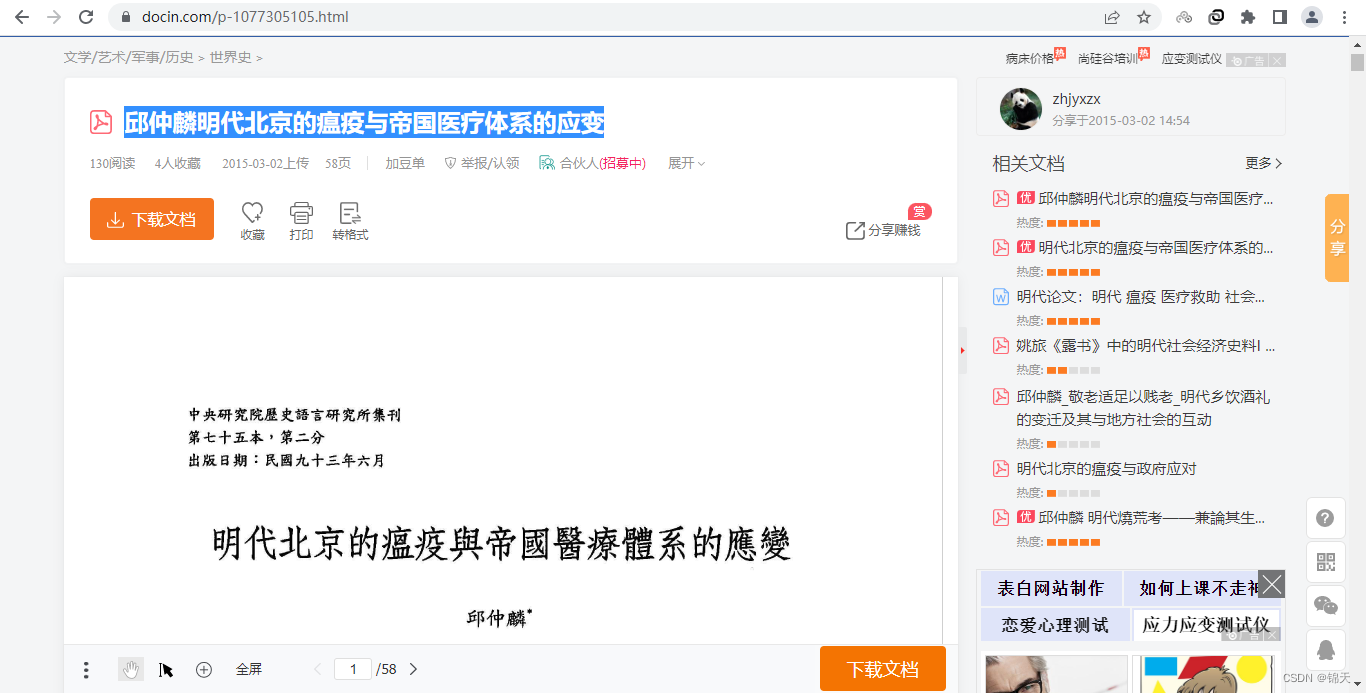
打开 F12 Network,然后把网页下拉,可以看到新发送的网络请求:
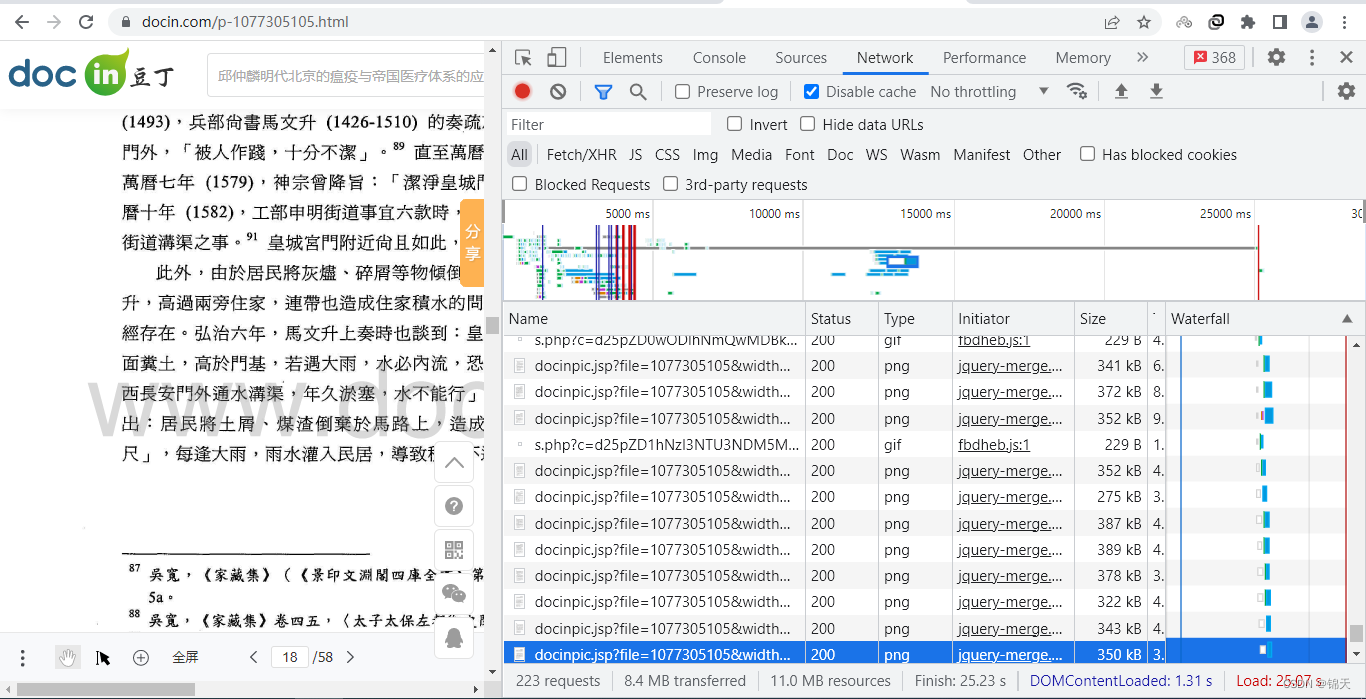
这样的请求共有58个(就是网页里的页码,上图中可以看到),每个请求就是一张图片:
/**
* https://www.docin.com/p-1077305105.html
* 邱仲麟 《明代北京的瘟疫与帝国医疗体系的应变》
*/
function saveStringToFile(filename, blobFile) {
// 创建一个 <a> 标签对象
var linkTag = window.document.createElement("a");
// 设置该实例的 download 和 href 属性(HTML 5 标准属性)
linkTag.download = filename;
linkTag.href = window.URL.createObjectURL(blobFile);
// 把刚才手动创建的 <a> 添加到 DOM 文档中
window.document.body.appendChild(linkTag);
linkTag.click(); // 调用点击事件
// 移除刚才添加的子标签
window.document.body.removeChild(linkTag);
}
function downloadIt(fileName, url) {
fetch(url, {
"headers": {
"accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": "\"Chromium\";v=\"106\", \"Google Chrome\";v=\"106\", \"Not;A=Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "image",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-site"
},
"referrer": "https://www.docin.com/p-1077305105.html",
"referrerPolicy": "no-referrer-when-downgrade",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
}).then(resp => {
return resp.blob();
}).then(data => {
saveStringToFile(fileName, data);
})
}
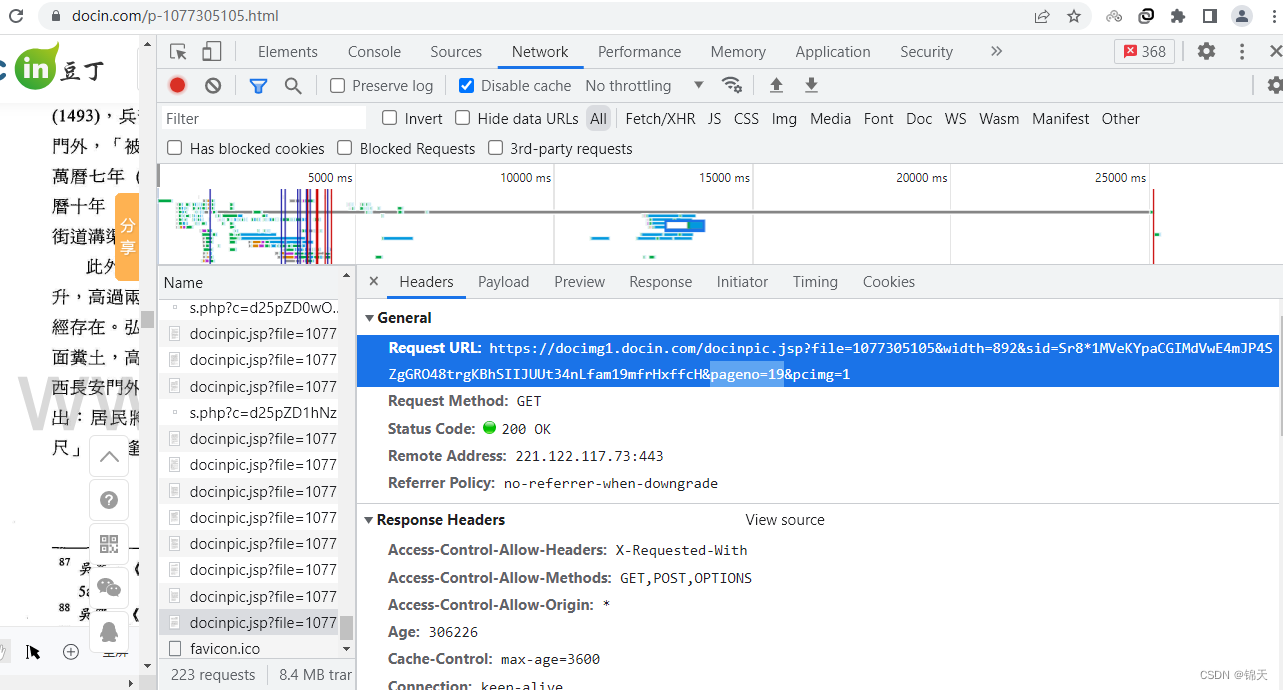
// `https://docimg1.docin.com/docinpic.jsp?file=1077305105&width=892&sid=Sr8*1MVeKYpaCGIMdVwE4mJP4SZgGRO48trgKBhSIIJUUt34nLfam19mfrHxffcH&pageno=19&pcimg=1`;
// `https://docimg1.docin.com/docinpic.jsp?file=1077305105&width=892&sid=Sr8*1MVeKYpaCGIMdVwE4mJP4SZgGRO48trgKBhSIIJUUt34nLfam19mfrHxffcH&pageno=${pageno}&pcimg=1`;
for (var i = 1; i <= 58; i++) {
var pageno = i;
// 这个URL需要随时替换。因为 session 会失效。
var url = `https://docimg1.docin.com/docinpic.jsp?file=1077305105&width=892&sid=Sr8*1MVeKYpaCGIMdVwE4mJP4SZgGRO48trgKBhSIIJUUt34nLfam19mfrHxffcH&pageno=${pageno}&pcimg=1`;
downloadIt(pageno + ".png", url);
}
结果:
如果有法子把多张图片合并成一个pdf文件就好了。
需求: 多张任意格式的图片-->一个pdf文件。
有很多网站提供这样的服务,但是要么要注册,要么充钱,要么页面有广告病毒,要么你不会用……
有没有办法自己写程序实现以上的需求?
当然可以。
不然别人的网站是拿什么写的?
搜索javascript Blob File,自己实现。
sum
最后一句话:
javascript+浏览器+网络,已经可以做很多事了。
但是,要正确使用工具。
学习是学习,不要影响他人的利益。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









