







内容从音视频开发的角度去了解声音
一 声音产生的基本原理
从以前学物理可以了解到声音的产生是靠振动,可以在空气、水、固体中传播。我们日常接触到的声音主要是从空气中传播过来的,通过耳廓收集声音,然后通过耳道传入,最后通过听觉神经传入到大脑中进行解析。
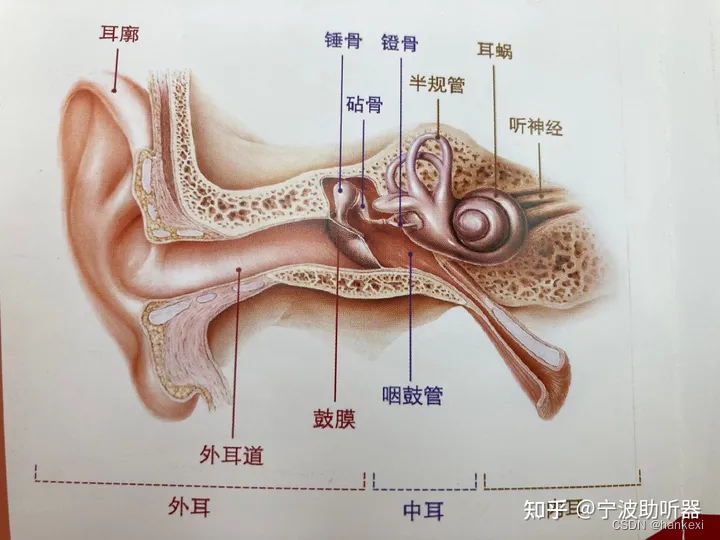
二 人的听觉范围
一般情况下,人只能听到20-20000hz频率的声音,低于20的被称作次声波,高于20000的被称作超声波。
三 音频数字化
声音属于模拟信号,如果需要在计算机传输和处理声音,需要使用ADC模数转换器,将模拟信号转为数字信号,那么声音是如何被采集的呢。
1采样率
采样率就是1秒内采集到的采样点的个数,一般用赫兹Hz来表示。比如1秒有44100个采样点那么采样率就是44100Hz(44.1kHz)。
2采样精度
采样精度可以理解为每个采样点的值可以取的范围,范围越大,还原出来的声音越接近现实。比如电视遥控器调电视声音范围如果是0-100比0-50更能调出合适的声音。通常采样精度是16位的浮点数。
3 声道数
通常是左右双声道。
四 数字音频的其他属性
1比特率
比特率通常可以被叫做码率,一个是编码后的数据,一个是解码后的数据(编解码方面的内容需要看ffmpeg)
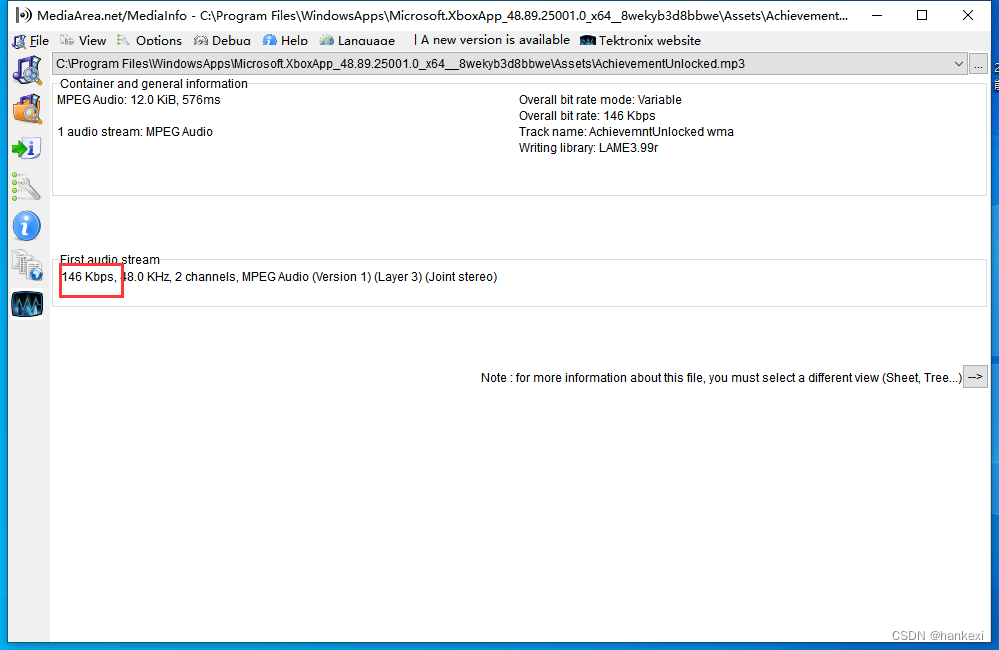
通常音频比特率可以使用mediainfo这个工具去查看,比如这个音频是146Kbps,代表一秒钟的音频数据有146k大小,通常比特率越大代表音质越好。
五 音频编解码
视频有视频编码器,音频也有音频编码器。比如常用的有aac等。它可以将原始音频数据进行压缩,比如一首无损音乐有30-40M大小左右,通过压缩后只有3-4M大小。因此在网络传输过程中可以节约大量的带宽。
六 扩充
AAC 的ADTS数据格式
aac有两种数据格式ADIF和ADTS,ADIF不常用,最常用的是ADTS格式。
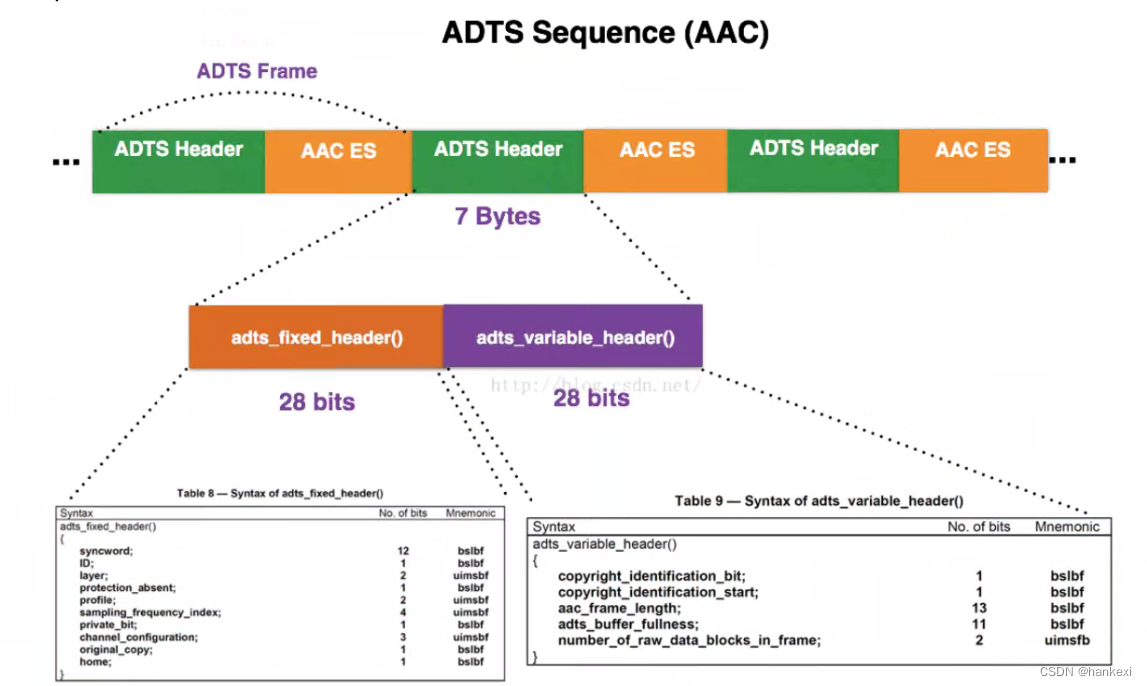
ADTS格式每一帧音频数据都有头部加上一个音频数据。
比如下图,ADTS头部通常有7字节和9字节两种,下面是7字节的情况。
包含了28位的固定头部和28位的变动头部数据,固定头部数据对于每一帧音频来说都是一样的。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









