







吴老师 的 深度 学习 中 关于 jazz solo练习中,关于生成 时的困惑:
1. 直接调用 predict_and_sample
2. 看 predict_and_sample 实现:
def predict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer,
c_initializer = c_initializer):
"""
Predicts the next value of values using the inference model.
Arguments:
inference_model -- Keras model instance for inference time
x_initializer -- numpy array of shape (1, 1, 78), one-hot vector initializing the values generation
a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell
c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel
Returns:
results -- numpy-array of shape (Ty, 78), matrix of one-hot vectors representing the values generated
indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated
"""
### START CODE HERE ###
# Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer.
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
# Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities
print("pred values are ")
print(pred[0])
print("pred values end ")
indices = np.argmax(pred, axis=2)
print(indices.shape)
# Step 3: Convert indices to one-hot vectors, the shape of the results should be (1, )
results = to_categorical(indices)
### END CODE HERE ###
return results, indices
看以上标红部分,直接 使用了predict,但是 没有 使用 compile以及fit既然可以直接使用predict(fit的主要作用就是找到相关参数,而后 predict时,只需要传入输入 既可以 直接使用该模型),怎么回事呢?
针对这个问题,仔细查看了jazz solo的说明,有一块内容:

这句话什么意思呢?意思就是 创建了一个全局变量,然后只需要 训练一次,以后就可以 共享层对象的权重。
然后 也查了 https://keras-cn.readthedocs.io/en/latest/getting_started/functional_API/#_4 文档,上面写的如下

意思 也是可以共用。
我这边也以这个思想进行验证(jazz solo)
1. 先不进行 上面的 模型fit,直接 使用 生成方法,结果如下:(预测结果完全一样,肯定是不对的,说明lstm的权重就没有经过训练)

2. 执行 train, 然后 执行predict_and_sample方法如下:(预测结果值是有 变化)
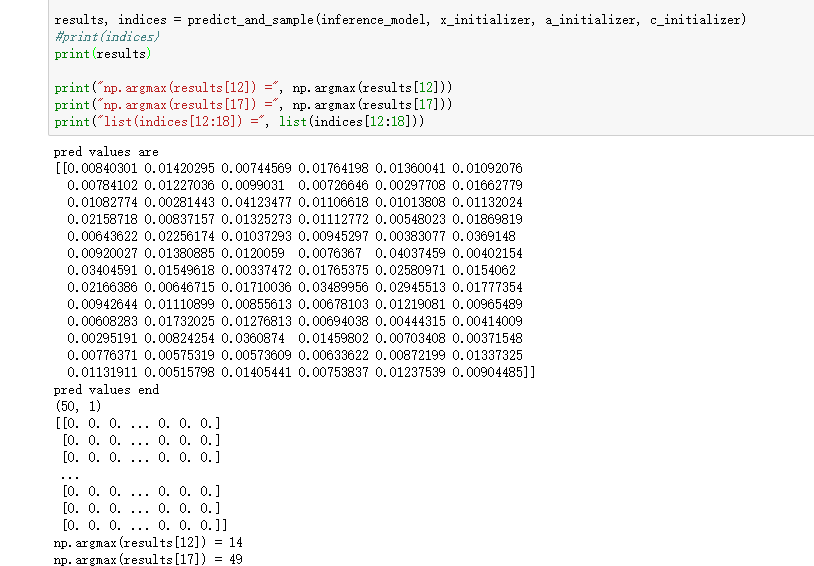
从训练的模型参数,也可以看出:
1) 此参数是单独训练的权重

2)下面这张图是,不执行前半部分的fit时,单独执行 predict_and_sample,时的权重
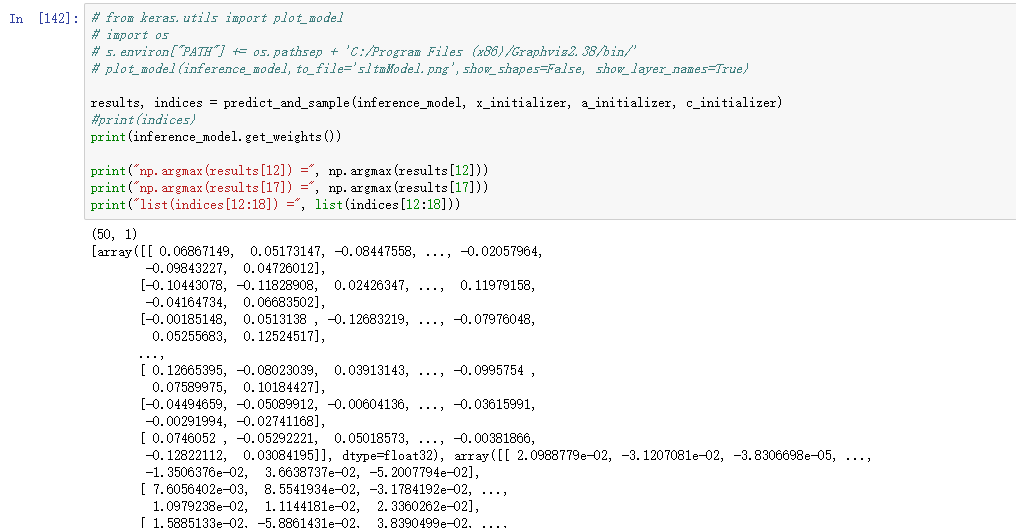
由1)和2)知,权重明显不一致,也就是说不是相同的模型
3) 执行前半部分fit,权重:
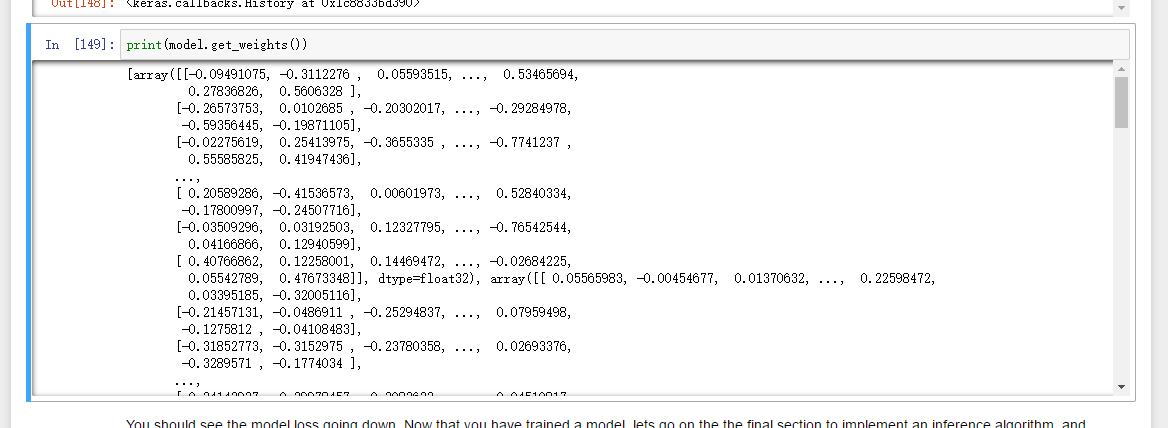
4) 执行完前半部分,然后执行 predict_and_sample,模型权重
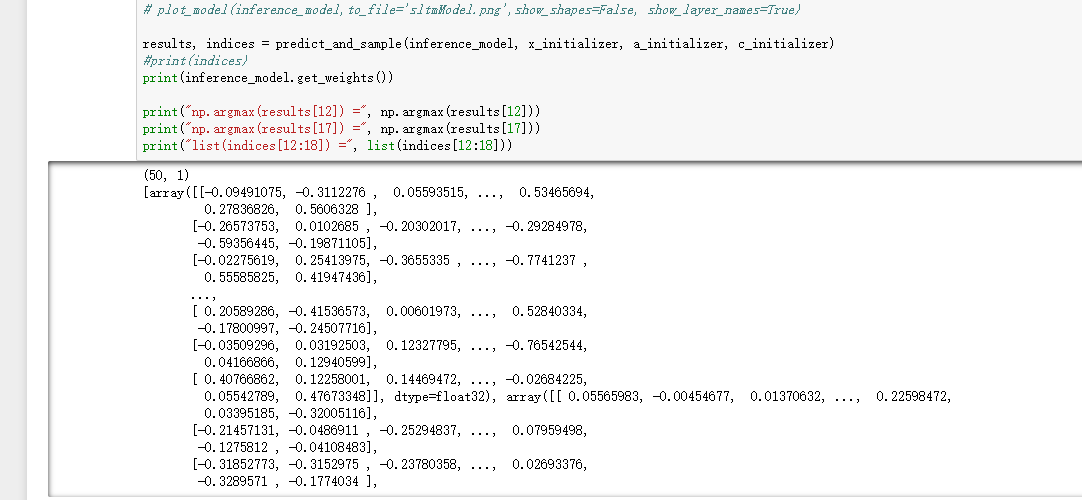
由3)和4)知,使用的是相同的模型,也说明了 去权重共享的问题
有什么理解 不对的,可以讨论
知乎: https://zhuanlan.zhihu.com/albertwang
微信公众号:AI-Research-Studio

下面是赞赏码

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









