






1 数据的集中趋势
均值:易受极值的影响,可以使用加权平均值来消除极值的影响,但是可能事先并不清楚数据的权重。
中位数:描述了数据的中等水平,对数据变化不敏感
众数:众数不受极值的影响,但是无法保证唯一性和存在性
excel函数:AVERAGE、MEDIAN、MODE函数分别计算均值、中位数和众数。
求中位数也可以使用QUARTILE.EXC或QUARTILE.INC函数,将第二个参数设置为2。

2 数据的离散趋势
极值:极大值、极小值,在Excel中,计算极值的函数是MAX和MIN。
极差:又称“全距”,极大值 - 极小值 ,记作R;极差越大,离散程度越大。
四分位距离: IQR = Q_3 - Q_1
方差:表示数据与期望值的偏离程度。方差越大,就意味着数据越不稳定、波动越剧烈,因此代表着数据整体比较分散,呈现出离散的趋势;而方差越小,意味着数据越稳定、波动越平滑,因此代表着数据整体比较集中。

在Excel中,计算总体方差和样本方差的函数分别是VAR.P和VAR.S。
标准差:将方差进行平方根运算后的结果,与方差一样都是表示数据与期望值的偏离程度。
在Excel中,计算标准差的函数分别是STDEV.P和STDEV.S。
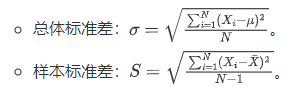
3 数据的频数分析
频数分析是指用一定的方式将数据分组,然后统计每个分组中样本的数量,再辅以图表(如直方图)就可以更直观的展示数据分布趋势的一种方法。
频数分析的意义:
-
大问题变小问题,迅速聚焦到需要关注的群体。
-
找到合理的分类机制,有利于长期的数据分析(维度拆解)。
如:解读一个班有50个学生的语文考试成绩,仅仅依靠上面学过的知识(均值、中位数、众数、最高分、最低分、极差、方差、标准差)很难全面解读学生考试成绩,需要进行频数分析。
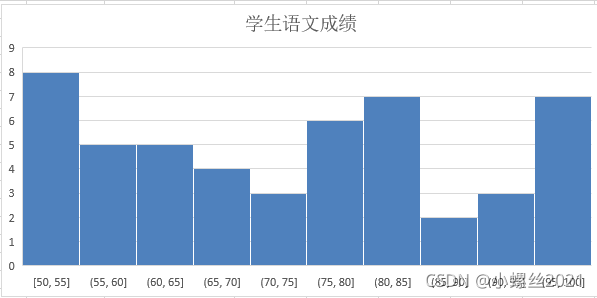
或
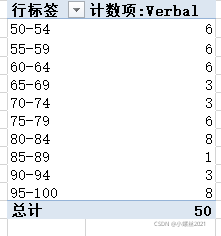
4 数据的概率分布
基本概念
-
随机试验:在相同条件下对某种随机现象进行观测的试验。随机试验满足三个特点:
-
可以在相同条件下重复的进行。
-
每次试验的结果不止一个,事先可以明确指出全部可能的结果。
-
重复试验的结果以随机的方式出现(事先不确定会出现哪个结果)。
-
-
随机变量:如果X指定给概率空间S中每一个事件e有一个实数X(e),同时针对每一个实数r都有一个事件集合A_r与其相对应,其中Ar={e: X(e) <= r},那么X被称作随机变量。从这个定义看出,X的本质是一个实值函数,以给定事件为自变量的实值函数,因为函数在给定自变量时会产生因变量,所以将X称为随机变量。
-
离散型随机变量:数据可以一一列出。
-
连续型随机变量:数据不可以一一列出。
如果离散型随机变量的取值非常庞大时,可以近似看做连续型随机变量。
-
-
概率质量函数 / 概率密度函数:概率质量函数是描述离散型随机变量为特定取值的概率的函数,通常缩写为PMF。概率密度函数是描述连续型随机变量在某个确定的取值点可能性的函数,通常缩写为PDF。二者的区别在于,概率密度函数本身不是概率,只有对概率密度函数在某区间内进行积分后才是概率。
离散型分布
伯努利分布
二项分布
泊松分布
连续分布
均匀分布
指数分布
正态分布
伽马分布
卡方分布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









