






- 针对多个分割符号拆分字符串
- 在字符串开头和结尾做匹配
- 查找和替换文本
- 不区分大小写进行匹配
- 从字符串中去掉不需要的字符
- 字符串连接及结合问题
?
针对多个分割符号拆分字符串
python中str自带的split()方法可以差分字符串但是只能拆分固定的单个的字符,不如按’ ‘(空格)拆分等
用正则表达式re模块中中的split可以解决这个问题
#从line过滤出多个分割符,提取出需要的内容,提取出需要的
__author__ = 'wwh'
import re
line = 'asdf fasd; asdqw, asdqw, awsdasd foo'
#r是原生字符串的意思,会忽略转移字符
#'[;,\s]\s*'意思是匹配[]中任何一个字符包括';',',','\s',在接着可能会包含0个或0个以上的空格字符,\s是空格,*是0个或0个以上
NewLine = re.split(r'[;,\s]\s*', line)
print(NewLine)
正则表达式中的split要比str中的split强大的多,它支持正则表达式
不熟悉正则表达式的可以戳 python的正则表达式
?
在字符串开头和结尾做匹配。
比如匹配指定后缀的文件提取出文件名,指定前缀的url
我们可以使用str中的startswith()和endswith()方法
__author__ = 'wwh'
filename = [
'1.txt',
'2.py',
'3.py',
'4.py',
'5.c'
]
#过滤出.c和.py结尾的文件,注意endswith和startswith参数是一个元组
print([name for name in filename if name.endswith(('.c', '.py'))])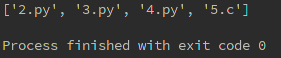
?
查找和替换文本
在给定的字符串中,我们找到指定的字符串并且将它替换掉
简单的替换我们可以用str.replace()来替换,复杂的就要用到re模块的sub方法了
__author__ = 'wwh'
import re
#将11/27/2012日期格式换成2012-11-27`这种
line = 'Today is 11/27/2012, PyCon starts 3/13/2013'
#使用re模块的sub方法
#(\d+)指的是1个或者多个字符,()是捕获组,来捕获指定的字串,'\3-\1-
2'是重新组装日期
ret = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', line)
print(ret)
?
不区分大小写进行匹配
用re.IGNORECASE标记即可,还有其他的标记,比如DOTALL是忽略\n回车的,这在过滤html等文本标记语言非常有用
__author__ = 'wwh'
import re
#过滤出python,要求不区分大小写
line = 'PYTHON, python, PyThOn'
print(re.findall('python', line, re.IGNORECASE))
?
从字符串中去掉不需要的字符
我们想在字符串的开头或中间或结尾去除不必要的字符,比如空格等
strip()方法可以帮我们完成这个任务,lstrip()和rstrip()分别从左边和右边开始,默认情况下去除的是空格,注意去除字符不会对字符串中间的字符起作用,可以结合生成器一起使用,过滤剔除字符
__author__ = 'wwh'
line = ' hello world , good moring '
#剔除首尾的空格
print(line.strip(' '))
lines = [
' hehe ',
'ha haha ',
'xi xi ',
' heihei'
]
#使用生成器
t = (i.strip() for i in lines)
for s in t:
print(s)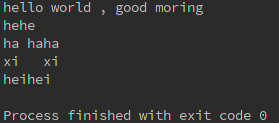
?
字符串连接及结合问题
表面上看这个问题没有什么特别之处,但是我们一般会忽略性能这个问题,比如如下代码
s = 'hello '
t = 'world'
for i in range(10):
s += t‘+=’ 或者’+’操作能很好的完成字符串连接,但是它的性能是非常低的,原因是内存拷贝和垃圾回收产生的影响。这种做法比下面做法慢很多
__author__ = 'wwh'
parts = [
'good',
'morning',
'hello',
'world?'
]
#' '是连接字符串中间穿插的字符,也可以是其他任何字符
#可以针对列表,元组,字典,文件,集合或生成器
print(' '.join(parts))
#使用生成器的join相对更好,因为可以加上一些处理对每个元素,处理过程中完成连接
print(' '.join(s for s in parts))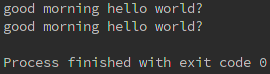
对于简单的我们可以直接使用python的print函数(python3中print编程了函数写法为print()),功能也相应增加了
__author__ = 'wwh'
a = '1'
b = '2'
c = '3'
print(a,b,c,sep = ':', end='\n')
函数如下

注意:
对字符串的操作我们我们需要谨慎,因为如果是大量字符串的话,可能会产生性能问题,比如一个加载大量字符串到内存,会产生内存不足的情况等,此时可以使用生成器yield,含有yield的函数会被编译成生成器对象,这个对象支持迭代器接口,可以迭代的将对象加载进入内存,这样就不需要担心刚才的问题了。
含有yield关键字的函数不像一般函数执行完毕会return退出(生成器函数不允许return),生成器yield函数会在执行完毕后自动挂起暂停状态并保存暂停时的状态,以便于下次继续执行
















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











