









本文是6月4号新鲜出炉的arxiv文章,探索了decoder-only Transformer的表示坍塌和过度压缩问题,感觉其思考很有意思。
论文:《Transformers need glasses!Information over-squashing in language tasks》
1,作者研究了decoder-only Transformers中信息的传播方式,
尤其是最后一层中最后一个token的表示,发现了表示坍塌的现象。
所谓表示坍塌指的是在Transformer模型中,不同的输入序列可能导致最终标记的表示非常接近,甚至在某些情况下无法区分。这种现象在长序列中尤为明显。这种效应在现代LLMs中经常使用的低精度浮点格式下会加剧。
而表示坍塌也是目前众多大模型在涉及计数或复制序列元素等简单任务中出现错误的原因。
2,首先回顾现有工作在“Transformer表示能力”方面的研究。
1)有研究指出Transformer不是图灵完备的,但可以在某些假设下通过修改使其变得图灵完备【1】。还有工作表明,使用“硬注意力”的Transformer通过将softmax替换为一热向量并使用无限精度,可以使Transformer变得图灵完备【2】。这与作者的研究形成了对比,他们的工作关注于使用软注意力和有限精度的更标准的(更一般的)Transformer设置。
2)Peng等人【3】表明,具有有限精度的Transformer块在表示组合函数和解决需要它的简单问题方面的能力从根本上受到限制。
3)注意力机制的衰减问题:在Transformer模型中,自注意力机制可能达到一种限制其学习能力的病理状态。这种衰减可能导致训练不稳定,甚至在训练后期也会显著降低模型的性能。此外,特定的标记可能会过分集中注意力,使得Transformer无法学习处理简单的语言任务。
4)过度压缩现象:是在图神经网络(GNNs)和基于注意力的Transformer模型中观察到的一个问题。它描述了在具有“瓶颈”的图形上传播信息时,信息可能会被“压缩”或丢失。这种信息的丢失通过节点间的通勤时间(即随机游走从一个节点到另一个节点再返回的预期步数)来衡量。对于高通勤时间的节点,其信息传播将受到更大的压缩。
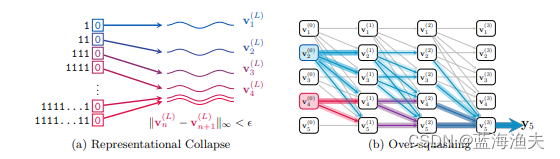
表现坍塌和过渡压缩的图示
3,失败案例
如之前段落所说,本文观察到的基于Transformer的大模型在计数和复制这样的简单任务中也会出错。以大模型Gimini为例
1)提示Gemini复制序列“1...10”的最后一个元素或序列“01...1”的第一个元素。两者的答案都是0,但我们逐渐增加了1的数量。我们观察到,当要求返回第一个元素而不是最后一个元素时,任务似乎要容易得多。令人惊讶的是,在序列长度仅为300个元素时,Gemini在尝试复制最后一个元素时已经开始错误地输出“1”。
2)考虑了四种不同的任务:(i)累加1 ¨ ¨ ¨ 1,(ii)计算由“1”组成的序列中“1”的数量,(iii)计算由“1”和“0”组成的序列中“1”的数量,其中“1”以70%的概率被采样,以及(iv)计算句子中特定单词出现的次数。
实验结果表明,随着序列长度的增加,性能迅速下降。例如,在任务(i)中,一旦序列大小达到或超过100,大型语言模型(LLM)很可能预测“100”的值。这一观察为这样的论点提供了激励性的证据:Transformer模型可能并不是真正地进行机械计数,而是执行一种粗略的子化(subitizing)类型。这解释了为什么像100这样的“常见”数字更有可能被LLM输出。
其他错误实验结果可以自己查看原论文,不在这里详述了。
4,表示坍塌
1)表示塌陷现象:作者指出,在Transformer模型中,尤其是当使用有限精度浮点数时,不同的输入序列在模型的最终层的最后一个标记上可能产生非常接近的表示。这意味着模型难以区分这些序列,导致在某些任务上出现错误。
2)理论分析:通过理论分析,作者证明了随着序列长度的增加,某些特定序列的表示会趋于一致,这种现象称为表示塌陷。这在数学上通过分析softmax分布的L1距离(或总变差)来证明。
3)低精度浮点数的影响:论文强调了现代大型语言模型(LLMs)常用的低精度浮点数格式(如bfloat16)可能加剧表示塌陷的问题,因为这些格式的表示能力有限。
4)解决方案:作者提出的一种解决方案是在序列中引入额外的标记或分隔符,以保持不同序列的表示之间的距离。
5,过渡压缩
1)过度压缩现象:作者指出,由于decoder-only Transformer的计算图结构,特别是其单向因果掩码,模型可能会在处理输入序列时丢失对特定标记的敏感性。
2)理论分析:论文量化了输入序列中每个标记对最终层最后一个标记表示的影响。分析表明,序列中较早的标记由于通过更多的路径影响最终表示,因此其信息更容易被“压缩”。
量化的方式是:(I)定义敏感度度量(II)作者计算了最终层最后一个标记 yn 相对于 v0i 的偏导数 。这个偏导数衡量了输入标记 v0i 对输出 yn 的影响程度。(III)作者最终导出了一个数学表达式来量化这种敏感度:
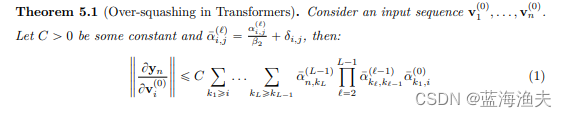
这里只简单介绍量化分析过程,有兴趣的自己去原文理解这个公式。
3)信息传播:作者研究了信息如何在Transformer模型中传播,特别是如何从输入序列的早期标记传播到最终用于预测下一个标记的表示。他们发现,由于注意力机制的拓扑结构,早期标记的信息更容易在模型中保留。
4)U形效应:论文解释了为什么大型语言模型(LLMs)在检索任务中,当所需检索的信息位于序列的开始或结束时,表现得更好。这种现象被称为U形效应,与过度压缩的理论分析相一致。
5)由于softmax层的归一化特性,模型难以在计数时考虑到序列的长度,这导致模型在执行计数任务时面临困难。
5)解决方案:可惜的是,作者没有提出针对性的解决方案,作者认为大概率要从改进模型结构入手
本文的价值在于对decoder only Transformer存在的固有缺陷的分析,虽然本文没有提出太多有价值的解决方案,但是我们在这些分析的基础之上可以进一步改进Transformer模型。
【1】Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers, 2019.
【2】Jorge Pérez, Pablo Barceló, and Javier Marinkovic. Attention is turing-complete. Journal of Machine Learning Research, 22(75):1–35, 2021.
【3】Binghui Peng, Srini Narayanan, and Christos Papadimitriou. On limitations of the transformer architecture, 2024.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











