







说明:BoyerMoore算法是一种能快速检测出在字符串中的与之匹配的算法,该算法广泛用于各种字符串检测。网上也有很多解释该算法的,进过我自己的研究、总结,可能会与网上的版本在代码和匹配算法上有点区别,但我觉得用自己的方法能更好的理解。(PS:着只是个人观点哈! 如果觉得没有什么差的,或说不懂的,大家每个人都不一样嘛,总之理解就好。)
过程:想要使用BoyerMoore算法,必须先理解两种字符串的匹配方法:坏字法和最好后缀法。这两种方法在不同的情况下效果也不太一样。
首先我们来通过实例来说明说明是坏字检测法和最好后缀法:
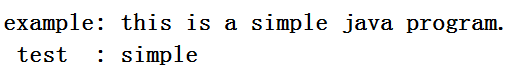
如图:需要检测的字符串是“this is a simple java program”,用来检测的字符串是“simple”。所谓的坏字就是从后往比较与test字符串中第一个没有匹配到的字符(至于为什么要从后往前,这样能减少比较的次数:字符串是往后移动的,如果后面的都已经匹配不到了,那前面的也就没有比较的必要了吧!!)。
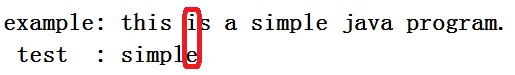
如图" i "就是坏字,匹配不到了,那么我们就开始移动,移动一个?还是能更多?移动一个显然不是我们想要的要增加效率显然要跳过尽可能多的位置。根据上面我说的,其实我们可以把test中的" i "移动至example的i下,这样我们就成功移动了4个位置,而且这绝对不会漏过什么。
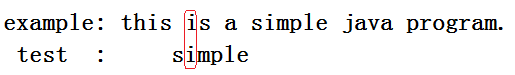
具体的移动位数为:坏字对应的在test中的位置-该位置前的在test中与该坏字匹配的位置(如果没有则将字符串整个移动到坏字之后)。
接下来介绍好后缀法:
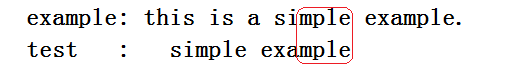
顾名思义好后缀法就是当有一个或多个example中的字符与test中的字符中对应,如图好后缀就是" mple ",那好了现在我们头脑风暴下最多能移动几个,移动的规则是什么?
显然最多的应该是把" simple "中的" mple "移动到" mple "下,这样能做到最大的移动位数。
那好,我们该怎么确定移动的规则,这里引入一个准备数组suff[i],该数组表示若以当前的以i作为最后的字符串与test字符串一样的个数,可能有点绕,就是在对比的时候有一个好后缀,接下来要移动,那么就要寻找一样的字符串,假设好后缀长度为4,如果suff[i]>4的话就可以认为以i结尾的字符串可以移动到最后。
| test | a | b | c | b | a | a | b |
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| suff[i] | 0 | 2 | 0 | 1 | 0 | 0 | 7 |
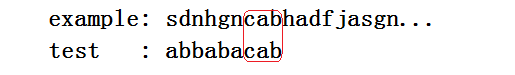

import java.util.Scanner;
public class BoyerMoore {
private char[] array;
private char[] test;
private int ltest, larray;
private int[] suff;
// 记录跳过的个数
private int flag;
public BoyerMoore(String s1, String s2) {
array = s1.toCharArray();
larray = array.length;
test = s2.toCharArray();
ltest = test.length;
flag = 0;
}
// a为坏字 k为坏字对应到test中到位置
public int checkTest1(char a, int k) {
for (int i = k - 1; i >= 0; i--) {
if (test[i] == a) {
return k - i; // 若检测到了坏字 移动的个数
}
}
return k + 1; // 没有检测到坏字 则移动整个数组
}
// 使用坏字法 跳过的字符个数
public int preBmBc() {
for (int i = ltest - 1; i >= 0; i--) { // 从后检测到第一个坏字
if (test[i] != array[flag + i]) {
return checkTest1(array[flag + i], i);
}
}
return 0; // 匹配到了字符串
}
// 好后缀用到的数组 用来表示以当前位置作为结尾的字符串最多能与该字符串匹配到的最多的字符
public int checkTest2(int i) {
int counter = 0;
for (int j = ltest - 1; i >= 0; i--, j--) {
if (test[i] != test[j])
break;
counter++;
}
return counter;
}
// 所生成的数组表示:若以当前的以i作为最后的字符串与test字符串一样的个数
public void setsuff() {
suff = new int[ltest];
for (int i = 0; i < ltest; i++) {
suff[i] = checkTest2(i);
}
}
// 用来检测有没有好后缀或者好前缀(好前缀是test里的前几个与test里好后缀的后几个匹配)
public int checkTest3(int length) {
for (int i = 0; i < ltest - 1; i++) { // 从后往前寻找 找到suff里大于好后缀长度的序号
if (suff[i] >= length)
return ltest - i - 1; // 返回有好后缀时到跳跃个数
}
for (int i = length - 2; i >= 0; i--) { // 没有好后缀
// 所以前length(0到length-1)不可能一样
// 故下标从length-2开始找好前缀
for (int j = i, k = ltest - 1; j >= 0; j--, k--) {
if (test[j] != test[k]) // 找出好前缀的长度
break;
return ltest - 1 - i; // 返回跳跃个数
}
}
return ltest;
}
public int preBmGs() {
setsuff();
int counter = 0;
// 记录最好后缀的个数
for (int i = ltest - 1, j = flag + ltest - 1; i >= 0; i--, j--) {
// <span style="white-space:pre"> </span>System.out.println(flag);
if (test[i] != array[j])
break;
counter++;
}
if (counter == 0) // 没有好后缀
return 1;
if (counter != ltest)
return checkTest3(counter);
return 0;
}
public int max(int a, int b) {
if (a > b)
return a;
return b;
}
// 使用递归查找 结束条件是 被检测的字符串中没有 或者是找到该字符串
public void find() {
// System.out.println(preBmBc()+","+preBmGs());
int jump = max(preBmBc(), preBmGs());
if (flag + ltest + jump > larray) {
System.out.println("字符串中没有你想找的字符串!!!");
return;
}
// System.out.println(flag);
if (jump == 0) {
System.out.println("找到你想要的字符串了!!" + "\n" + "从第" + (flag+1) + "个到"
+ (flag + ltest) + "个。");
flag += ltest;
return;
}
flag += jump;
find();
}
public static void main(String[] args) {
// 用这个方法输入内容 空格 tab 会被认为是输入结束 自己改进下
Scanner sc = new Scanner(System.in);
System.out.println("--- 输入被检测的字符串 ---");
String s1 = sc.next();
System.out.println("---输入你想检测的字符串---");
String s2 = sc.next();
BoyerMoore b = new BoyerMoore(s1, s2);
b.find();
}
} 最后大家可能看到我和网上提供的方法不太一样,我解释下:首先我在处理坏字时没有用到数组,我感觉对于test个数比较少的情况下可以不用数组,个人觉得这样增加了复杂度,并且增加了程序运行时所占用的空间,(网上的方法大多数将所有的字符utf-8码(可以想象汉字的个数么)作为数组下标移动位数作为数组内容,因此要分配很大的空间存储数据,并且查找起来也要话不少时间。)所以我采用了我自己的想法:直接在test中寻找移动位数。并且网上提供的方法,对于坏字的检测不是很准确(大神们勿喷哈。。。。),这是因为存储方式导致的,如果在test中出现了相同的字符,返回值很有可能是负值。可能有的人会对我说的不太懂,举个例子吧:
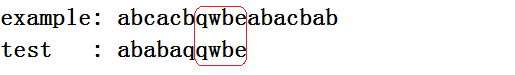















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









