







第一步:Spark集群需要的软件;
在1、2讲的从零起步构建好的Hadoop集群的基础上构建Spark集群,我们这里采用2014年5月30日发布的Spark 1.0.0版本,也就是Spark的最新版本,要想基于Spark 1.0.0构建Spark集群,需要的软件如下:
1.Spark 1.0.0,笔者这里使用的是spark-1.0.0-bin-hadoop1.tgz, 具体的下载地址是http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
如下图所示:
笔者是保存在了Master节点如下图所示的位置:
2.下载和Spark 1.0.0对应的Scala版本,官方要求的是Scala必须为Scala 2.10.x:
笔者下载的是“Scala 2.10.4”,具体官方下载地址为http://www.scala-lang.org/download/2.10.4.html 下载后在Master节点上保存为:
第二步:安装每个软件
安装Scala
- 打开终端,建立新目录“/usr/lib/scala”,如下图所示:
2.解压Scala文件,如下图所示:
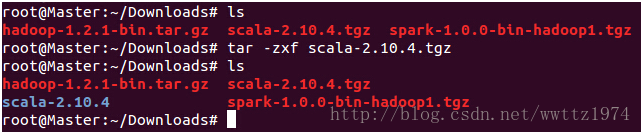
把解压好的Scala移到刚刚创建的“/usr/lib/scala”中,如下图所示

3.修改环境变量:

进入如下图所示的配置文件中:
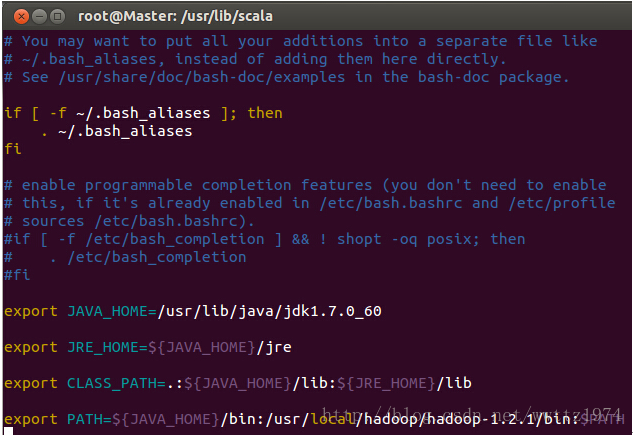
按下“i”进入INSERT模式,把Scala的环境编写信息加入其中,如下图所示:
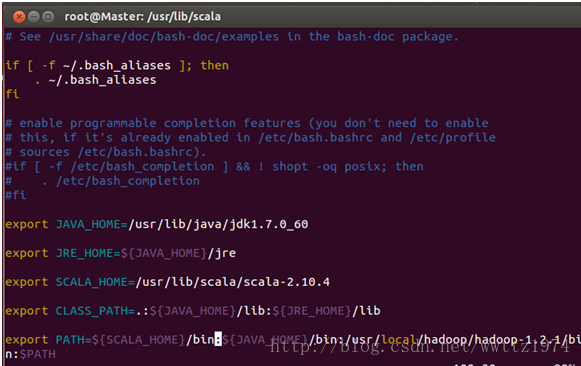
从配置文件中可以看出,我们设置了“SCALA_HOME”并把Scala的bin目录设置到了PATH中。
按下“esc“键回到正常模式,保存并退出配置文件:
执行以下命令是配置文件的修改生效:

4.在终端中显示刚刚安装的Scala版本,如下图所示

发现版本是”2.10.4”,这正是我们期望的。
当我们输入“scala”这个命令的的时候,可以直接进入Scala的命令行交互界面:

此时我们输入“9*9”这个表达式:
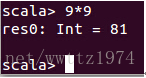
此时我们发现Scala正确的帮我们计算出了结果 。
此时我们完成了Master上Scala的安装;
由于我们的 Spark要运行在Master、Slave1、Slave2三台机器上,此时我们需要在Slave1和Slave2上安装同样的Scala,使用scp命令把Scala安装目录和“~/.bashrc”都复制到Slave1和Slave2相同的目录之之下,当然,你也可以按照Master节点的方式手动在Slave1和Slave2上安装。
在Slave1上Scala安装好后的测试效果如下:
在Slave2上Scala安装好后的测试效果如下:
至此,我们在Master、Slave1、Slave2这三台机器上成功部署Scala。















 5187
5187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









