







目录
Numpy
Numpy一个开源的python科学计算库,使用Numpy可以方便的使用数组、矩阵进行计算包含线性代数、傅里叶变换、随机数生成等大量函数。
-
为什么使用Numpy
代码更简洁: Numpy直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而python需要用for循环从底层实现;
性能更高效: Numpy的数组存储效率和输入输出计算性能,比Python使用List或者嵌套List好很多;
-
入门案例
将a和b两数组中元素相加
使用原生python实现
import numpy as np
def python_sum(n):
a=[i**2 for i in range(n)]
b=[i**3 for i in range(n)]
ab_sum=[]
for i in range(n):
ab_sum.append(a[i]+b[i])
return ab_sum
print(python_sum(10))使用numpy实现
import numpy as np
def python_sum(n):
a=np.arange(n)**2
b=np.arange(n)**3
return a+b
print(python_sum(10))-
ndarray对象
Numpy定义了一个n维数组对象,简称ndarray对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。ndarray对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
-
Numpy创建数组
使用numpy.array。其中array有一下几种参数可以选择。

 object可以是数组对象,迭代对象和生成器
object可以是数组对象,迭代对象和生成器
np里面使用copy=True两者的地址是不同的
使用numpy.arange。其中arange有一下几种参数可以选择。


使用numpy.linspace()。 其中linspace有一下几种参数可以选择。


使用numpy.logspace()。 其中linspace有一下几种参数可以选择。


使用numpy.zeros()和np.ones()。其中这两个参数有一下几种参数可以选择

-
Numpy数组属性

此外,还有reshape:返回调整维度后的副本,而不改变原ndarray。(如果之前的数组数量不够分则会报错,比如以下二十个元素分不成四行六列)
 如果硬要分,则使用resize。如果新数组大于原始数组,则新数组将填充a的重复副本。(如果直接使用a.resize则是直接用0填充)
如果硬要分,则使用resize。如果新数组大于原始数组,则新数组将填充a的重复副本。(如果直接使用a.resize则是直接用0填充)

astype:numpy数据类型转换,调用astype返回数据类型修改后的数据,但是源数据的类型不会变。
-
切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与Python 中list的切片操作一样。
注意:区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改)。这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copv())。
冒号:的解释∶如果只放置一个参数,如[2],将返回与该索引相对应的单个元素。·如果为[2:],表示从该索引开始以后的所有项都将被提取。·如果使用了两个参数,如[2:7],那么则提取两个索引(不包括停止索引)之间的项。·如果使用了两个参数,如[:7],则第一个开始到第七个结束。
省略号的解释:就是包含全部
注意:[.....,2]和[.....][2]是不同的,前者是同时取,后者是先再的关系
- Numpy高级索引方式
整数数组索引:逗号前面是行的索引,后边是列的索引。
a=np.array([[1,2],[3,4],[5,6]])
y=a[[0,1,2],[0,1,0]]
#获取a中(0,0)、(1,1)、(2,0)
print(y)布尔数组索引:当输出的结果需要经过布尔运算(如比较运算)时,此时会使用到另一种高级索引方式,即布尔数组索引。
a=np.array([[1,2],[3,4],[5,6]])
y=a[a>3]
#输出大于6的所有元素
print(y)查询后返回的是一维数组。也可以直接在行号或列号上直接写true或者false表示选择该行或该列或不选择。(两个一维数组中true的个数要相等)当访问numpy多维数组时,用于索引的数组需要具有相同的形状,否者会报错。如果为了实现不同维度的选择,可以分两步对数组进行选择。以下就会出现错误。
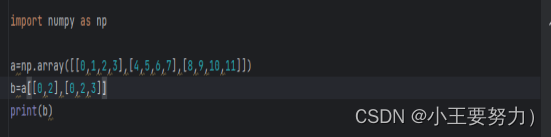
如果要选择第一行和最后一行的第一三四列可以采取如下的方法。
a=np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11]])
b=a[[0,-1],:]
print(b)
c=b[:,[0,2,3]]
print(c)-
广播机制
广播(Broadcast)是numpy对不同形状(shape)的数组进行数值计算的方式,对数组的算术运算通常在相应的元素上进行。如果两个数组a和b形状相同,即满足a.shape == b.shape,那么ab的结果就是a与b数组对应位相乘。这要求维数相同,且各维度的长度相同。
如果维度不同,NumPy设计了一种广播机制,这种机制的核心是对形状较小的数组,在横向或纵向上进行一定次数的重复,使其与形状较大的数组拥有相同的维度。
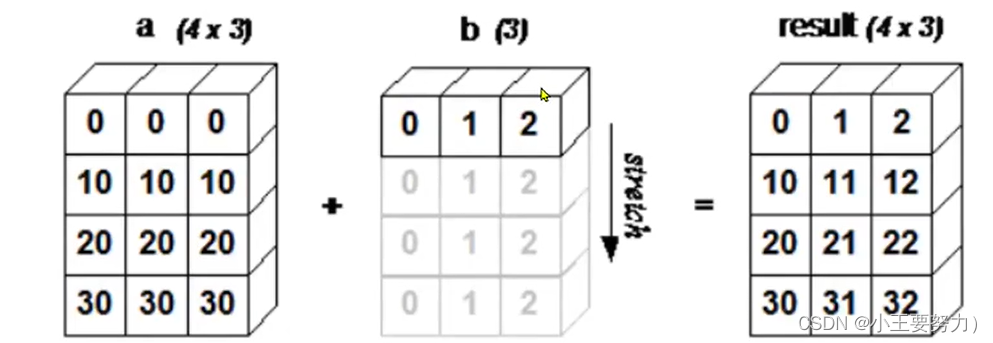
广播的规则简单来理解就是:将两个数组的维度大小右对齐,然后比较对应维度上的数值,如果数值相等或其中有一个为1或者为空,则能进行广播运算,输出的维度大小为取数值大的数值。否则不能进行数组运算。
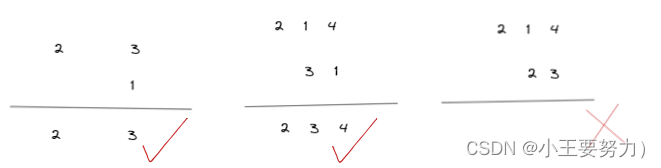
-
统计函数
np.arange(20).mean()求平均值 mean中的参数axis,如果axis=0则取每一列的平均数,如果axis=1,则取每一行的平均数。
np.median(np.array([1,3,5,6,8]))求中位数。
np.std(np.array([1,3,5,6,8]))求标准差。
np.array([1,3,5,6,8]).var()求方差。
np.array([1,3,5,6,8]).min()求最小值。
np.array([1,3,5,6,8]).max()求最大值。
np.array([1,3,5,6,8]).sum()求和。
np.average(a,axis=None,weights=None,returned=False),求加权平均。
from array import array
import numpy as np
xiaowang=np.array([90,80,95])
xiaolin=np.array([95,90,80])
weights=np.array([0.2,0.3,0.5])
print(np.average(xiaowang,weights=weights))
print(np.average(xiaolin,weights=weights))
-
数据类型
可以用来指定,np中元素的类型。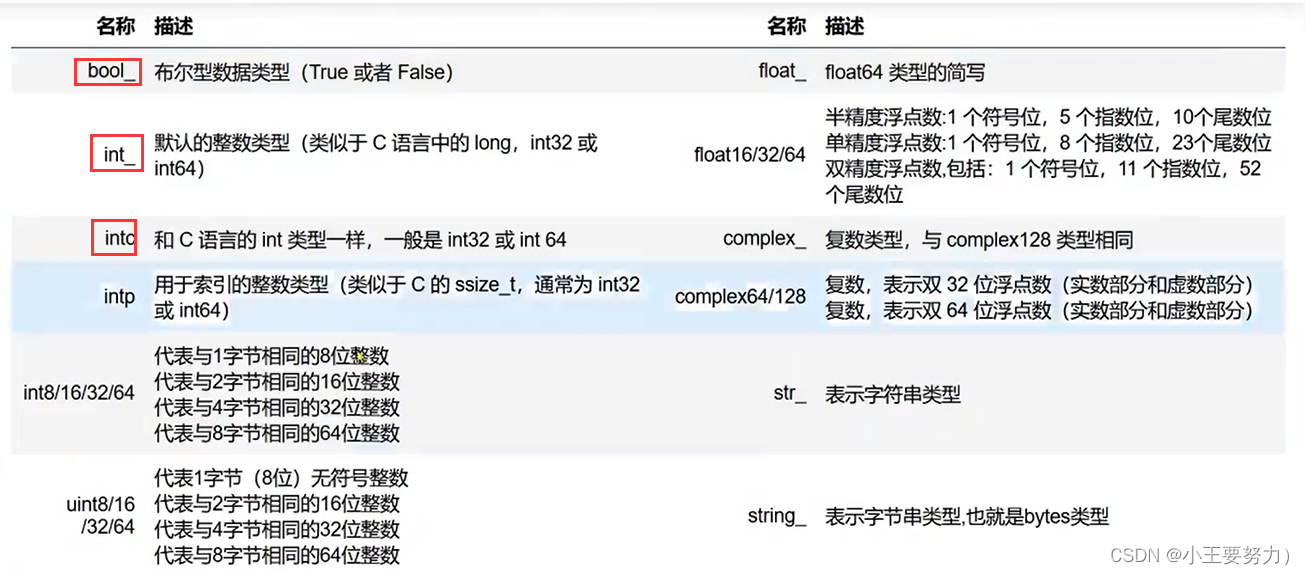
最重要的是自定义数据类型, 也就是让np存储对象。

import numpy as np
use_info=np.dtype([('name',np.str_,10),('age','i1')])
users=np.array([('xiaowang',19),('xiaolin',22)],dtype=use_info)
print(users)
print(users['name'])numpy中数据类型会选择数组中最大长度的,如果后续操作超出了这个最大长度会被省略(数字是循环)。
-
操作文件loadtxt

如果是注释的话,会自动跳过,但是如果规定了跳过几行,那么注释也会跳过但是达不到预期效果。converters前面是列,后面是自己定义的函数。
-
随机函数
NumPy中也有自己的随机函数,包含在random模块中。它能产生特定分布的随机数,如正态分布等。接下来介绍一些常用的随机数。
 np.random.rand(维度) 根据所给定的维度生成[0,1)之间的数据,返回值为指定维度的array
np.random.rand(维度) 根据所给定的维度生成[0,1)之间的数据,返回值为指定维度的array
np.random.randn(维度)randn函数返回一个或一组样本,具有标准正态分布。返回值为指定维度的array
np.random.randint返回随机整数,范围区间为[low,high),low表示最小值,high表示最大值,size是维度,dtype是数据类型。
np.random.sample返回半开区间内的随机浮点数[0.0,1.0]。
随机种子np.random.seed() 使用相同的seed()值,则每次生成的随机数都是相同的。但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。
np.random.seed(2)
a=np.random.rand(5)
np.random.seed(2)
b=np.random.rand(5)
print(a)
print(b)这样子调用就是产生相同的随机数。
np.random.normal返回一个由size指定形状的数组,数组中的值服从u=loc,o =scale 的正态分布。- size : int型或者int型的元组,指定了数组的形状。如果不提供size,且loc和scale为标量(不是类数组对象〉,则返回一个服从该分布的随机数。
-
数组的其他函数
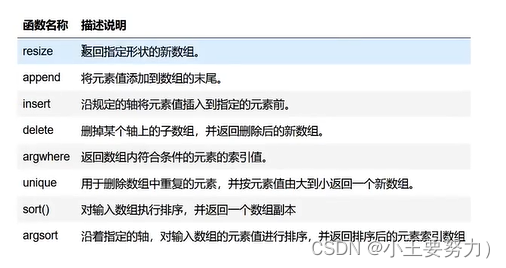
np.append添加元素也有axis参数,效果如上所说。如果不提供则展开为
a=np.array([[1,2,3],[4,5,6]])
print(a)
b=np.append(a,[[7,8,9],[10,11,12]],axis=1)
print(b)insert表示沿指定的轴,在给定索引值的前一个位置插入相应的值,如果没有提供轴,则输入数组被展开为一维数组。

np.delete()该方法表示从输入数组中删除指定的子数组,并返回一个新数组。它与insert()函数相似,若不提供 axis,参数,则输入数组被展开为一维数组。numpy.delete(arr,obj,axis)参数说明:

np.argwhere()该函数返回数组中非О元素的索引,若是多维数组则返回行、列索引组成的索引坐标。
np.unique()用于删除数组中重复的元素。


np.sort()对输入数组执行排序,并返回一个数组副本。
np.argsort()沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组.
文章是根据b站up主电子喵不是垫子喵,大家也可以去看看视频~
















 4625
4625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









