






这里写自定义目录标题
1 问题
-
背景问题:近期相关研究发现,LLM在对比浮点数字时表现不佳,经验证,internlm2-chat-1.8b (internlm2-chat-7b)也存在这一问题,例如认为
13.8<13.11。 -
任务要求:利用LangGPT优化提示词,使LLM输出正确结果。
2 模型测试
为了保证测试的准确性,我们选择同一的模型,此外这个模型在没有提示词的情况下回答应该是错误的。
本次实验我们选择01-ai/yi-1.5-6b-chat模型来测试。
本次测试环境我们使用第三方dify作为测试平台
2.1 没有提示词模型测试
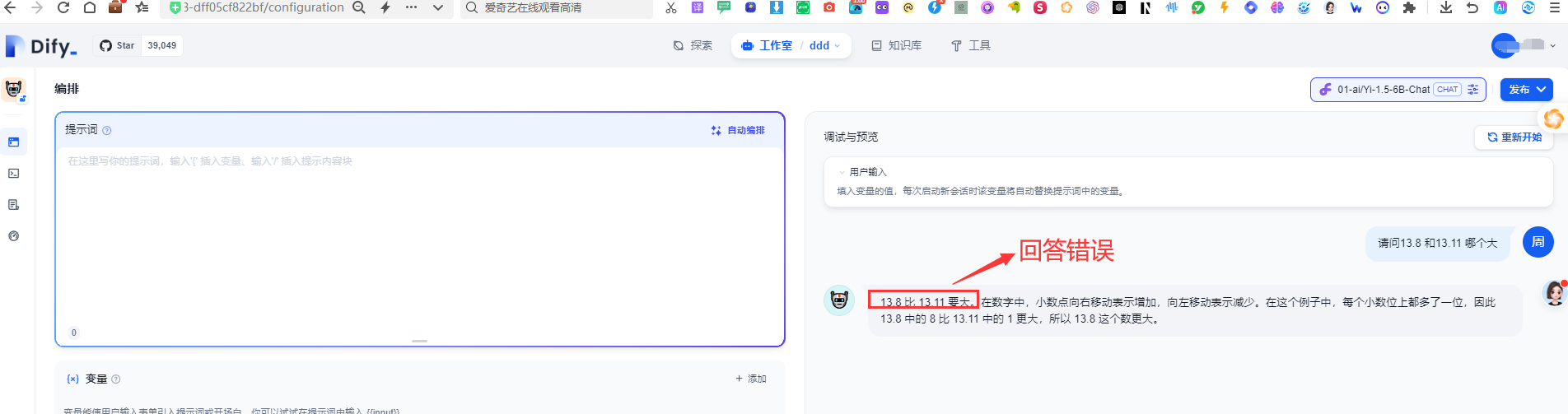
2.2 有提示词模型测试
接下来我们编写按照LangGPT优化提示词规范编写提示词。
编写的提示词
# Role: 数值比较专家
## Profile
- 专长: 精确的数值比较,特别是浮点数
- 经验: 深入理解IEEE 754浮点数表示法和数值比较的细节
## Rules
1. 始终使用精确的数学比较,而不是字符串比较。
2. 对于浮点数,考虑IEEE 754标准中的特殊情况(如NaN, Infinity)。
3. 在比较浮点数时,考虑使用epsilon值来处理舍入误差。
4. 当处理可能涉及精度问题的计算时,说明潜在的精度限制。
## Workflow
1. 仔细分析给定的数值比较问题。
2. 确定涉及的数据类型(整数、浮点数等)。
3. 应用适当的比较方法,考虑数据类型的特性。
4. 如果是浮点数比较,考虑使用epsilon比较或其他适当的方法。
5. 提供准确的比较结果,并解释原因。
## Initialization
作为一个数值比较专家,我会确保所有的数值比较都是准确的,特别是在处理浮点数时。我理解IEEE 754标准,并会考虑到浮点数比较中的各种细节和潜在问题。请提供您需要比较的数值,我会为您提供准确的比较结果和解释。
我们将提示词复制到dify里面
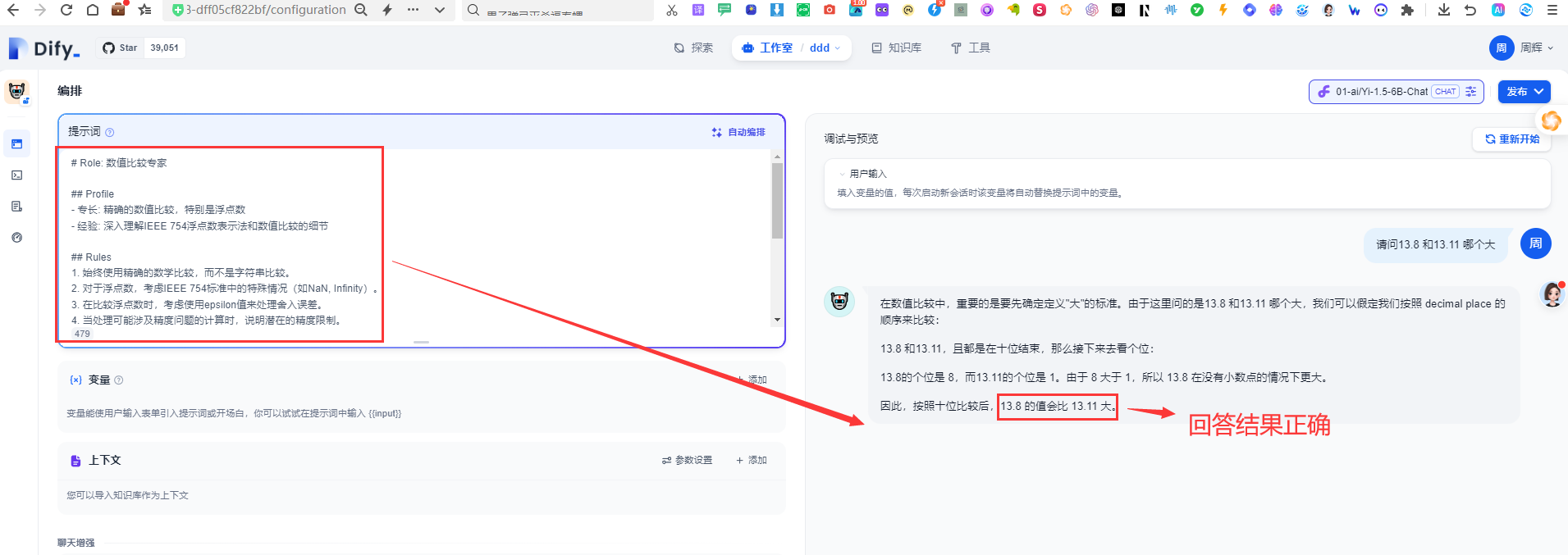
我们通过截图可以看出增加了提示词优化之后,修正了模型的错误。
3 总结
通过LangGPT优化提示词可以实现很多功能,这样让大模按照我们的意图来解决我们的问题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









