






- 部署工具:cephadm
- 操作系统:CentOS 8
- Ceph版本:Octopus
- 操作用户:root
部署前,请注意:根据目前(2020年8月)Ceph官方文档的介绍,cephadm的对各服务的支持情况如下:
- 完全支持:MON、MGR、OSD、CephFS、rbd-mirror
- 支持但文档不全:RGW、dmcrypt OSDs
- 开发中:NFS、iSCSI
准备
除非特别说明,本小节的操作在所有节点进行。
部署环境:
| 主机 | IP | 配置 | 磁盘(除系统盘) | 服务 |
|---|---|---|---|---|
| ceph-mon1(虚拟机) | 192.168.7.11 | 4C/8G | MON、prom+grafana | |
| ceph-mon2(虚拟机) | 192.168.7.12 | 4C/8G | MON、MGR | |
| ceph-mon3(虚拟机) | 192.168.7.13 | 4C/8G | MON、MGR | |
| ceph-osd1(物理机) | 192.168.7.14 | 40C/64G | 1.6T SSD/4T SAS 4 | OSD、MDS、NFS、RGW |
| ceph-osd2(物理机) | 192.168.7.15 | 40C/64G | 1.6T SSD/4T SAS 4 | OSD、MDS、NFS、RGW |
确定一下主机名是否正确,尤其是从虚拟机复制过来的节点:
hostnamectl set-hostname ceph-mon1
cephadm的部署方式是基于容器进行管理的,可以安装docker或podman。
dnf install -y podman
为podman配置国内镜像源:
mv /etc/containers/registries.conf /etc/containers/registries.conf.bakcat <<EOF > /etc/containers/registries.confunqualified-search-registries = ["docker.io"][[registry]]prefix = "docker.io"location = "anwk44qv.mirror.aliyuncs.com"EOF
并配置阿里云的源。
yum install -y https://mirrors.aliyun.com/epel/epel-release-latest-8.noarch.rpmsed -i 's|^#baseurl=https://download.fedoraproject.org/pub|baseurl=https://mirrors.aliyun.com|' /etc/yum.repos.d/epel*sed -i 's|^metalink|#metalink|' /etc/yum.repos.d/epel*
dnf install -y chronymv /etc/chrony.conf /etc/chrony.conf.bakcat > /etc/chrony.conf <<EOF server ntp.aliyun.com iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey logchange 0.5 logdir /var/log/chrony EOFsystemctl enable chronydsystemctl restart chronyd
修改/etc/hosts文件,添加所有节点的IP(如果用DNS也可以)。
192.168.7.11 ceph-mon1192.168.7.12 ceph-mon2192.168.7.13 ceph-mon3192.168.7.14 ceph-osd1192.168.7.15 ceph-osd2
setenforce 0
要使 SELinux 配置永久生效(如果它的确是问题根源),需修改其配置文件/etc/selinux/config。
sed -i '/^SELINUX=/c SELINUX=disabled' /etc/selinux/config
cephadm以及ceph命令基于python3运行。
dnf install -y python3
安装cephadm
以下操作在ceph-mon1节点上进行。
使用curl下载最新的cephadm脚本:
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadmchmod +x cephadm
其实这个脚本就可以用来部署了,如果要安装的话:
./cephadm add-repo --release octopus./cephadm install
部署一个小集群
除非特别说明,本小节的操作在cephadm所在节点进行。
cephadm的部署策略是先在一个节点上部署一个Ceph cluster,然后把其他节点加进来,再部署各种所需的服务。
首先部署的这个节点是一个MON,需要提供IP地址。
mkdir -p /etc/cephcephadm bootstrap --mon-ip 192.168.7.11
这个命令会:
- 创建一个有MON和MGR的新cluster。
- 为Ceph cluster生成一个SSH key,并添加到
/root/.ssh/authorized_keys。 - 生成一个最小化的
/etc/ceph/ceph.conf配置文件。 - 为用户
client.admin生成/etc/ceph/ceph.client.admin.keyring。 - 生成公钥
/etc/ceph/ceph.pub,这是cephadm(ceph orch命令)用来连接其他节点的公钥。
上面这几条是官方文档里介绍的,其实用podman ps查看一下,发现已经启动了几个容器:
- mon(ceph/ceph:v15)
- mgr(ceph/ceph:v15)
- crash(ceph/ceph:v15),这是干嘛的?
- prometheus和node-exporter,用于收集监控指标数据
- alertmanager,以前没用过,应该是告警用的
- grafana,可以利用prometheus收集到的数据进行监控的可视化
命令的输出如下:
......INFO:cephadm:Ceph Dashboard is now available at:URL: https://ceph-mon1:8443/User: adminPassword: 91qoulprnvINFO:cephadm:You can access the Ceph CLI with:sudo /usr/sbin/cephadm shell --fsid 1be68a48-de06-11ea-ae5e-005056b10c97 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyringINFO:cephadm:Please consider enabling telemetry to help improve Ceph:ceph telemetry onFor more information see:https://docs.ceph.com/docs/master/mgr/telemetry/INFO:cephadm:Bootstrap complete.
ceph cli
由于有了这些容器,其实就不需要本机安装任何Ceph的包了。
cephadm shell能够连接容器并利用其中已安装的ceph包和命令行工具。所以执行
cephadm shell
就可以进入容器内部,然后执行ceph、rbd、rados等命令了。也可以添加别名:
alias ceph='cephadm shell -- ceph'# 或利用上面的输出中给出的完整的命令alias ceph='/usr/sbin/cephadm shell --fsid 1be68a48-de06-11ea-ae5e-005056b10c97 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring -- ceph'
前面的./cephadm add-repo --release octopus命令创建了/etc/yum.repos.d/ceph.repo文件,处理一下使用阿里云的源:
sed -i 's#download.ceph.com#mirrors.aliyun.com/ceph#' /etc/yum.repos.d/ceph.repodnf makecache
然后就可以安装ceph命令行工具了:
dnf install -y ceph-commonceph -vceph -s
添加节点到集群
-
将cluster的SSD公钥配置到新节点的
authorized_keys文件(即SSH免密):ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-mon2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-mon3
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-osd1
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-osd2 -
添加节点到cluster:
ceph orch host add ceph-mon2
ceph orch host add ceph-mon3
ceph orch host add ceph-osd1
ceph orch host add ceph-osd2
通常Ceph需要部署3或5个MON节点,如果后来添加的节点与bootstrap的节点是在一个子网里,那么Ceph会自动将添加的节点部署上MON服务,直至达到5个。如要调整:
# ceph orch apply mon *<number-of-monitors>*ceph orch apply mon 3
(方法一)如果要指定MON部署到哪几个具体的节点:
# ceph orch apply mon *<host1,host2,host3,...>*ceph orch apply mon ceph-mon1,ceph-mon2,ceph-mon3
(方法二)此外,还可以用标签来进行指定:
# ceph orch host label add *<hostname>* monceph orch host label add ceph-mon1 monceph orch host label add ceph-mon2 monceph orch host label add ceph-mon3 mon# 然后指定ceph orch apply mon label:mon
可以查看一下标签情况:
❯ ceph orch host lsHOST ADDR LABELS STATUSceph-mon1 ceph-mon1 monceph-mon2 ceph-mon2 monceph-mon3 ceph-mon3 monceph-osd1 ceph-osd1ceph-osd2 ceph-osd2
(方法三)还支持用YAML文件来指定:
service_type: monplacement:hosts:- ceph-mon1- ceph-mon2- ceph-mon3
本小节及以后的操作可以在任何安装有
ceph-common包并且能够连接Ceph集群(有/etc/ceph/ceph.conf和具有管理权限的key文件)的节点上运行。
添加节点后,Ceph会自动启动MGR节点:
❯ ceph orch ls --service_type mgrNAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE IDmgr 2/2 10m ago 74m count:2 docker.io/ceph/ceph:v15 54fa7e66fb03
可以看到,它启动了两个,其中一个是bootstrap的时候指定的ceph-mon1节点。
使用ceph orch ps --daemon_type mgr可以看到,在那两台节点上运行有mgr的容器。
我这部署的时候占用了ceph-osd1节点,仿照MON的标签方式:
ceph orch host label add ceph-mon2 mgrceph orch host label add ceph-mon3 mgrceph orch apply mgr label:mgr
在OSD节点安装smartmontools(7),默认安装的6版本无法满足需求,会在Dashboard报warning:
Smartctl has received an unknown argument (error code -22). You may be using an incompatible version of smartmontools. Version >= 7.0 of smartmontools is required to successfully retrieve data.
# 在OSD节点上,先下载smartmontool的rpmwget http://fr2.rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/smartmontools-7.1-1.el8.x86_64.rpm# 然后复制到各个OSD容器中(先用podman ps查看一下容器名称或ID)podman cp smartmontools-7.1-1.el8.x86_64.rpm ceph-e09db8ae-f95c-11ea-931c-90e2ba8a2734-osd.5:/tmp# 然后安装podman exec -it ceph-e09db8ae-f95c-11ea-931c-90e2ba8a2734-osd.5 rpm -Uvh /tmp/smartmontools-7.1-1.el8.x86_64.rpmpodman exec -it ceph-e09db8ae-f95c-11ea-931c-90e2ba8a2734-osd.5 rm -f /tmp/smartmontools-7.1-1.el8.x86_64.rpm# 查看安装结果podman exec -it ceph-e09db8ae-f95c-11ea-931c-90e2ba8a2734-osd.5 smartctl --version
当然,也可以批量操作:
wget http://fr2.rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/smartmontools-7.1-1.el8.x86_64.rpmfor pod in $(podman ps | grep osd. | awk '{print $1}'); dopodman cp smartmontools-7.1-1.el8.x86_64.rpm $pod:/tmppodman exec -it $pod rpm -Uvh /tmp/smartmontools-7.1-1.el8.x86_64.rpmpodman exec -it $pod rm -f /tmp/smartmontools-7.1-1.el8.x86_64.rpmpodman exec -it $pod smartctl --version | head -n 1done
查看设备:
ceph orch device ls

满足以下条件的设备时AVAIL=True的:
- 没有分区
- 没有LVM配置
- 没有被挂载
- 没有文件系统
- 没有Ceph BlueStore OSD
- 大于5GB
否则无法置备对应的设备。
两种添加办法:
-
自动添加所有的可用设备
ceph orch apply osd —all-available-devices
-
手动添加设备(这里先只添加2个ssd和2个hdd)
ceph orch daemon add osd :
ceph orch daemon add osd ceph-osd1:/dev/nvme0n1
ceph orch daemon add osd ceph-osd2:/dev/nvme0n1
ceph orch daemon add osd ceph-osd1:/dev/sdb
ceph orch daemon add osd ceph-osd2:/dev/sdb
此时,在ceph-osd1和ceph-osd2两个节点可以看到为每一个OSD启动了一个容器。
虽然标签对OSD不起作用,不过还是打上,方便查看:
ceph orch host label add ceph-osd1 osdceph orch host label add ceph-osd2 osd
配置存储池
为了分别测试SSD和HDD的性能,配置两个存储池,存储池ssd落在两块SSD上,而存储池hdd落在HDD上。
通过CRUSH rule来实现这一点,执行ceph osd tree查看现有的osd:
❯ ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 10.18738 root default-3 5.09369 host ceph-osd12 hdd 3.63820 osd.2 up 1.00000 1.000000 ssd 1.45549 osd.0 up 1.00000 1.00000-5 5.09369 host ceph-osd23 hdd 3.63820 osd.3 up 1.00000 1.000001 ssd 1.45549 osd.1 up 1.00000 1.00000
可以看到CLASS一列已经自动对添加的设备进行了ssd和hdd的分类。
下面创建两个CRUSH rule,根据CLASS进行区分:
# 先查看现有的rule❯ ceph osd crush rule lsreplicated_rule# 创建两个replicated rule# 格式:ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>❯ ceph osd crush rule create-replicated on-ssd default host ssd❯ ceph osd crush rule create-replicated on-hdd default host hdd
故障域设置为host,由于我这只有两台host,所以replica_size只能为2。
ceph config set global osd_pool_default_size 2
创建两个存储池,并通过rule进行约束:
❯ ceph osd pool create bench.ssd 64 64 on-ssdpool 'bench.ssd' created❯ ceph osd pool create bench.hdd 128 128 on-hddpool 'bench.hdd' created❯ ceph osd pool ls detailpool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 ...pool 2 'bench.ssd' replicated size 2 min_size 1 crush_rule 1 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 46 flags hashpspool stripe_width 0pool 3 'bench.hdd' replicated size 2 min_size 1 crush_rule 2 object_hash rjenkins pg_num 125 pgp_num 120 pg_num_target 32 pgp_num_target 32 pg_num_pending 124 autoscale_mode on last_change 67 lfor 0/67/67 flags hashpspool stripe_width 0
可以看到,新增加的两个pool都是size 2,不过bench.hdd的pg数量有些奇怪,ceph -s看一下:
❯ ceph -scluster:id: 1be68a48-de06-11ea-ae5e-005056b10c97health: HEALTH_OKservices:mon: 3 daemons, quorum ceph-mon2,ceph-mon3,ceph-mon1 (age 35m)mgr: ceph-mon2.puzrvy(active, since 2d), standbys: ceph-mon3.gvdtdwmds: 2 up:standbyosd: 4 osds: 4 up (since 2d), 4 in (since 2d); 1 remapped pgsdata:pools: 3 pools, 146 pgsobjects: 4 objects, 0 Busage: 4.1 GiB used, 10 TiB / 10 TiB availpgs: 0.685% pgs not active145 active+clean1 clean+premerge+peeredprogress:PG autoscaler decreasing pool 3 PGs from 128 to 32 (4m)[=============...............] (remaining: 4m)
发现健康状况是HEALTH_OK的,不过下方的progress确实正在进行PG数量的调整,原来在Ceph nautilus版本引入了PG的自动调整功能,难道不用指定具体的pg_num和pgp_num了吗,试一下:
❯ ceph osd pool create testpg on-hddpool 'testpg' created❯ ceph osd pool ls detail...pool 4 'testpg' replicated size 2 min_size 1 crush_rule 2 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 458 flags hashpspool stripe_width 0
不错,看来以后不用找公式算PG个数了。删除测试pool:
❯ ceph config set mon mon_allow_pool_delete true❯ ceph osd pool rm testpg testpg --yes-i-really-really-mean-itpool 'testpg' removed
RGW
部署RGW daemon
首先,创建RGW的realm、zonegroup和zone:
# radosgw-admin realm create --rgw-realm=<realm-name> --default❯ radosgw-admin realm create --rgw-realm=testenv --default# radosgw-admin zonegroup create --rgw-zonegroup=<zonegroup-name> --master --default❯ radosgw-admin zonegroup create --rgw-zonegroup=mr --master --default# radosgw-admin zone create --rgw-zonegroup=<zonegroup-name> --rgw-zone=<zone-name> --master --default❯ radosgw-admin zone create --rgw-zonegroup=mr --rgw-zone=room1 --master --default
部署RGW的命令如下(实例命令部署在了两个OSD的机器上):
# ceph orch apply rgw *<realm-name>* *<zone-name>* --placement="*<num-daemons>* [*<host1>* ...]"❯ ceph orch apply rgw testenv mr-1 --placement="2 ceph-osd1 ceph-osd2"
由于RGW拥有自己的一套账号体系,所以为了让Dashboard能够查看RGW相关信息,需要在RGW中创建一个dashboard用的账号,以便能够查询相关信息
首先,创建用户:
❯ radosgw-admin user create --uid=dashboard --display-name=dashboard --system..."keys": [{"user": "dashboard","access_key": "EC25NETO4CXIISOB32WY","secret_key": "XrZQcFv7c56kidMtnwFGBSDApseQLwA1VPYolCZA"}],...
然后,将access_key和secret_key配置到dashboard:
❯ ceph dashboard set-rgw-api-access-key "EC25NETO4CXIISOB32WY"❯ ceph dashboard set-rgw-api-secret-key "XrZQcFv7c56kidMtnwFGBSDApseQLwA1VPYolCZA"
除了具体放对象数据的存储池(通常是以.data结尾的),将其他的存储池迁至SSD上,如:
ceph osd pool set .rgw.root crush_rule on-ssd...
块存储
首先,为bench.hdd两个存储池开启rbd的application。
❯ ceph osd pool application enable bench.hdd rbdenabled application 'rbd' on pool 'bench.hdd'
然后创建RBD镜像:
❯ rbd create bench.hdd/disk1 --size 102400
将RBD镜像映射到块设备:
❯ rbd map bench.hdd/disk1/dev/rbd0
然后用XFS格式化,并挂载:
❯ mkfs.xfs /dev/rbd0❯ mount /dev/rbd0 /mnt/rbd
CephFS
同样用标签的方式:
ceph orch host label add ceph-osd1 mdsceph orch host label add ceph-osd2 mds# ceph orch apply mds <cephfs_name> label:mdsceph orch apply mds cephfs label:mds
有两种方式:
1.利用ceph的编排功能自动创建(名称为cephfs):
❯ ceph fs volume create cephfs
关于CephFS,可以从下图了解其基本原理:
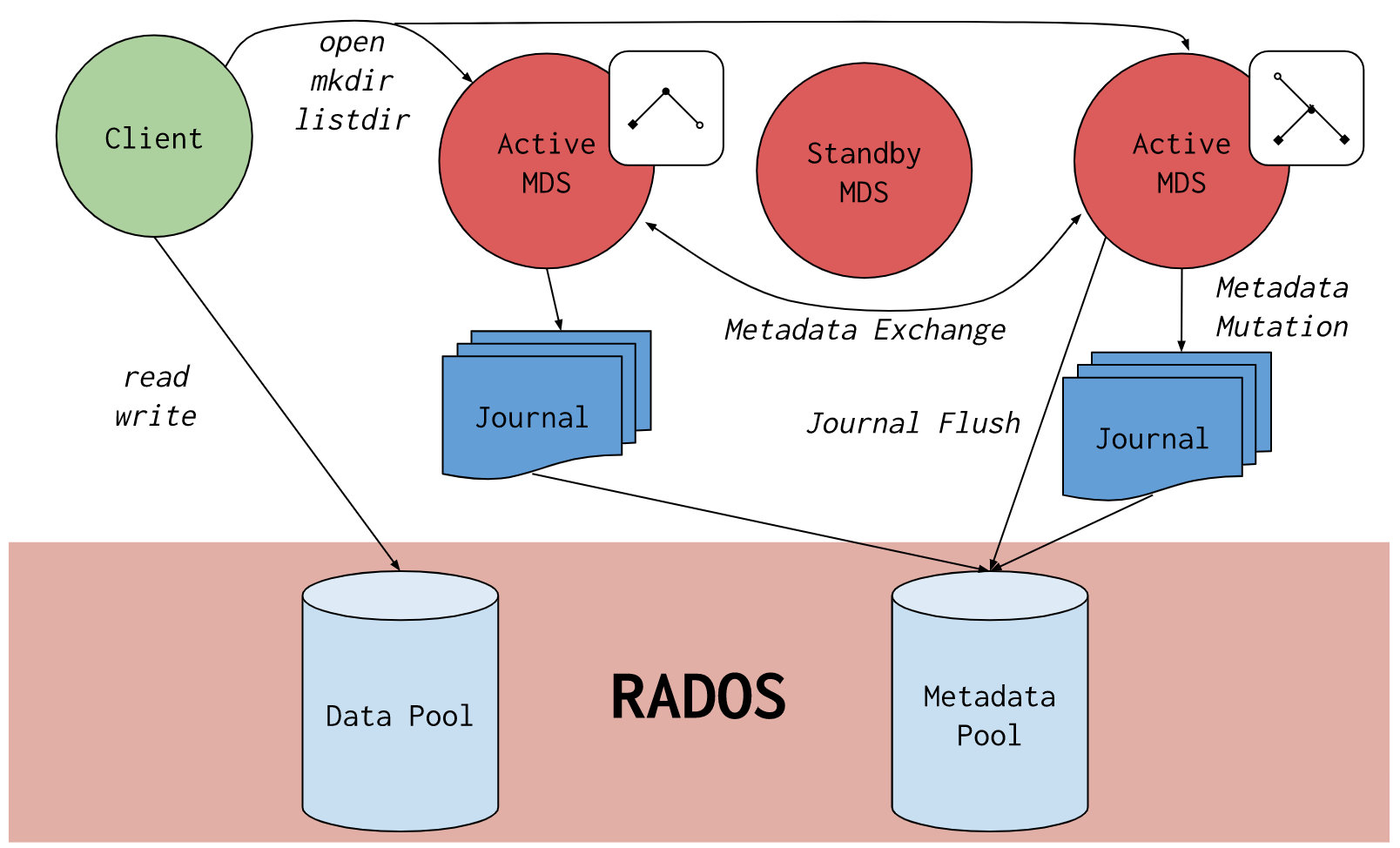
CephFS底层是基于RADOS的,具体来说是基于RADOS上的两个存储池,一个用来存储文件,一个用来存储文件的元数据。所以,诸如文件的目录结构等信息都是在元数据存储池里的,因此,如果有SSD,建议把元数据的存储池放在SSD上,一方面加速,另一方面,元数据的体积并不会特别大。而文件数据存储池应该放在HDD上。
# 先查看一下两个存储池❯ ceph osd pool ls detail...pool 5 'cephfs.cephfs.meta' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 463 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfspool 6 'cephfs.cephfs.data' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 464 flags hashpspool stripe_width 0 application cephfs# 通过修改CRUSH rule来将它们分别约束到SSD和HDD上❯ ceph osd pool set cephfs.cephfs.meta crush_rule on-ssdset pool 5 crush_rule to on-ssd❯ ceph osd pool set cephfs.cephfs.data crush_rule on-hddset pool 6 crush_rule to on-hdd
2.手动创建CephFS
当然,也可以通过手动的方式创建CephFS(假设名称为mycephfs):
# 先创建两个存储池❯ ceph osd pool create cephfs.mycephfs.meta on-ssd❯ ceph osd pool create cephfs.mycephfs.data on-hdd# 然后创建CephFS# ceph fs new <CephFS名称> <元数据存储池> <文件数据存储池>❯ ceph fs new mycephfs cephfs.mycephfs.meta cephfs.mycephfs.data
最后,挂载CephFS(需要安装ceph-commons):
❯ mkdir -p /mnt/cephfs❯ mount -t ceph :/ /mnt/cephfs -o name=admin,secret=AQBYSjZfQF+UJBAAC6QJjNACndkw2LcCR2XLFA==
NFS
Ceph推荐使用NFS-ganesha来提供NFS服务。
首先创建存储池nfs-ganesha(创建在SSD上):
❯ ceph osd pool create nfs-ganesha on-ssd# 以下这句可以不用执行,不过会有个”1 pool(s) do not have an application enabled“的WARN❯ ceph osd pool application enable nfs-ganesha nfs
然后利用cephadm部署NFS服务(这里我放在了两个OSD主机上了):
# ceph orch apply nfs *<svc_id>* *<pool>* *<namespace>* --placement="*<num-daemons>* [*<host1>* ...]"❯ ceph orch apply nfs nfs nfs-ganesha nfs-ns --placement="ceph-osd1 ceph-osd2"
为了在dashboard中进行操作,可以进行如下设置:
❯ ceph dashboard set-ganesha-clusters-rados-pool-namespace nfs-ganesha/nfs-ns
Ceph的NFS是基于CephFS提供的,我们首先在CephFS中创建一个/nfs目录,用于作为NFS服务的根目录。
# 前一步骤中已经挂载了CephFS到/mnt/cephfs❯ mkdir /mnt/cephfs/nfs
其中mount的时候的secret是/etc/ceph/ceph.client.admin.keyring的值,也可以替换成secretfile=/etc/ceph/ceph.client.admin.keyring。
最后,在dashboard中创建一个NFS即可:
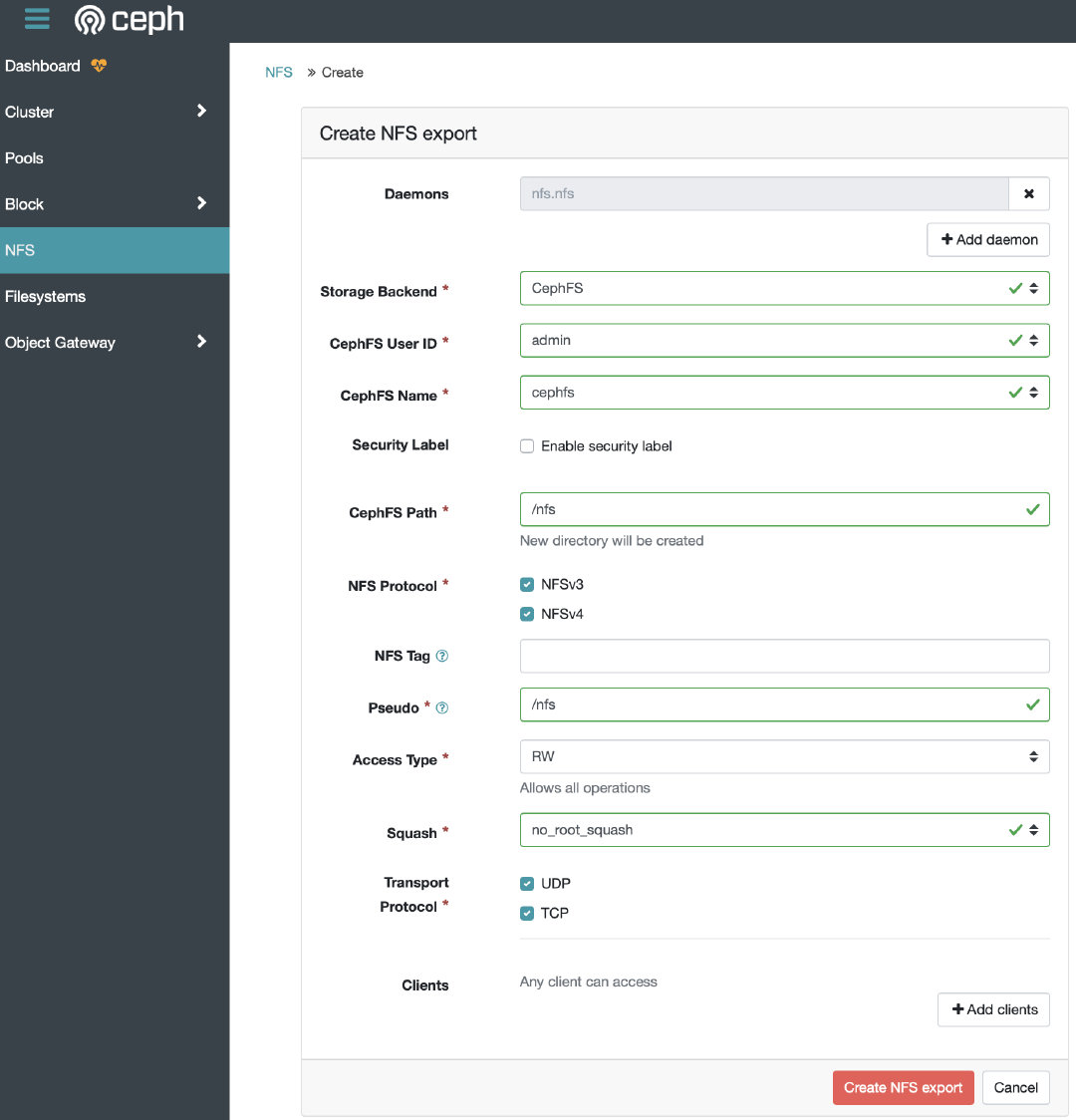
挂载NFS:
mount -t nfs 192.168.7.14:/nfs /mnt/nfs
















 5231
5231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











