







大家好,欢迎来到无限大的频道。
今日继续给大家带来力扣题解。
题目描述:
给你一个下标从 0 开始的整数数组 nums 。
一开始,所有下标都没有被标记。你可以执行以下操作任意次:
选择两个 互不相同且未标记 的下标 i 和 j ,满足 2 * nums[i] <= nums[j] ,标记下标 i 和 j 。
请你执行上述操作任意次,返回 nums 中最多可以标记的下标数目。


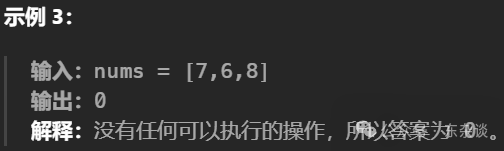
解题思路:
算法的核心思路是:
-
对数组进行排序。
-
使用双指针的方式遍历排序后的数组,寻找符合条件的下标。
-
每当找到一对符合条件的下标时,就将它们标记
分析题目和示例,我们以更深刻地理解下标标记的逻辑。原先整数数组的下标在被标记的之后,只是数据被标记,而非其固定的位置被标记,也就是说,是因为这个数据符合条件,从而标记该位置,而不是因为该位置符合条件,而去标记数据。
题目的关键在于标记的是数组中元素的特性,而非其在数组中的位置固定性。(这个是我个人总结出来的,在很多的算法问题中都有所体现)
所以当大家理解了这个条件之后,就可以把原先的数组进行排序,从而简化问题。
排序的经典函数如下
int compare(const void *a, const void *b) {
return (*(int *)a - *(int *)b);
}之后便是在解决问题的函数中进行调用
qsort(nums, numsSize, sizeof(int), compare);在这之后,我们的数组num,就变成了一个非递减排列的数组。
排序之后,就是采用双指针遍历数组了(因为涉及两个变量的比较,所以我采用了双指针的方式)
int compare(const void *a, const void *b) {
return (*(int *)a - *(int *)b);
}
int maxMarkableIndices(int* nums, int size) {
// 先对数组进行排序
qsort(nums, size, sizeof(int), compare);
int markedCount = 0; // 标记的下标数量
int i = 0; // 指向较小数字的指针
int j = 0; // 指向较大数字的指针
// 使用双指针遍历数组
while (i < size && j < size) {
// 找到一对符合条件的 (i, j)
if (2 * nums[i] <= nums[j] && i != j) {
markedCount += 2; // 每找到一对就标记两个下标
i++; // 移动指针 i
j++; // 移动指针 j
} else {
// 如果不符合条件,移动 j 指针
j++;
}
// 如果 j 指针已经达到数组的末尾,上面条件再检查时需要重置 j,给下一个 i 对应的 j
if (j == size && i < size) {
j = i + 1; // 对下一个 i 找 j
}
}
return markedCount; // 返回最多可以标记的下标数量
}
//双指针:使用两个指针 i 和 j,
//其中 i 指向较小的元素,j 指向较大的元素。
//每当找到符合条件的 (i, j) 对时,就将 markedCount 增加 2,
//并移动两个指针但是写完之后发现,这个代码的时间复杂度过高,不在题目的考虑范围之内,所以在此基础上继续优化。
在长度为 n 的数组当中,最理想的情况下只会产生 n/2 个下标数目,因为题目要求“互不相同且未标记”
由此对数组进行排序后,我们将其一分为二,左侧的元素只与右侧的元素进行匹配,其余思路同上,得出代码
int compare(const void* a, const void* b) {
return (*(int*)a - *(int*)b);
}
int maxNumOfMarkedIndices(int* nums, int numsSize){
qsort(nums, numsSize, sizeof(int), compare);
int n = numsSize;
int m = n / 2;
int res = 0;
for (int i = 0, j = m; i < m && j < n; i++) {
while (j < n && 2 * nums[i] > nums[j]) {
j++;
}
if (j < n) {
res += 2;
j++;
}
}
return res;
}时间复杂度:
1. 排序操作:
- 使用 `qsort` 函数对数组进行排序,时间复杂度为 (O(n log n)),其中 (n) 是数组的大小。排序是整个算法中最耗时的部分。
2. 双指针遍历:
- 在双指针的部分,外层循环的指针 `i` 最多会遍历 (n/2) 次(即左半边的元素),而内层循环的指针 `j` 也最多遍历 (n) 次。
- 在最坏情况下,指针 `j` 可能会从中间走到数组的末尾,但每次内层的 `while` 循环只会向前移动 `j` 指针,因此每个元素最多只会被遍历一次。
- 因此,双指针部分的时间复杂度为 (O(n))。
结合以上两部分,我们可以得出总的时间复杂度:
O(n log n) + O(n) = O(n log n)
空间复杂度:
1. 排序的空间复杂度:
- `qsort` 在排序过程中可能会使用额外的空间,具体取决于实现方式。通常情况下,快速排序的空间复杂度为 O(log n),用于递归调用的栈空间。
- 但在某些实现中,可能会使用 O(n) 的额外空间来存储临时数组(例如归并排序),然而在这里我们使用的是快速排序。
2. 其他变量:
- 除了排序外,其他变量(如 `n`, `m`, `res`, `i`, `j`)只占用常量空间 (O(1))。
因此,整体的空间复杂度主要由排序决定:
O(log n)
总结:
- 时间复杂度:(O(n log n))
- 空间复杂度:(O(log n))















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









