






文章目录
十四、Collections、Map
1、可变参数
就是一种特殊的形参,定义在方法、构造器的形参列表里,格式是:数据类型...参数名称
可变参数的特点和好处
特点:可以不传数据给它;可以传一个或者同时传多个数据给它,也可以传一个数组给它
好处:常常用来灵活的接收数据
注意:
①可变参数在形参列表中只能出现一个
②可变参数必须放在形参列表的最后面
/**
* @author Tender
* @date 2025/4/8 10:25
*/
package com.tender.d1_param;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
// 求任意一个整数数据的和
sum();
sum(10);
sum(20, 15, 30);
sum(new int[]{10, 25, 30});
}
public static void sum(int... nums) {
System.out.println("个数:"+nums.length);
System.out.println("内容:"+ Arrays.toString(nums));
}
}
2、Collections
是一个用来操作集合的工具类
Collections提供常用静态方法

package com.tender.d2.collections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 目标:掌握Collections集合工具类的使用。
*/
public class CollectionsTest1 {
public static void main(String[] args) {
// 1、public static <T> boolean addAll(Collection<? super T> c, T...elements):为集合批量添加数据
List<String> names = new ArrayList<>();
// Collections.addAll(names, "张无忌", "赵敏", "小昭", "殷素素");
// System.out.println(names);
Collections.addAll(names,"张无忌","殷素素","赵敏","小昭");
System.out.println(names);
// 2、public static void shuffle(List<?> list):打乱List集合中的元素顺序
// Collections.shuffle(names);
// System.out.println(names);
Collections.shuffle(names);
// 3、 public static <T> void sort(List<T> list):对List集合中的元素进行升序排序。
List<Student> students = new ArrayList<>();
Student s1 = new Student("赵敏", 19, 169.5);
Student s2 = new Student("周芷若", 18, 171.5);
Student s3 = new Student("周芷若", 18, 171.5);
Student s4 = new Student("小昭", 17, 165.5);
Collections.addAll(students, s1, s2, s3, s4);
// 方式一:让对象的类实现Comparable接口,从写compare方法,指定大小比较规则
Collections.sort(students);
System.out.println(students);
// 4、public static <T> void sort(List<T> list, Comparator<? super T> c):
// 对List集合中元素,按照比较器对象指定的规则进行排序
// 方式二:指定Comparator比较器对象,再指定比较规则。
Collections.sort(students, ((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())));
System.out.println(students);
}
}
3、Map
3.1 认识Map
①Map集合称为双列集合,格式:{key1 = value1,key2 = value2……},一次需要存一会数据作为一个元素。
②Map集合的每一个元素key1 = value1,称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做键值对集合
③Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
Map集合体系
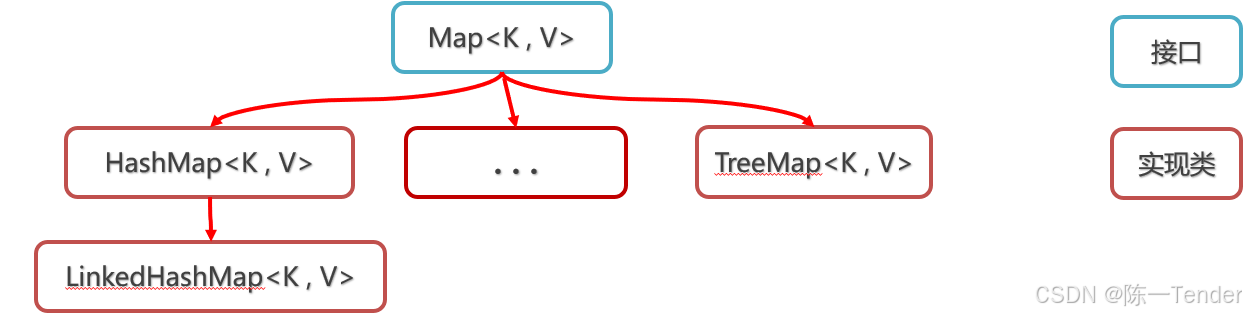
Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个fushup,值是不做要求的
HashMap(由键决定特点):无序、不重复、无索引,用的最多
LinkedHashMap(由键决定特点):有序、不重复、无索引
TreeMap(由键决定特点):按照大小默认升序排序、不重复,无索引
/**
* @author Tender
* @date 2025/4/8 15:29
*/
package com.tender.d4_map;
import java.util.HashMap;
import java.util.Map;
public class MapDemo1 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("Java入门到跑路", 2);
map.put("小米手表", 31);
map.put("小米15pro", 2);
map.put("小米pad7pro", 2);
map.put("电动牙刷", 2);
map.put("手机壳", 1);
map.put(null, null);
System.out.println(map);
}
}
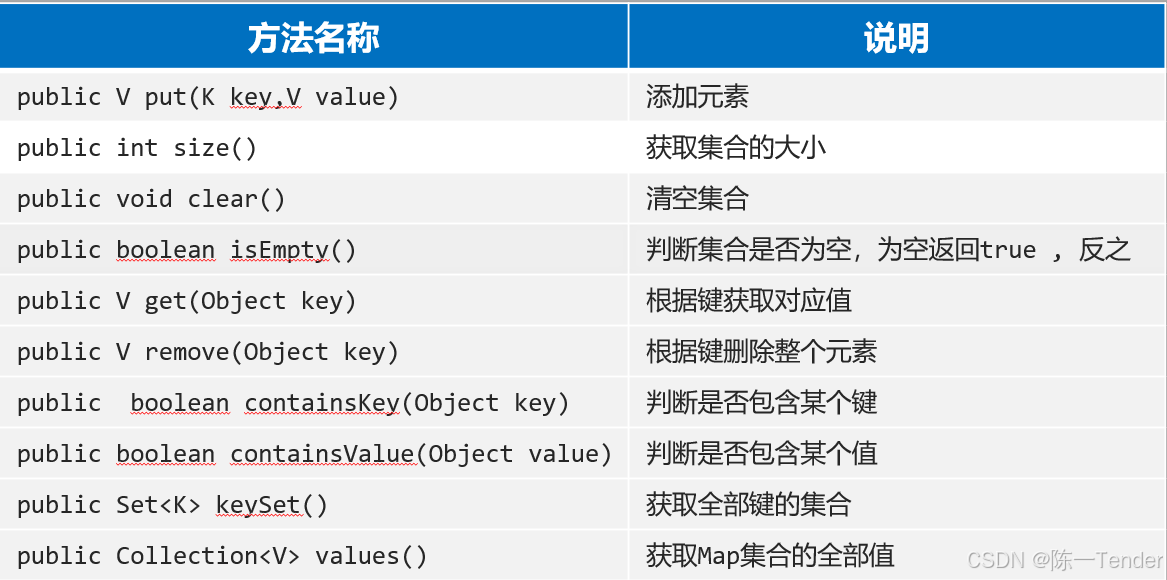
3.2 Map的常用方法
package com.tender.d4_map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo2 {
public static void main(String[] args) {
// 目标:掌握Map集合的常用API(重点)
Map<String, Integer> map = new HashMap<>();
map.put("手表" ,2);
map.put("iphone" ,31);
map.put("huawei" ,365);
map.put("iphone" ,1);
map.put("娃娃", 31);
map.put("Java入门",1);
map.put(null,null);
System.out.println(map);
// map = {null=null, 手表=2, huawei=365, Java入门=1, 娃娃=31, iphone=1}
// 1、获取集合的大小(元素个数)
System.out.println(map.size()); // 6
// 2、清空集合
// map.clear();
System.out.println(map);
// 3、判断集合是否为空
System.out.println(map.isEmpty());
// 4、根据键获取对应的值(重点)
System.out.println(map.get("手表"));
System.out.println(map.get("手表2")); // 如果没有这个键,返回null
// 5、根据键删除整个数据,返回删除数据对应的值。(重点)
System.out.println(map.remove("娃娃"));
System.out.println(map);
// 6、判断是否包含某个键(重点)'
// map = {null=null, 手表=2, huawei=365, Java入门=1,iphone=1}
System.out.println(map.containsKey("娃娃")); // false
System.out.println(map.containsKey("huawei")); // true
System.out.println(map.containsKey(null)); // true
System.out.println(map.containsKey("手表2")); // false
// 7、判断是否包含某个值
// map = {null=null, 手表=2, huawei=365, Java入门=1,iphone=1}
System.out.println(map.containsValue(1)); // true
System.out.println(map.containsValue(365)); // true
System.out.println(map.containsValue("1")); // false
// 8、获取Map集合的全部键,到一个Set集合中返回的
// map = {null=null, 手表=2, huawei=365, Java入门=1,iphone=1}
// public Set<K> keySet():
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println(key);
}
// 9、获取Map集合的全部值:到一个Collection集合中返回的。
Collection<Integer> values = map.values();
for (Integer value : values) {
System.out.println(value);
}
}
}
3.3 Map集合的遍历
①键找值:先获取Map集合全部的键,再通过遍历键来找值

/**
* @author Tender
* @date 2025/4/8 15:47
*/
package com.tender.d5_map_traverse;
import java.security.Key;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo1 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("手表" ,2);
map.put("iphone" ,31);
map.put("huawei" ,365);
map.put("Java入门",1);
Set<String> keys = map.keySet();
for (String key : keys){
Integer value = map.get(key);
System.out.println(key+"======>>"+value);
}
}
}
②键值对:把“键值对”看成一个整体进行遍历(难度较大)
package com.tender.d5_map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo2 {
public static void main(String[] args) {
// 目标:掌握Map集合的遍历方式二:键值对遍历(难度大点)
Map<String, Integer> map = new HashMap<>();
map.put("蜘蛛精", 1000);
map.put("小龙女", 23);
map.put("木婉清", 31);
map.put("黄蓉", 35);
System.out.println(map);
// map = {蜘蛛精=1000, 小龙女=23, 黄蓉=35, 木婉清=31}
// 1、一开始是想通过增强for直接遍历Map集合,但是无法遍历,因为键值对直接来看是不存在数据类型的。
// for (元素类型 变量: map){
//
// }
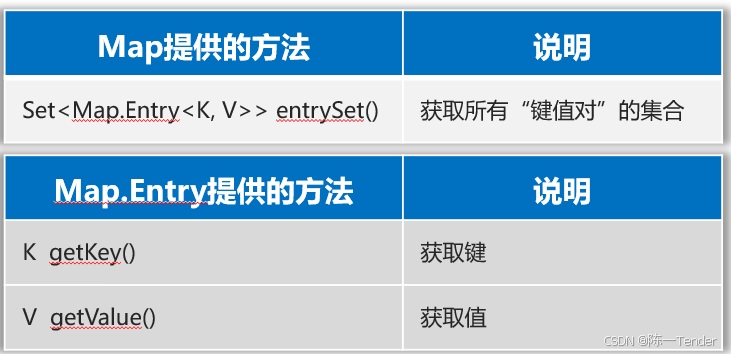
// 2、调用Map集合的一个方法,把Map集合转换成Set集合来遍历
/**
* map = {蜘蛛精=1000, 小龙女=23, 黄蓉=35, 木婉清=31}
* ↓
* map.entrySet()
* ↓
* Set<Map.Entry<String, Integer>> entries = [(蜘蛛精=1000), (小龙女=23), (黄蓉=35), (木婉清=31)]
* entry
*/
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key+"=="+value);
}
}
}
③Lambda:JDK1.8开始之后的新技术,非常简单

package com.tender.d5_map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class MapDemo3 {
public static void main(String[] args) {
// 目标:掌握Map集合的遍历方式三:Lambda
Map<String, Integer> map = new HashMap<>();
map.put("蜘蛛精", 1000);
map.put("小龙女", 23);
map.put("木婉清", 31);
map.put("黄蓉", 35);
System.out.println(map);
// map = {蜘蛛精=1000, 小龙女=23, 黄蓉=35, 木婉清=31}
map.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String key, Integer value) {
System.out.println(key + "===>" + value);
}
});
map.forEach((key, value) -> {
System.out.println(key + "===>" + value);
});
}
}
3.4 HashMap集合的底层原理
①HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的。
②实际上:原来学的Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已。
HashMap底层是基于哈希表实现的
①HashMap集合是一种增删改查数据,性能都较好的集合
②但是它是无序,不能重复,没有索引支持的(由键决定特点)
③HashMap的键依赖hashCode方法和equals方法保证键的唯一
④如果键存储的是自定义类型的数据对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为时重复的
package com.tender.d6_map_impl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data // Data自带了无参 + get + set + toString + hashCode + equals
@NoArgsConstructor
@AllArgsConstructor
public class Movie implements Comparable<Movie>{
private String name;
private double score;
private String actor;
@Override
public int compareTo(Movie o) {
return Double.compare(this.score, o.score);
}
}
package com.tender.d6_map_impl;
import java.util.HashMap;
import java.util.Map;
public class MapTest1 {
public static void main(String[] args) {
// 目标:掌握Map集合(键)去重复的机制。
Map<Movie, String> map = new HashMap<>();
map.put(new Movie("摔跤吧,爸爸", 9.5, "阿米尔汗"), "19:00");
map.put(new Movie("三傻宝莱坞", 8.5, "阿米尔汗2"), "20:50");
map.put(new Movie("三傻宝莱坞", 8.5, "阿米尔汗2"), "21:50");
map.put(new Movie("阿甘正传", 7.5, "汤姆汉克斯"), "21:00");
System.out.println(map);
}
}
3.5 LinkedHashMap集合的原理
①底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外多了一个双链表的机制记录元素顺序(保证有序)
②实际上:原来学习的LinkedHashSet集合的底层原理就是LinkedHashMap
package com.tender.d6_map_impl;
import java.util.*;
public class MapTest2 {
public static void main(String[] args) {
// 目标:掌握Map集合的特点。
// Map体系整体特点:HashMap : 按照键,无序,不重复,无索引。值不做要求,键和值都可以是null
Map<String, Integer> map = new LinkedHashMap<>(); // LinkedHashMap 按照键,有序,不重复,无索引。值不做要求,键和值都可以是null
map.put("手表" ,2);
map.put("iphone" ,31);
map.put("huawei" ,365);
map.put("iphone" ,1);
map.put("娃娃", 31);
map.put("Java入门",1);
map.put(null,null);
System.out.println(map); // {手表=2, iphone=1, huawei=365, 娃娃=31, Java入门=1, null=null}
}
}
3.6 TreeMap集合的原理
特点:不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
原理:TreeMap更TreeSe集合的底层原理是一样的,都是基于红黑树实现的排序
TreeMap集合同样也支持两种方式来指定排序规则
让类实现Comparable接口,重写比较规则
TreeMap集合有一个有参构造器,支持创建Comparator比较器对象,以便用来指定比较规则
4、集合的嵌套
package com.tender.d6_map_impl;
import java.util.*;
public class MapTest4 {
public static void main(String[] args) {
// 目标:掌握集合的嵌套(重点)
// 1、定义一个Map集合存储全部省份和城市信息。
Map<String, List<String>> provinces = new HashMap<>();
// 2、存入省份信息
List<String> cities1 = new ArrayList<>();
Collections.addAll(cities1, "南京市", "扬州市", "苏州市", "无锡市", "常州市");
provinces.put("江苏省", cities1);
List<String> cities2 = new ArrayList<>();
Collections.addAll(cities2, "武汉市", "襄阳市", "孝感市", "十堰市", "宜昌市");
provinces.put("湖北省", cities2);
List<String> cities3 = new ArrayList<>();
Collections.addAll(cities3, "石家庄市", "唐山市", "邢台市", "保定市", "张家口市");
provinces.put("河北省", cities3);
System.out.println(provinces);
List<String> hbcities = provinces.get("湖北省");
for (String hbcity : hbcities) {
System.out.println(hbcity);
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









