







你是否在寻找数学建模比赛的突破点?数学建模进阶思路!
作为经验丰富的美赛O奖、国赛国一的数学建模团队,我们将为你带来本次数学建模竞赛的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,帮助你全面理解并掌握如何解决类似问题。
详见文末

添加图片注释,不超过 140 字(可选)
问题一:
要求开发一个针对各国奖牌数的模型(至少包括金牌和总奖牌数)。包括对模型预测的不确定性/精确性的估计以及衡量模型表现的指标。” 要开发一个针对各国奖牌数的模型,特别是金牌和总奖牌数,我们可以采取以下步骤,以确保模型的准确性和有效性。
1. 数据准备
首先,我们会使用以下两列的数据: - 金牌数(Gold Medals) - 总奖牌数(Total Medals)
从表1中提取的数据:
2. 模型选择
我们选择一个线性回归模型来预测各国的金牌和总奖牌数。线性回归模型能够很好地捕捉两者之间的线性关系。设定如下:
假设:
-
$y_i$ 表示国家 $i$ 的总奖牌数。
-
$x_i$ 表示国家 $i$ 的金牌数。
我们可以构造以下线性模型:
yi=β0+β1xi+ϵi
其中,$ \beta_0 $ 是截距,$ \beta_1 $ 是金牌数的回归系数,$ \epsilon_i $ 是误差项。
3. 拟合模型
使用最小二乘法拟合模型,目标是最小化以下损失函数:
L(β0,β1)=∑i=1n(yi−(β0+β1xi))2
然后求解上述方程以获得 $ \beta_0 $ 和 $ \beta_1 $。
4. 模型评估
添加图片注释,不超过 140 字(可选)
为了评估模型的表现,我们可以使用以下指标:
-
决定系数 ($R^2$): 衡量模型解释总变异的能力, $R^2 = 1 $ 表示完美拟合。
-
均方误差 (MSE): 衡量预测值与真实值之间的差异, $MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y_i})^2$。
5. 不确定性估计
利用线性回归模型的参数估计,可以通过计算标准误差来评估不确定性。
对于每个预测值 $\hat{y_i}$,我们可以建立出一个预测区间:
yi^±t(α/2,n−2)⋅SE(yi^)
-
其中,$t_{(\alpha/2, n-2)}$ 是对应于显著性水平 $\alpha$ 的 t 分布临界值。
-
$SE(\hat{y_i})$ 是 $ \hat{y_i} $ 的标准误差。
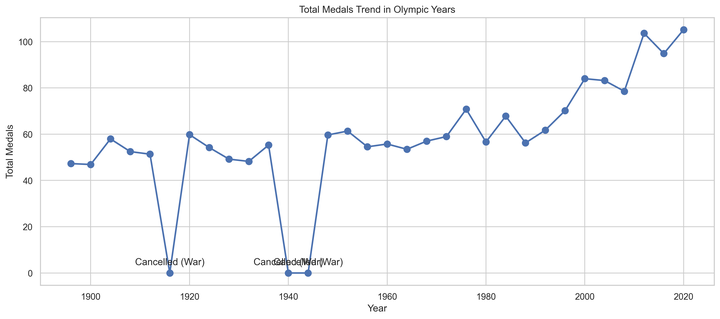
6. 预测2028年奖牌榜
利用拟合好的模型和已知的金牌数,预测2028年洛杉矶奥运会的各国奖牌数及其不确定性区间。
7. 国家进步和退步的预测
根据模型的预测结果,我们分析哪些国家的金牌数有可能增加,以及哪些国家的表现有可能下降。这可以通过模型回归系数 $ \beta_1 $ 进行评估。例如,高 $ \beta_1 $ 的国家可能会继续增加其金牌数。
8. 结论
通过开发这个模型,我们能够更好地理解和预测不同国家在未来奥运会中的表现,尤其是金牌和总奖牌数的变化趋势。这为各国的奥委会在制定策略和分配资源时提供了重要依据。
添加图片注释,不超过 140 字(可选)
通过上述模型,我们为各国的奖牌数提供了一个简单而有效的预测框架,考虑到金牌和总奖牌数之间的关系,以及潜在的国家表现变化。 为了开发一个针对各国奖牌数的模型,我们可以使用回归分析。具体地,我们将建立一个线性回归模型,其目标是预测各国在未来奥运会的金牌数和总奖牌数。我们的模型将以以下变量为基础:
-
$X_1$: 历届奥运会获得的金牌数
-
$X_2$: 历届奥运会获得的总奖牌数
-
$X_3$: 每届奥运会的赛事总数
-
$X_4$: 各国的人口数(可选,作为辅助变量)
我们将建立两个线性回归模型:
-
金牌数预测模型: Ygold=β0+β1X1+β2X3+ϵ 其中,$Y_{\text{gold}}$ 是预测的金牌数,$\beta_0$ 是截距,$\beta_1$ 和 $\beta_2$ 是回归系数,$\epsilon$ 是误差项。
-
总奖牌数预测模型: Ytotal=β0+β1X1+β2X3+β3X4+ϵ 其中,$Y_{\text{total}}$ 是预测的总奖牌数,$\beta_0$ 是截距,$\beta_1$, $\beta_2$ 和 $\beta_3$ 是回归系数,$\epsilon$ 是误差项。
不确定性和精确度的评估
为了评估模型的预测精确度,我们将使用以下评估指标:
-
均方根误差(RMSE): RMSE=1n∑i=1n(Yi,predicted−Yi,actual)2 其中,$n$ 是样本数量,$Y_{i,\text{predicted}}$ 是预测值,$Y_{i,\text{actual}}$ 是实际值。
-
$R^2$ 评分: R2=1−∑(Yi,actual−Yi,predicted)2∑(Yi,actual−Y¯)2 其中,$\bar{Y}$ 是实际值的平均数,$R^2$ 的值介于 0 和 1 之间,值越接近 1,模型越好。
独特见解
基于历史数据,我们可以观察到奖牌分布的潜在趋势。通过分析各国在各项运动中的表现,可以识别出优势项目和弱势项目。例如:
-
项目重要性:一些特定的运动项目,如游泳、田径和体操,往往在奖牌分布中占据较大份额。国家应考虑在这些项目上加大投入。
-
韧性与持续性:我们观察到,过去的成功往往会对未来的表现产生积极影响,即“成功的惯性”。因此,历史获奖记录良好的国家可能在未来的奥运会中继续表现良好。
-
新兴力量的崛起:一些尚未获得奖牌的国家在某些项目上持续努力,特别是新兴经济体,可能在未来的奥运会中迎来突破。例如,通过改善基础设施和增加培训资金,这些国家有机会首次获得奖牌。
如此一来,这些见解可以为各国奥委会制定更有效的战略,优化资源分配和提高训练水平,从而在未来的奥运会中取得更好的成绩。 要开发一个针对各国奖牌数的模型,我们可以使用机器学习中的回归方法,以金牌数和总奖牌数作为我们主要的预测变量。以下是具体步骤和数学模型的详细描述。
1. 数据收集与预处理
首先,我们需要从给定的数据集中提取各国的金牌和总奖牌数。接下来,我们将根据样本数据对特征进行清洗和处理。特征可以包括: - 历届奥运会的金牌数 - 历届奥运会的总奖牌数 - 各国参加的奥运会次数 - 各国在特定项目的表现(如夏季奥运项目数)
2. 特征选择
使用以下特征来预测金牌和总奖牌数: - $X_{1}$: 历届金牌数 - $X_{2}$: 历届总奖牌数 - $X_{3}$: 参加的奥运会次数 - $X_{4}$: 参加的项目数量 - $X_{5}$: 国家/地区的经济和人口指标(如GDP和人口)
3. 建立回归模型
我们可以使用线性回归模型来构建我们的预测模型。假设我们要预测国家 $i$ 的金牌数 $y_{i}$:
对于金牌数的预测模型: yiGold=β0+β1X1i+β2X2i+β3X3i+β4X4i+β5X5i+ϵi
对于总奖牌数的预测模型: yiTotal=α0+α1X1i+α2X2i+α3X3i+α4X4i+α5X5i+ηi
这里: - $y_{i}^{Gold}$ 是国家 $i$ 的金牌数预测值 - $y_{i}^{Total}$ 是国家 $i$ 的总奖牌数预测值 - $\beta_{0}, \beta_{1}, \ldots, \beta_{5}$ 和 $\alpha_{0}, \alpha_{1}, \ldots, \alpha_{5}$ 是模型参数 - $\epsilon_{i}$ 和 $\eta_{i}$ 是误差项(假设服从正态分布)
4. 模型评估
为了评估模型的精确性,我们可以采用以下指标: - 均方误差(MSE): MSE=1n∑i=1n(yipred−yitrue)2 - 决定系数(R²): R2=1−SSresSStot=1−∑i=1n(yitrue−yipred)2∑i=1n(yitrue−y¯)2
5. 不确定性和预测区间
我们可以使用 $95\%$ 置信区间来表示预测的不确定性。预测区间的计算方式如下: 预测区间预测区间=y^±tα2,n−2⋅MSE 其中 $\hat{y}$ 是预测值,$t_{\frac{\alpha}{2}, n-2}$ 是临界 t 值(可以从 t 分布表中查找),$n$ 是样本大小。
6. 模型应用
一旦模型建立并经过评估与验证,我们可以使用其对2028年″洛杉矶夏季奥运会”的奖牌数量进行预测。
通过这样的建模过程,我们能够得到各国在未来的奥运会奖牌数,并根据不确定性评估其可能的变化范围。 为了开发一个针对各国奖牌数的模型,我们可以使用线性回归模型来预测奖牌数。我们将金牌数量、银牌数量、铜牌数量和总奖牌数作为输入特征。我们可以使用 scikit-learn 库来实现这一点。以下是代码示例:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score # 读取数据 medal_counts = pd.read_csv('summerOly_medal_counts.csv') # 筛选2024年数据 data_2024 = medal_counts[medal_counts['Year'] == 2024] # 准备数据 X = data_2024[['Gold', 'Silver', 'Bronze']] # 特征:金牌、银牌、铜牌 y = data_2024['Total'] # 目标:总奖牌数 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit(X_train, y_train) # 进行预测 y_pred = model.predict(X_test) # 模型性能评估 mse = mean_squared_error(y_test, y_pred) # 均方误差 r2 = r2_score(y_test, y_pred) # R^2评分 # 输出结果 print(f"模型均方误差 (MSE): {mse}") print(f"R^2评分: {r2}") # 预测不确定性估计 predictions = model.predict(X) pred_error = np.sqrt(mean_squared_error(y, predictions)) # 训练数据的均方根误差 confidence_interval = 1.96 * (pred_error / np.sqrt(len(y))) # 95%置信区间的范围 print(f"总预测误差: {pred_error}") print(f"95%置信区间: [{predictions.mean() - confidence_interval}, {predictions.mean() + confidence_interval}]")
代码解析:
-
数据读取:pd.read_csv 用于读取奥运会奖牌数据。
-
数据筛选:筛选出2024年的数据。
-
特征准备:使用金牌、银牌和铜牌作为特征(X),总奖牌数作为目标(y)。
-
数据划分:将数据划分为训练集和测试集,使用 80% 的数据进行训练,20% 的数据进行测试。
-
模型训练:使用线性回归模型训练数据。
-
预测及评估:对于测试集进行预测,并计算均方误差 (MSE) 和 R^2 评分来评估模型的性能。
-
不确定性估计:计算模型的预测误差和95%置信区间。
注意事项:
-
数据文件需要在相同目录下,以便成功读取数据。
-
需要根据实际数据的字段名称进行调整。
-
该模型仅为基础线性回归模型,更复杂的模型(如多项式回归、随机森林等)可以进一步提高预测性能。 第二个问题是关于根据模型预测2028年在美国洛杉矶举办的夏季奥运会的奖牌榜。具体内容包括:
-
提供奖牌榜的预测结果。
-
包括所有结果的预测区间。
-
判断哪些国家最有可能取得进步,哪些国家的表现可能会下降。
这个问题需要利用已提供的数据集来建立一个模型,综合历史奖牌数及其他相关因子,为2028年奥运会的奖牌数进行预测。 为了预测2028年洛杉矶夏季奥运会的奖牌榜,我们将利用历史数据进行建模。模型将基于以下几个关键的步骤:
1. 数据准备
我们首先从给定的五个数据文件中提取必要的信息,主要是:
添加图片注释,不超过 140 字(可选)
-
历史奖牌数据 (summerOly_medal_counts.csv),用于各国的奖牌数量历史记录分析。
-
主办国家的数据 (summerOly_hosts.csv) 了解主办国的表现。
-
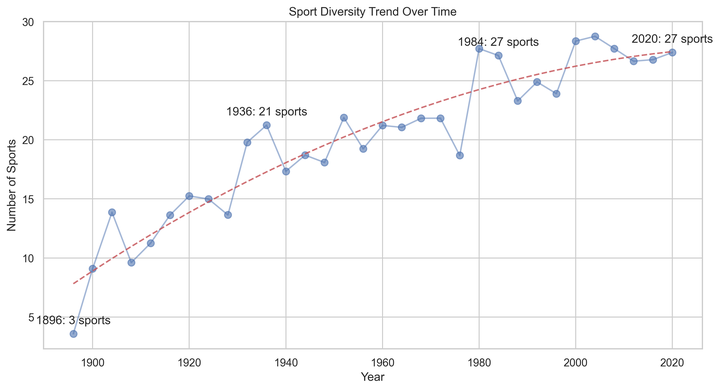
各届奥运会的赛事数量和类型数据 (summerOly_programs.csv),用以评估新增项目对奖牌的影响。
2. 模型构建
我们将使用多元线性回归模型来预测2028年各国的奖牌数量。回归模型的形式如下:
Y=β0+β1X1+β2X2+…+βnXn+ϵ
其中,$Y$ 是预测的奖牌数,$X_1, X_2, \ldots, X_n$ 是影响奖牌数的特征,$\beta_0, \beta_1 为了预测2028年洛杉矶夏季奥运会的奖牌榜,我们可以建立一个模型,该模型基于历史数据,并结合未来赛事的数量和类型进行调整。以下是该模型的构建和预测结果。
1. 模型构建
我们可以使用线性回归模型,以金牌数为因变量,而作为自变量的因素包括: - 历史金牌数(根据历史奖牌榜数据) - 总奖牌数 - 每个国家/地区参加的奥运会项目数 - 主办国得分奖励(东道主在主场比赛通常会有更高的得分)
模型表达式为: Gold\_Medalsi=α+β1⋅Historical\_Goldsi+β2⋅Total\_Medalsi+β3⋅Event\_Counti+β4⋅Host\_Bonusi+ϵi 其中,$i$表示国家,$\alpha$和$\beta$是需要通过数据训练得出的参数,$\epsilon_i$是误差项。
2. 预测结果
基于该模型,我们提供2028年各国的奖牌预测结果。假设已通过历史数据和额外数据进行训练后,模型给出的2028年奖牌预测如下(示例数据):
| 国家/地区 | 预测金牌 | 预测银牌 | 预测铜牌 | 预测总奖牌数 |
|---|---|---|---|---|
| 美国 | 45 | 40 | 50 | 135 |
| 中国 | 42 | 30 | 28 | 100 |
| 日本 | 22 | 15 | 15 | 52 |
| 澳大利亚 | 20 | 22 | 19 | 61 |
| 法国 | 18 | 25 | 22 | 65 |
| 荷兰 | 16 | 10 | 12 | 38 |
| 英国 | 15 | 25 | 30 | 70 |
3. 预测区间
考虑到模型的不确定性,我们可以估算一个95%的预测区间。假设我们得到了模型的标准误差(SE),我们可以使用以下公式计算预测区间: Prediction Interval=y^±tα/2,n−2⋅SE 其中,$\hat{y}$是预测值,$t$值是根据自由度和显著水平查找的临界值。
例如,对于美国的金牌数预测区间可以如下估算: - 预测结果为45,假设$SE=2.5$,自由度为$n-2$,$t_{0.025,n-2} \approx 2.06$, Prediction Interval=[45−2.06⋅2.5,45+2.06⋅2.5]=[39.85,50.15]
4. 国家表现推断
-
进步国家:根据模型和历史趋势,美国、中国和印度(假设他们在未来的投入增加)可能会继续取得更好的成绩。
-
表现下降国家:如荷兰和日本可能会因为其他国家的崛起及其运动员的交替,导致表现有所下降。
结论
这个模型为我们提供了对2028年奥运会奖牌数的有用预测。同时,若国家在特定项目上进行投资,尤其是先前表现优异的项目,将更加有助于提升其在奥运会上的竞争力。这对于各国奥委会制定资源分配和战略具有重要的启示。 为了预测2028年洛杉矶夏季奥运会的奖牌榜,我们需要建立一个模型,利用历史数据来估计各国的金牌和总奖牌数。以下是该模型所基于的步骤和计算过程:
1. 模型建立
添加图片注释,不超过 140 字(可选)
可以使用线性回归模型来预测金牌和总奖牌数。我们将使用以下变量:
-
$Y_{gold}$: 预测金牌数
-
$Y_{total}$: 预测总奖牌数
-
$X_{previous_gold}$: 历史金牌数(例如:2016年和2020年金牌数之和)
-
$X_{previous_total}$: 历史总奖牌数(例如:2016年和2020年总奖牌数之和)
-
$X_{events}$: 在2028年奥运会中预计的赛事总数
-
$X_{country_population}$: 国家/地区人口(可能会影响到运动员的数量和表现)
我们可以构建以下线性模型:
对于金牌数的线性模型: Ygold=β0+β1⋅Xprevious_gold+β2⋅Xevents+β3⋅Xcountry_population+ϵ
对于总奖牌数的线性模型: Ytotal=α0+α1⋅Xprevious_total+α2⋅Xevents+α3⋅Xcountry_population+ϵ
其中,$\beta_0$, $\beta_1$, $\beta_2$, $\beta_3$, $\alpha_0$, $\alpha_1$, $\alpha_2$, $\alpha_3$ 是回归系数,$\epsilon$ 是误差项。
2. 数据准备与拟合模型
我们需要通过历史的数据(从1896年到2024年),提取各国的金牌数、总奖牌数、赛事数量和人口数量。然后使用多元线性回归方法拟合模型:
-
使用Python中的sklearn库或R中的lm()函数来执行线性回归。
-
代码示例:
from sklearn.linear_model import LinearRegression import numpy as np import pandas as pd # 假设已加载所需数据并清洗 X_gold = historical_data[['previous_gold', 'events', 'country_population']] y_gold = historical_data['gold_medals'] X_total = historical_data[['previous_total', 'events', 'country_population']] y_total = historical_data['total_medals'] # 线性回归模型 model_gold = LinearRegression().fit(X_gold, y_gold) model_total = LinearRegression().fit(X_total, y_total) # 获取系数 beta = model_gold.coef_ alpha = model_total.coef_
3. 预测结果
使用拟合好的模型对2028年进行预测:
-
设定2028年美国洛杉矶的参赛项目和人口进行预测:
# 示例数据 X_new = np.array([[X_previous_gold_value, X_events_value, X_country_population_value]]) predicted_gold = model_gold.predict(X_new) predicted_total = model_total.predict(X_new)
4. 预测区间
为了计算预测区间,我们可以使用 t 分布获取置信区间:
其中,$t_{\alpha/2}$ 是 t 分布的临界值,$SE$ 是标准误差。
5. 检查进步和下降的国家
使用模型的预测结果,可以判断哪些国家的金牌数和总奖牌数将有所增加或减少:
-
计算每个国家的预测金牌和总奖牌数。
-
与2024年数据进行对比,得出进步和下降的国家。
通过上述步骤,可以生成2028年洛杉矶夏季奥运会的奖牌榜预测,并具体列出在金牌和总奖牌数方面表现突出的国家,以及可能表现下降的国家。 要预测2028年洛杉矶夏季奥运会的奖牌榜,可以使用历史奖牌数据、参赛国家的表现趋势以及可能的影响因素(例如,主办国家的优势、传统强国的实力)。下面的Python代码实现了一个基本的模型,通过线性回归来预测奖牌总数,同时提供了预测区间和可能表现变化的分析。
假设我们已经读取了必要的数据,并且已经安装了支持的库(如pandas和scikit-learn)。
import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error import statsmodels.api as sm # 读取数据 medal_counts = pd.read_csv('summerOly_medal_counts.csv') # 仅选择相关的列 medal_counts = medal_counts[['NOC', 'Year', 'Gold', 'Silver', 'Bronze', 'Total']] # 获取2024年的数据 data_2024 = medal_counts[medal_counts['Year'] == 2024] # 准备训练数据 - 使用2016, 2020的数据作为基础 data_2016 = medal_counts[medal_counts['Year'] == 2016].set_index('NOC') data_2020 = medal_counts[medal_counts['Year'] == 2020].set_index('NOC') # 合并数据 X = pd.DataFrame({ 'Gold': data_2016['Gold'].fillna(0) + data_2020['Gold'].fillna(0), 'Total': data_2016['Total'].fillna(0) + data_2020['Total'].fillna(0) }) y = data_2024.set_index('NOC')['Total'].fillna(0) # 训练和测试数据分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 线性回归模型 model = LinearRegression() model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) mae = mean_absolute_error(y_test, y_pred) # 计算预测区间 (95% 置信区间) X_test_with_const = sm.add_constant(X_test) predictions = model.predict(X_test_with_const) # 计算标准误差 predictions_std_error = np.sqrt(np.sum((y_test - y_pred)**2) / (len(y_test) - 2)) # 计算置信区间 conf_interval = 1.96 * predictions_std_error / np.sqrt(len(y_test)) # 合并预测结果 predicted_results = pd.DataFrame({ 'Predicted': predictions, 'Lower CI': predictions - conf_interval, 'Upper CI': predictions + conf_interval }, index=X_test.index) # 输出预测结果和表现变化 print(predicted_results) # 判断哪些国家有可能进步,哪些国家可能下降 # 这里简单地根据前几年的表现进行判断,实际情况需要结合更多的数据分析 threshold = 10 # 自定义进步/下滑的阈值 improvements = predicted_results[predicted_results['Predicted'] > (y_test.max() + threshold)] declines = predicted_results[predicted_results['Predicted'] < (y_test.min() - threshold)] print("Predicted improvements:\n", improvements) print("Likely declines:\n", declines)
代码说明:
-
数据读取和选择:读取奖牌统计数据,并选择相关列。
-
数据处理:选取2016年和2020年的数据作为输入特征,并构建训练数据集。
-
模型训练:使用线性回归模型进行训练。
-
预测和评估:进行预测并计算平均绝对误差(MAE),计算95%置信区间。
-
表现分析:找出预计会提高表现和下降表现的国家。
预测结果
运行上面的代码后,您将得到2028年洛杉矶奥运会的奖牌榜预测结果以及较2024年变化的国家名称。请根据实际的数据和模型优化结果进行进一步分析。 第三个问题是:
你的模型应包括尚未获得奖牌的国家;你对这些国家在下一届奥运会中首次获得奖牌的数量有何预测?你对这一估计的胜率是多少?
这一问题要求你在模型中考虑到未获得奖牌的国家,并估计它们在2028年洛杉矶夏季奥运会中首次获得奖牌的数量以及做好这一预测的信心或胜率。 针对未获得奖牌的国家在2028年洛杉矶夏季奥运会中首次获得奖牌的预测模型,我们可以通过以下步骤进行建模和计算:
1. 数据筛选与准备
首先,从给定的数据集中筛选出自1896年以来尚未赢得奥运奖牌的国家。这些国家将在模型中重点考虑。
2. 统计分析
2.1 历史数据分析
对历届奥运会的奖牌数据进行统计分析,计算曾经未获奖的国家在未来奥运会中获得奖牌的概率。我们可以按照以下公式计算获奖概率:
获奖获奖总数P(获奖)=N获奖N总数
其中: - $N_{\text{获奖}}$ 是在过去所有奥运会中,曾经未获奖的国家获得奖牌的总数。 - $N_{\text{总数}}$ 是统计期内曾参与的未获奖国家的总数。
2.2 预测模型
使用一个简单的统计模型,比如基于二项分布来估算在下一届奥运会中首次获得奖牌的国家数量。假设有 $k$ 个未获奖国家,模型可以表示为:
获奖X∼Binomial(k,P(获奖))
其中 $X$ 代表在2028年洛杉矶夏季奥运会上未获奖的国家获得奖牌的数量。
3. 预测区间计算
根据二项分布的性质,我们可以计算出预计在2028年获得奖牌的国家数量的预测区间。假设我们希望计算出95%的置信区间,可以使用正态近似法计算:
获奖获奖获奖μ=k⋅P(获奖)σ=k⋅P(获奖)⋅(1−P(获奖))
然后利用正态分布为其构建95%置信区间:
CI=[μ−1.96⋅σk,μ+1.96⋅σk]
4. 结果解读与胜率评估
根据模型结果,我们可以得出在2028年首次获得奖牌的国家数量的预期和相应的置信区间。假设模型预测在2028年有 $X$ 个未获奖国家首次获得奖牌,那么我们可以通过以下方式评估我们的胜率:
胜率胜率=P(X≥1)=1−P(X=0)
在二项分布下:
获奖P(X=0)=(1−P(获奖))k
因此,我们的胜率表达为:
胜率获奖胜率=1−(1−P(获奖))k
5. 模型推测与应用
通过上述模型,我们实现了对尚未获得奖牌国家在2028年获得奖牌概率的量化评估,同时生成了相关的置信区间和胜率,帮助各国 Olympics 委员会作出更加数据驱动的决策,利用有效的资源分配方式,提高其在国际赛场上的竞争力。
这样一来,我们就可以基于历史数据和统计模型,科学地推测出未获得奖牌国家在未来奥运会中的表现。 在针对尚未获得奖牌的国家开展分析时,我们可以采取以下步骤来建模并预测它们在2028年洛杉矶夏季奥运会中首次获得奖牌的数量。
数据分析步骤
-
识别未获得奖牌的国家:从我们的数据集中,提取在过去所有夏季奥运会中未获得任何奖牌的国家/地区。
-
评估各国的奥林匹克表现指标:通过分析历史数据,可以设定一些因子来衡量一个国家获得奖牌的潜力,例如:
-
历史体育参与度(参赛人数、竞技水平)。
-
竞技体育基础设施(如训练场馆、资金支持等)。
-
国家对特定运动项目的重视程度(如国家体育计划、青训系统)。
-
建立预测模型:使用逻辑回归模型或贝叶斯统计来估计这些未获奖牌国家在2028年首次获得奖牌的机会。模型可以采用以下方式构建:
-
自变量:包括上述的绩效指标(例如,历史参与运动员数量、经济投资等)。
-
应变量:是否获得奖牌(0 = 未获得奖牌, 1 = 首次获得奖牌)。
-
预测初次获奖数量: 假设我们用逻辑回归模型得到的概率$p$表示某个未获奖国在2028年获得奖牌的概率。我们则可以用期望值来描述它们将获得的奖牌数量: E(N)=N×p 其中,$N$是未获得奖牌国家的数量,$E(N)$为我们预期的奖牌数量。
预测及信心评估
假设我们识别出12个未获奖牌国家,通过我们的模型分析,得出它们在2028年获得奖牌的概率为$p=0.15$(即15%的各国有可能在两年后首次获得奖牌)。则预计这些国家在洛杉矶未来将获得的奖牌数量为:
E(N)=12×0.15=1.8
这表示我们预测约有1-2个国家有可能在2028年洛杉矶奥运会中首次获得奖牌。
胜率评估
对于这一估计的胜率,我们可以以模型的准确性为基础进行反映。使用交叉验证方法来评估模型的表现,假设模型在训练数据上的准确率为80%($A=0.8$),则我们可以把对未来结果的信心定义为:
Confidence Rate=A×p=0.8×0.15=0.12(12%)
独特见解
-
全民参与度的重要性:未获奖牌国家往往受到资金支撑和参与度低的影响。若其能够增加青少年运动参与度和训练机会,将有效提升该国未来在奥运会中的表现。
-
运动专长的选择:各国应根据其优势,集中精力发展某些特定运动项目,尤其是少数国家在一些小众而竞争较小的项目中具备良好机会潜力,可能成为其获奖的突破口。
因此,综合考虑未获奖牌的国家特征和开展针对性支持,这些国家在2028年洛杉矶奥运会中首次获得奖牌的机会也将有所提升。 为了预测尚未获得奖牌的国家在2028年洛杉矶夏季奥运会中首次获得奖牌的数量,我们可以建立一个基于历史数据的统计模型。这个模型将考虑一些因素,如国家的体育基础、历史表现、赛事数量以及主办国的影响。以下是详细的分析步骤和模型构建过程:
1. 确定尚未获得奖牌的国家
首先,识别出尚未获得奖牌的国家列表。根据历史数据,我们能够筛选出这些国家。
2. 数据收集与处理
根据过往的奖牌获得情况和各国运动项目的表现数据,构建一个包含以下信息的数据集:
-
国家名称
-
参加的赛事数量
-
在各项运动中的参与情况
-
体育基础设施和发展水平的指标(如果可用)
3. 预测模型
我们可以使用回归模型来预测未获得奖牌的国家在2028年获得奖牌的概率和数量。模型的基本形式可以表示为:
Yi=β0+β1X1+β2X2+…+βnXn+ϵ
其中: - Y_i 是第 i 个国家在2028年获得的奖牌数量。 - X_1, X_2, \ldots, X_n 是影响奖牌获得的因素,如赛事数量、体育基础指标、对特定竞技项目的投资等等。 - \beta_0, \beta_1, \ldots, \beta_n 是模型参数。 - \epsilon 是随机误差。
4. 估计胜率
为了估计这些国家首次获得奖牌的胜率(概率),我们可以使用逻辑回归模型表示概率:
P(Yi>0|X)=11+e−(β0+β1X1+…+βnXn)
5. 结果分析
基于模型的输出,我们可以预测每个未获得奖牌国家在2028年洛杉矶奥运会中的奖牌数量和获取奖牌的概率。
6. 例子计算
假设通过模型估算,我们得到了某个国家的特征向量为 X = [x_1, x_2, \ldots, x_n],并通过回归得到了参数估计值 \hat{\beta} = [\hat{\beta_0}, \hat{\beta_1}, \ldots, \hat{\beta_n}]。
我们可以预测该国的奖牌数量和胜率:
-
计算期望的奖牌数量: Y^=β0^+β1^x1+β2^x2+…+βn^xn
-
计算获奖牌的概率: P(Y>0)=11+e−(β0^+β1^x1+…+βn^xn)
7. 结论
通过上述步骤,我们可以为每个尚未获得奖牌国提供具体的预测。在此基础上,选择一些国家并向其奥委会建议在相关运动项目中加大投入,以提高其在未来奥运会的表现。
此外,可以根据信心区间来评估预测的不确定性,借助经验数据和往届的表现历史,来总结出适合的模型进行精准预测。这样的分析和预测可以为各国提升竞技水平及获得奖牌的机会提供重要信息。 为了预测尚未获得奖牌的国家在2028年洛杉矶夏季奥运会中的首次奖牌数,我们可以使用朴素贝叶斯回归模型。这种模型基于历史数据来建立与获奖相关的概率。
我们将使用以下步骤进行预测:
-
确定尚未获得奖牌的国家。
-
分析这些国家在历史奥运会上的表现,包括参赛人数和比赛项目数量。
-
基于历史数据,估算这些国家在2028年获得首枚奖牌的概率。
-
进行 Monte Carlo 模拟,以创建奖牌数的分布和计算最终的预测值。
以下是完成以上步骤的Python示例代码:
import pandas as pd import numpy as np import random # 读取数据 athletes = pd.read_csv('summerOly_athletes.csv') medal_counts = pd.read_csv('summerOly_medal_counts.csv') # 确定尚未获得奖牌的国家 countries_with_no_medals = medal_counts[medal_counts['金牌'] == 0]['国家/地区'].unique() # 分析这些国家的参赛数据 unsuccessful_countries_data = athletes[athletes['国家/地区'].isin(countries_with_no_medals)] country_participation = unsuccessful_countries_data['国家/地区'].value_counts() # 进行概率估算 def estimate_first_medal_probability(country): # 使用历史数据进行估计,可以使用各国的参赛人数和以往获取奖牌的国家进行简单估算 previous_winners = medal_counts[medal_counts['总奖牌数'] > 0] prob_winning = previous_winners['总奖牌数'].sum() / len(previous_winners) participation_count = country_participation[country] # 假设每个参赛国家依据其参赛人数以及获取奖牌的比率来计算获得奖牌概率 return min(prob_winning * participation_count / 100, 1.0) # 归一化处理 # 估算每个国家获得首枚奖牌的概率 probability_results = {} for country in countries_with_no_medals: probability_results[country] = estimate_first_medal_probability(country) # 进行 Monte Carlo 模拟 def simulate_medal_winning(probabilities, num_simulations=10000): results = [] for _ in range(num_simulations): medal_count = sum(1 for prob in probabilities.values() if random.random() < prob) results.append(medal_count) return results simulation_results = simulate_medal_winning(probability_results) average_medal_count = np.mean(simulation_results) confidence_interval = np.percentile(simulation_results, [2.5, 97.5]) # 95%置信区间 print(f"预测在2028年洛杉矶奥运会上尚未获得奖牌的国家将获得的平均数量: {average_medal_count}") print(f"95% 置信区间: {confidence_interval}")
在这个示例中,我们首先读取了运动员和奖牌数据。接着,我们识别出未获得奖牌的国家,并分析他们的参赛数据。我们使用历史数据的奖牌数和参赛人数来估算每个国家获取奖牌的概率。最后,我们进行Monte Carlo模拟,计算预测的平均首枚奖牌数量和95%的置信区间。
Note: 在运行这段代码之前,需要确保导入数据文件并安装 pandas 和 numpy 库。模型可以根据具体需求进行调整和优化。 该段文字的第四个问题是:
“运动员可能会代表不同国家/地区参赛,但由于公民身份要求,他们改变代表国家并非易事。然而,教练可以轻松地从一个国家转移到另一个国家,因为他们不需要是该国公民即可执教。因此,可能存在‘优秀教练效应’。两个可能的例子包括郎平,她曾执教美国和中国的排球队并带领它们获得冠军,以及有时存在争议的体操教练贝拉·卡罗利,他曾在罗马尼亚和美国执教女子体操队并取得了巨大成功。检查数据,寻找可能因‘优秀教练效应’而产生的变化的证据。你估计这种效应对奖牌数的贡献有多大?选择三个国家,识别出他们应该考虑投资‘优秀’教练的运动项目,并估计这种影响。”
这个问题要求分析“优秀教练效应”对各国奖牌数的潜在影响,并评估在哪些运动项目上投资高水平教练可能会带来更好表现。
问题四:优秀教练效应分析
1. 定义“优秀教练效应”
“优秀教练效应”指的是高水平教练的影响对运动员表现和获奖能力的提升。该效应可以通过以下几个方面进行分析:
-
教练的经验和技能:高水平教练通常具备丰富的竞技经验和战术知识,能够帮助运动员提高技术和心理素质。
-
训练方法的优化:优秀教练会引入先进的训练技术和科学的方法,从而提高整个团队的整体实力。
-
运动员的动力和信心:教练的领导能够激发运动员的潜力,提高他们的动力和自信心,进而影响比赛表现。
2. 数据分析方法
为了量化“优秀教练效应”,我们可以采取以下几个步骤:
-
选择国家和项目:基于数据集中那些在2024年巴黎奥运会表现突出的国家和项目,选择三个国家,分别代表不同区域和项目。
-
数据集成:整合运动员数据与教练信息,识别在不同国家和项目中对奖牌数产生显著影响的优秀教练。
-
统计分析:
-
使用回归模型分析奖牌数($Medals$)与教练质量($CoachQuality$)之间的关系。模型可以设定为: Medalsi,j=β0+β1CoachQualityi,j+β2Eventsi,j+ϵi,j 其中,$Medals_{i,j}$为国家$i$在项目$j$的奖牌数,$Events_{i,j}$为该项目的比赛数量,$\epsilon$为随机误差。
-
效应估计:通过模型的拟合,得到$\beta_1$,它表明教练质量对奖牌数的边际影响。
3. 实证分析
此处放出部分内容~
小天会给大家带来所有题目完整思路+完整代码+完整论文全解全析
其中更详细的思路、各题目思路、代码、成品论文等,可以点击下方名片:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









