






1. 层次分析法介绍
1.1. 概述
层次分析法(Analytic Hierarchy Process,以下简称AHP)是一种对于定性的决策问题进行定量化分析的方法,常用于解决决策(评价类)问题。例如,高考志愿填报、旅游地点选择等等。
AHP是一种运筹学理论。特点是在对复杂决策问题的本质、影响因素及其内在关系等进行深入研究的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。是对难以完全定量的复杂系统做出决策的模型和方法。
1.2. 发展趋势
经过多年的研究与发展,AHP已经成为决策者广泛使用的一种多准则方法。
其应用涉及经济与计划,能源政策与资源分配、政治问题及冲突、人力资源管理、预测、项目评价、教育发展、环境工程、企业管理与生产经营决策、会计、卫生保健、军事指挥、武器评价、法律等众多领域。
AHP主要作为一种辅助决策工具,常与其他方法有机结合。常见的其他方法有模糊集理论、模糊逻辑、数字规划、成本收益分析、人工神经网络、证据推理、数据包络分析、仿真、数据挖掘等。
1.3. 优缺点
1.3.1. 优点
- 系统性:将对象视为系统,按照分解、比较、判断、综合的思维方式进行决策。清楚地呈现各层、各准则与各要素的关系。
- 实用性:定性与定量结合,能处理许多用传统的最优化技术无法着手的实际问题,应用范围很广。
- 简洁性:计算简便,结果明确,便于决策者直接了解和掌握。
1.3.2. 缺点
- 局限:只能从固有的方案中优选一个,无法产生新方案。
- 粗略:判断及结果的计算过程是粗糙的,不适用精度高的问题。
- 主观:成对比较矩阵中,人的主观因素对整个过程影响很大,可通过组织专家群体判断,克服该缺点。
2. 层次分析法应用步骤
2.1. 建立层次结构模型
将决策的目标、考虑的因素和决策对象按相互关系分成最高层、中间层和最低层。
最高层为目标层,通常只有一个因素,最低层为方案层或对象层,中间层可以有一个或多个层次,为准则层或指标层,当准则过多时(大于9个)应进一步分解出子准则层。
2.2. 构造成对比较矩阵
含义
为了量化两两比较的结果,使用成对比较矩阵进行相应的评价。
数学概念
成对比较矩阵
表示该层所有因素对于上层某个因素的相对重要性的比较。
若一个矩阵中,n个元素彼此两两比较,满足以下性质,则称该矩阵为成对比较矩阵。
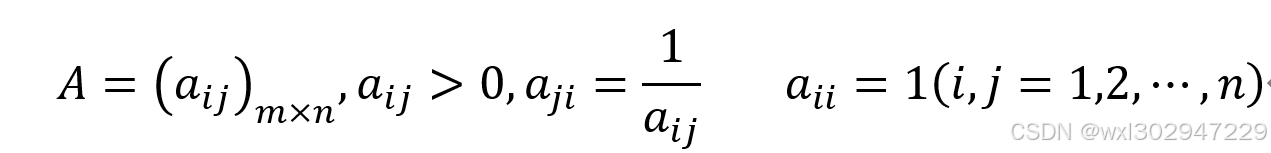
一致性成对比较矩阵
若一个成对比较矩阵,满足以下性质,则称为一致性矩阵,简称一致阵。
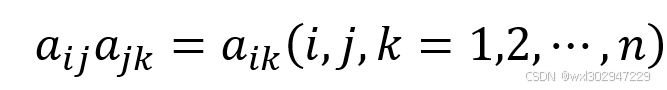
权向量
成对比较矩阵的最大特征根λ_max对应的特征向量w ⃗=(w_1,w_2,⋯,w_n )^T为权向量,即满足以下性质:
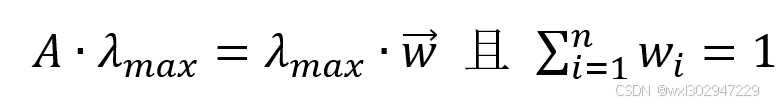
权重计算法
- 算数平均法
Step1:列归一化,即将列中每个元素除以该列所有元素之和。
Step2:行平均值,即将列归一化后的结果统计每行的平均值。
- 几何平均法
Step1:行相乘,开n方,即将每行的元素相乘然后开n次方。
Step2:归一化,即将开方后的结果进行归一化。
- 特征值法
实际场景中应用最多的方法。
Step1:特征向量,即求最大特征值对应的特征向量。
Step2:归一化,即将特征向量进行归一化处理。
一致性指标CI
成对比较矩阵的不一致程度,可以用λ_max-n的大小来衡量,对应的一致性指标计算方式为:
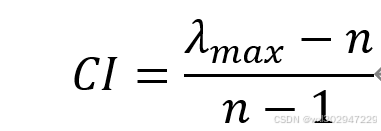
若为一致阵,则一致性指标CI等于零。
Saaty标度法
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有相同重要性 |
| 3 | 表示两个因素相比,前者比后者稍重要 |
| 5 | 表示两个因素相比,前者比后者明显重要 |
| 7 | 表示两个因素相比,前者比后者强烈重要 |
| 9 | 表示两个因素相比,前者比后者极端重要 |
| 2,4,6,8 | 表示上述相邻判断的中间值 |
| 倒数 | 若因素i与因素j的重要性之比为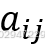 ,那么因素j与因素i重要性之比为 ,那么因素j与因素i重要性之比为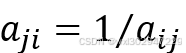 |
2.3. 层次单排序及其一致性检验
含义
该层因素对于上层某个因素的相对重要性的排序权重,这一过程称为层次单排序。
数学概念
平均随机一致性指标
通过随机构建1000个正互反矩阵,计算一致性指标的平均值得出。
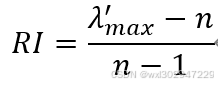
对于n阶成对比较矩阵,其平均随机一致性指标参考下表:
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.52 | 0.89 | 1.12 | 1.26 | 1.36 | 1.41 | 1.46 | 1.49 | 1.51 |
一致性检验
一致性指标与平均随机一致性指标的比值称为一致性比率CR,当一致性比率CR小于0.1时,通过一致性检验,否则,不通过。
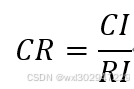
2.4. 层次总排序及其一致性检验
方案层对于目标层的相对重要性的权值,称为层次总排序。
2.5. 实例分析
选择旅游地,有北京、上海、南京三个目的地可供选择,根据景色、费用、住宿、饮食、交通五个准则进行判断。利用AHP进行分析,如下:
建立层次结构模型
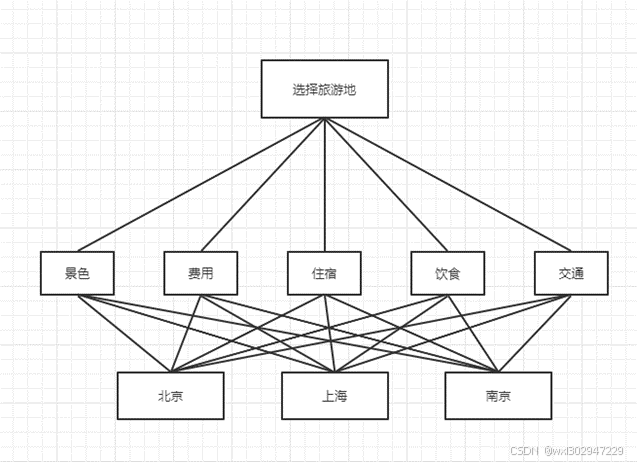
构造成对比较矩阵
| 选择旅游地 | 景色 | 费用 | 住宿 | 饮食 | 交通 |
|---|---|---|---|---|---|
| 景色 | 1 | 1/2 | 4 | 3 | 3 |
| 费用 | 2 | 1 | 7 | 5 | 5 |
| 住宿 | 1/4 | 1/7 | 1 | 1/2 | 1/3 |
| 饮食 | 1/3 | 1/5 | 2 | 1 | 1 |
| 交通 | 1/3 | 1/5 | 3 | 1 | 1 |
| 景色 | 北京 | 上海 | 南京 |
|---|---|---|---|
| 北京 | 1 | 3 | 5 |
| 上海 | 1/3 | 1 | 2 |
| 南京 | 1/5 | 1/2 | 1 |
| 费用 | 北京 | 上海 | 南京 |
|---|---|---|---|
| 北京 | 1 | 1/3 | 1/8 |
| 上海 | 3 | 1 | 1/3 |
| 南京 | 8 | 3 | 1 |
| 住宿 | 北京 | 上海 | 南京 |
|---|---|---|---|
| 北京 | 1 | 2 | 4 |
| 上海 | 1/2 | 1 | 3 |
| 南京 | 1/4 | 1/3 | 1 |
| 饮食 | 北京 | 上海 | 南京 |
|---|---|---|---|
| 北京 | 1 | 3 | 5 |
| 上海 | 1/3 | 1 | 3 |
| 南京 | 1/5 | 1/3 | 1 |
| 交通 | 北京 | 上海 | 南京 |
|---|---|---|---|
| 北京 | 1 | 2 | 1/4 |
| 上海 | 1/2 | 1 | 1/6 |
| 南京 | 4 | 6 | 1 |
层次单排序及其一致性检验
采用特征值法,求得各矩阵的各参数值如下:
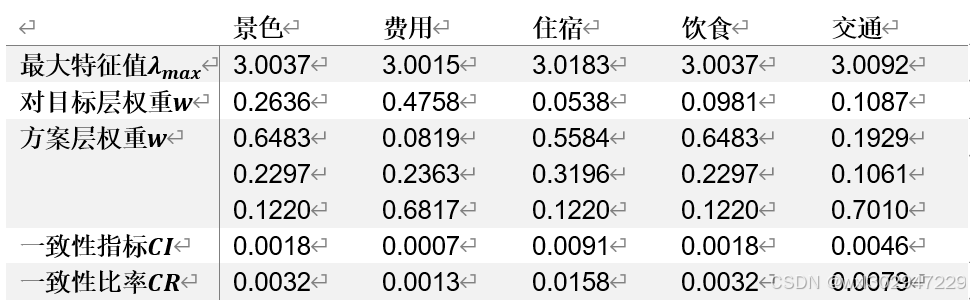
从上述数据得出,所有的一致性比率均小于0.1,所以通过一致性检验。
层次总排序及其一致性检验
计算层次总排序:

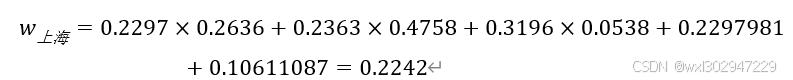
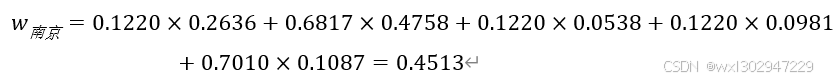
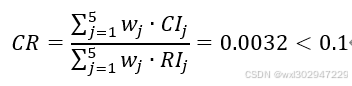
层次总排序一致性比率小于0.1,一致性检验通过,通过方案层权重比较,得出南京权重最大,所以最终选择南京。
3. 程序实现思路
3.1. 层次结构模型及成对比较矩阵
由用户构建,后端根据用户构建信息,采用JSON数据结构方式记录。
{
"target": "选择旅游地", // 目标层
"criterions": [ // 准则层
[
"景色",
"费用",
"居住",
"饮食",
"交通"
]
],
"measures": [
"北京",
"上海",
"南京"
], // 方案层
"选择旅游地": [
[
1,
0.5,
4,
3,
3
],
[
2,
1,
7,
5,
5
],
[
0.25,
0.1428571428571429,
1,
0.5,
0.3333333333333333
],
[
0.3333333333333333,
0.2,
2,
1,
1
],
[
0.3333333333333333,
0.2,
3,
1,
1
]
],
"景色": [
[
1,
3,
5
],
[
0.3333333333333333,
1,
2
],
[
0.2,
0.5,
1
]
],
"费用": [
[
1,
0.3333333333333333,
0.125
],
[
3,
1,
0.3333333333333333
],
[
8,
3,
1
]
],
"居住": [
[
1,
2,
4
],
[
0.5,
1,
3
],
[
0.25,
0.3333333333333333,
1
]
],
"饮食": [
[
1,
3,
5
],
[
0.3333333333333333,
1,
2
],
[
0.2,
0.5,
1
]
],
"交通": [
[
1,
2,
0.25
],
[
0.5,
1,
0.1666666666666667
],
[
4,
6,
1
]
]
}
读取JSON中的成对比较矩阵信息,计算矩阵中各要素的值,因为涉及到数学算法,所以采用开源扩展组件ujmp。
ujmp是一个提供各种矩阵运算的Java类库。这个工具包提供了诸如稀疏矩阵和稠密矩阵的实现,以及矩阵的分解、求逆、加法、乘法,均值,方差和相关系数等运算功能。此外还提供一些常用的线性代数运算功能,矩阵可视化功能和矩阵数据导入与导出的功能。
public static AHPAnalysisResult calculateMatrix(Matrix matrix) {
AHPAnalysisResult result = new AHPAnalysisResult();
// 矩阵的特征向量与特征值 0为特征向量,1为特征值
Matrix[] eig = matrix.eig();
// 矩阵的最大特征值
Matrix eigenvalue = eig[1];
Double eigMax = eigenvalue.abs(Calculation.Ret.NEW).getMaxValue();
result.setMaxEigenvalue(eigMax);
long maxIndex;
long columnCount = eigenvalue.getColumnCount();
for (maxIndex = 0; maxIndex < columnCount; maxIndex++) {
Matrix colMatrix = eigenvalue.selectColumns(Calculation.Ret.LINK, maxIndex);
if (colMatrix.containsDouble(eigMax)) {
break;
}
}
// 矩阵的特征向量
Matrix eigenvector = eig[0];
// 最大特征值的特征向量归一化
Matrix colMatrix = eigenvector.selectColumns(Calculation.Ret.NEW, maxIndex);
result.setEigenvector(colMatrix.toColumnVector(Calculation.Ret.LINK).toDoubleArray()[0]);
Matrix normalizedColumn = AHPUtil.normalizedColumn(colMatrix);
result.setWeight(normalizedColumn.toColumnVector(Calculation.Ret.LINK).abs(Calculation.Ret.NEW).toDoubleArray()[0]);
// CI
double ci = (eigMax - columnCount) / (columnCount - 1);
ci = ci <= 0 ? 0 : ci;
result.setCi(new BigDecimal(ci + "").doubleValue());
// RI
double ri = RI_STANDARD[(int) (columnCount - 1)];
result.setRi(ri);
// CR
double cr = ri != 0 ? ci / ri : 0;
result.setCr(new BigDecimal(cr + "").doubleValue());
if (cr > CR_CRITICAL_VALUE) {
throw new RuntimeException("层次单排序一致性检验未通过");
}
return result;
}
3.2. 层次单排序及其一致性检验
当进行成对比较矩阵运算时,同步进行层次单排序的允许及其一致性检验,当一致性检验未通过时,程序抛出异常。
3.3. 层次总排序及其一致性检验
层次单排序一致性检验通过后,从最上层准则层开始,向下依次计算每一层次各因素对目标层的权重,直到计算至方案层,得出方案层各因素对目标层的权重,并在过程中,依次累计计算各层次的一致性比率,最终在方案层的计算中,累加得到层次总排序的一致性比率,并判断是否通过一致性检验。
若通过一致性检验,则根据方案层各因素对目标层的权重,取其最大值对应的因素为最优解。
public static Map<String, Object> calcTotalOrdering(String[] measure, LevelCalcResult calcResult, MatrixMetaData metaData) {
Map<String, Object> map = MapUtil.newHashMap();
double[][] measureWeight = transpositionWeight(metaData.getWeight());
double[] calcWeight = calcResult.getWeight();
double max = 0;
String maxTitle = "";
for (int i = 0; i < measureWeight.length; i++) {
double[] colWeight = measureWeight[i];
double calcMeasureWeight = 0;
for (int j = 0; j < colWeight.length; j++) {
calcMeasureWeight += colWeight[j] * calcWeight[j];
}
max = Math.max(max, calcMeasureWeight);
maxTitle = calcMeasureWeight == max ? measure[i] : maxTitle;
map.put(measure[i], calcMeasureWeight);
}
map.put(OPTIMAL_SOLUTION, maxTitle);
double ci = 0;
double ri = 0;
double[] measureCi = metaData.getCi();
double[] measureRi = metaData.getRi();
for (int i = 0; i < measureCi.length; i++) {
ci += calcResult.getCi() * measureCi[i];
ri += calcResult.getRi() * measureRi[i];
}
double cr = (ri != 0 ? ci / ri : 0) + calcResult.getCr();
if (cr > CR_CRITICAL_VALUE) {
throw new RuntimeException("层次总排序一致性检验未通过");
}
map.put(CR, cr);
return map;
}
4. 程序测试验证
市政部门管理人员需要对修建一项市政工程项目进行决策,可选择的方案是修建通往旅游区的高速路(简称建高速路)或修建城区地铁(简称建地铁)。除了考虑经济效益外,还要考虑社会效益、环境效益等因素,即是多准则决策问题,试运用层次分析法建模解决。
建立层次结构模型
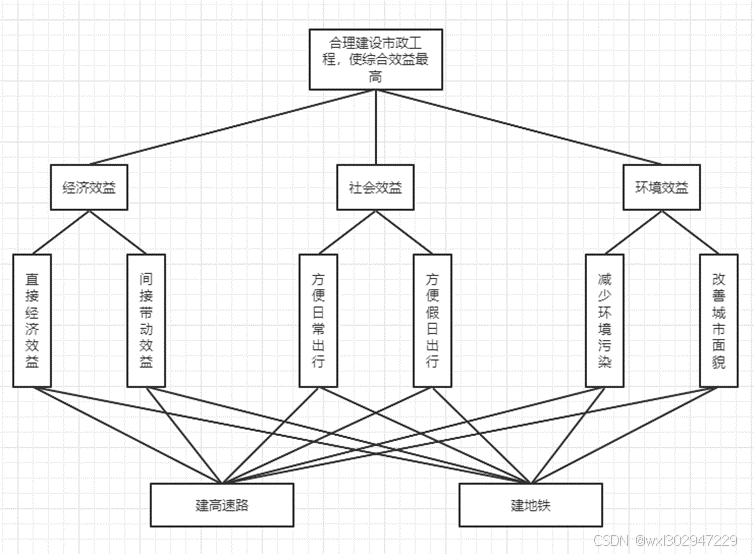
构造成对比较矩阵
| 合理建设市政工程,使综合效益最高 | 经济效益 | 社会效益 | 环境效益 |
|---|---|---|---|
| 经济效益 | 1 | 1/3 | 1/3 |
| 社会效益 | 3 | 1 | 1 |
| 环境效益 | 3 | 1 | 1 |
| 经济效益 | 直接经济效益 | 间接带动效益 |
|---|---|---|
| 经济效益 | 1 | 1 |
| 社会效益 | 1 | 1 |
| 社会效益 | 方便日常出行 | 方便假日出行 |
|---|---|---|
| 方便日常出行 | 1 | 3 |
| 方便假日出行 | 1/3 | 1 |
| 环境效益 | 减少环境污染 | 改善城市面貌 |
|---|---|---|
| 减少环境污染 | 1 | 3 |
| 改善城市面貌 | 1/3 | 1 |
| 直接经济效益 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 5 |
| 建地铁 | 1/5 | 1 |
| 间接带动效益 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 3 |
| 建地铁 | 1/3 | 1 |
| 方便日常出行 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 1/5 |
| 建地铁 | 5 | 1 |
| 方便假日出行 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 7 |
| 建地铁 | 1/7 | 1 |
| 减少环境污染 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 1/5 |
| 建地铁 | 5 | 1 |
| 改善城市面貌 | 建高速路 | 建地铁 |
|---|---|---|
| 建高速路 | 1 | 1/3 |
| 建地铁 | 3 | 1 |
生成JSON数据结构
{
"target": "合理建设市政工程,使综合效益最高",
"criterions": [
["经济效益", "社会效益", "环境效益"],
["直接经济效益", "间接带动效益", "方便日常出行", "方便假日出行", "减少环境污染", "改善城市面貌"]
],
"measures": [ "建高速路", "建地铁" ],
"合理建设市政工程,使综合效益最高": [
[1, 0.3333333333333333, 0.3333333333333333],
[3, 1, 1],
[3, 1, 1]
],
"经济效益": [
[1, 1, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]
],
"社会效益": [
[1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 1, 3, 0, 0],
[0, 0, 0.3333333333333333, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]
],
"环境效益": [
[1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 3],
[0, 0, 0, 0, 0.3333333333333333, 1]
],
"直接经济效益": [
[1, 5],
[0.2, 1]
],
"间接带动效益": [
[1, 3],
[0.3333333333333333, 1]
],
"方便日常出行": [
[1, 0.2],
[5, 1]
],
"方便假日出行": [
[1, 7],
[0.1428571428571429, 1]
],
"减少环境污染":[
[1, 0.2],
[5, 1]
],
"改善城市面貌": [
[1, 0.3333333333333333],
[3, 1]
]
}
计算层次单排序、总排序及其一致性检验
执行程序计算,得到相关输出内容。
=====================合理建设市政工程,使综合效益最高===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.58, 检验系数(CR):0, 最大特征值:3.0, 最大特征值对应特征向量:[0.3685138655950445, 1.105541596785133, 1.1055415967851332], 权向量(特征向量归一化):[0.1428571428571429, 0.42857142857142855, 0.4285714285714286]]
=====================经济效益===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):1.24, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.7071067811865475, 0.7071067811865475, 0.0, 0.0, 0.0, 0.0], 权向量(特征向量归一化):[0.5, 0.5, 0.0, 0.0, 0.0, 0.0]]
=====================社会效益===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):1.24, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.0, 0.0, 0.9486832980505138, 0.31622776601683794, 0.0, 0.0], 权向量(特征向量归一化):[0.0, 0.0, 0.75, 0.25, 0.0, 0.0]]
=====================环境效益===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):1.24, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.0, 0.0, 0.0, 0.0, 0.9486832980505138, 0.31622776601683794], 权向量(特征向量归一化):[0.0, 0.0, 0.0, 0.0, 0.75, 0.25]]
=====================直接经济效益===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.9805806756909202, 0.19611613513818404], 权向量(特征向量归一化):[0.8333333333333334, 0.16666666666666666]]
=====================间接带动效益===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.9486832980505138, 0.31622776601683794], 权向量(特征向量归一化):[0.75, 0.25]]
=====================方便日常出行===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.19611613513818402, 0.9805806756909202], 权向量(特征向量归一化):[0.16666666666666663, 0.8333333333333334]]
=====================方便假日出行===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.9899494936611665, 0.14142135623730953], 权向量(特征向量归一化):[0.875, 0.12500000000000003]]
=====================减少环境污染===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.19611613513818402, 0.9805806756909202], 权向量(特征向量归一化):[0.16666666666666663, 0.8333333333333334]]
=====================改善城市面貌===================
AHPAnalysisResult[一致性指标(CI):0, 平均随机一致性指标(RI):0.0, 检验系数(CR):0, 最大特征值:2.0, 最大特征值对应特征向量:[0.31622776601683794, 0.9486832980505138], 权向量(特征向量归一化):[0.25, 0.75]]
对输出内容格式化后如下:
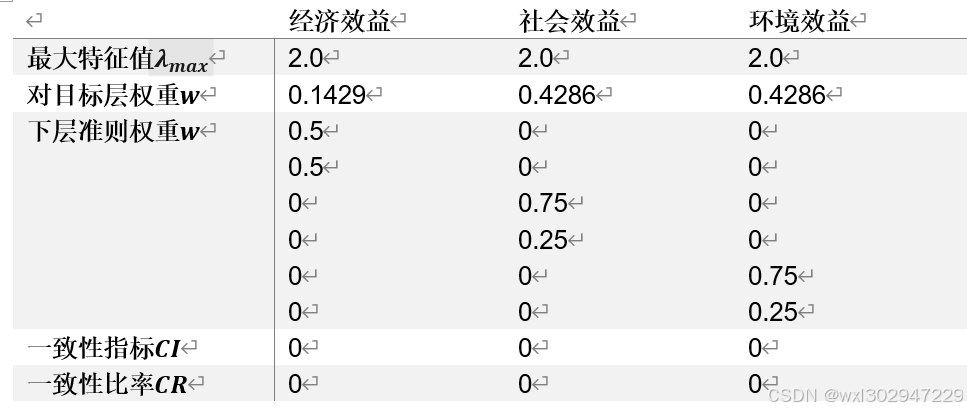
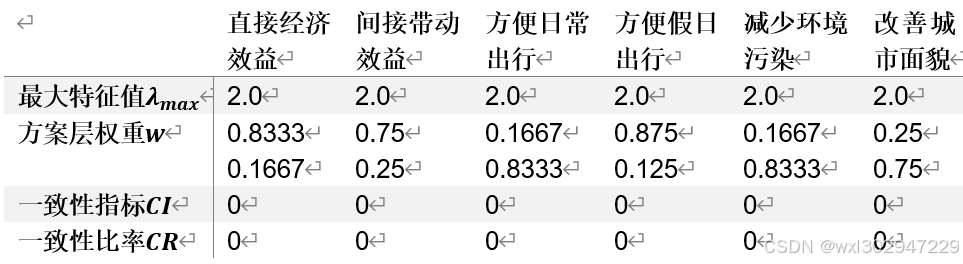
层次总排序一致性比率CR=0,一致性检验通过。
得出最优解
最终计算输出为:
{建地铁=0.6592261904761906, 最优解=建地铁, 建高速路=0.34077380952380953, CR=0.0}
经层次分析法程序计算,最适合的方案为建地铁。
应用场景
未来项目中若存在需用户决策,或存在评价体系的模块,可以使用层次分析算法,通过一系列的数据计算,帮助用户计算不同方案对总体目标的权重,为用户的最终选择提供理论依据。
例如,用户需采购部分零件,但同时有多家供应商满足要求,这时,可以通过建立物流、价格、售后等等准则,在项目中,通过多途径的数据判断,及逻辑算法生成成对比较矩阵,并进行判断,最终,给出用户最优的选择,并提供数据支撑。
代码下载链接:
https://download.csdn.net/download/wxl302947229/89734109


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











