






目标网页链接:[http://www.xmccb.com/changpinjieshaohh/index.html]
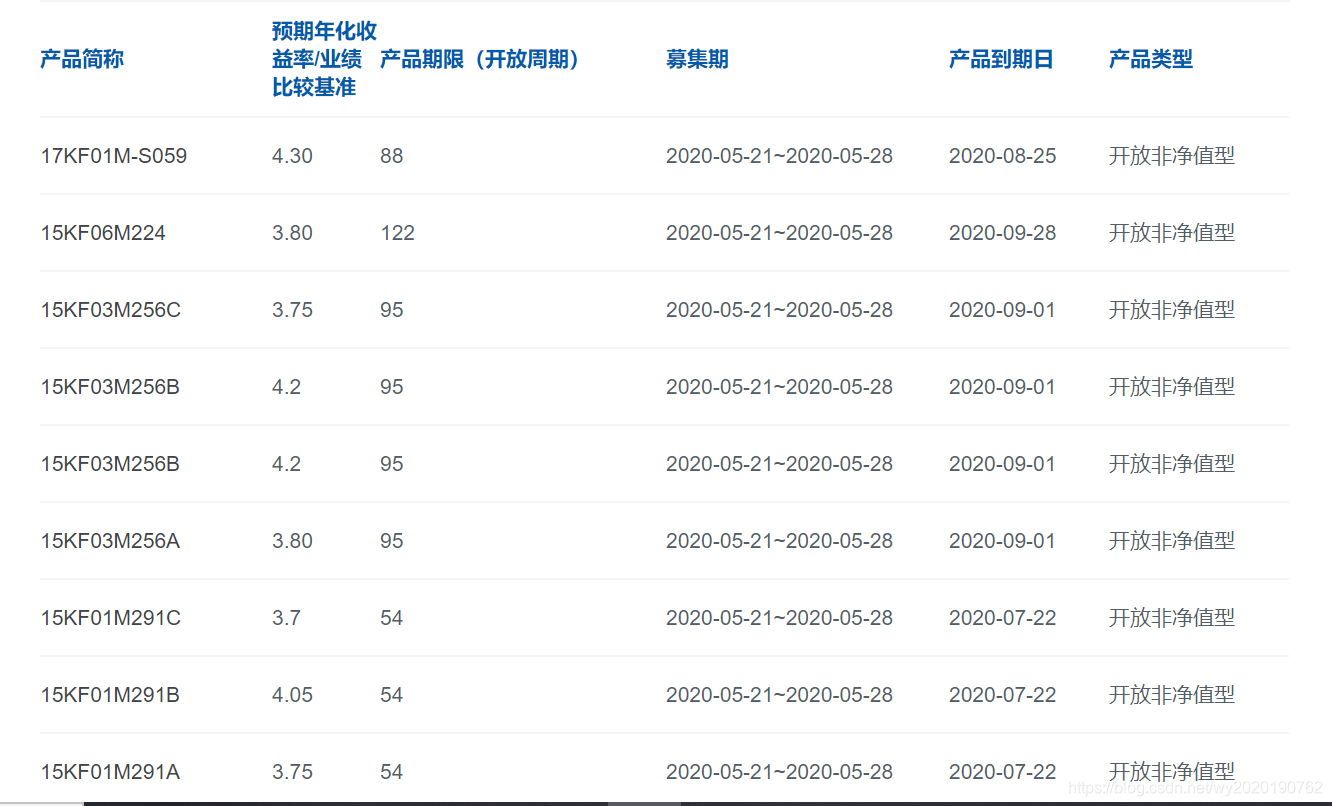
1.查看网页源代码
在目标网页右击检查,查看网页源代码,目标表格源代码如下:
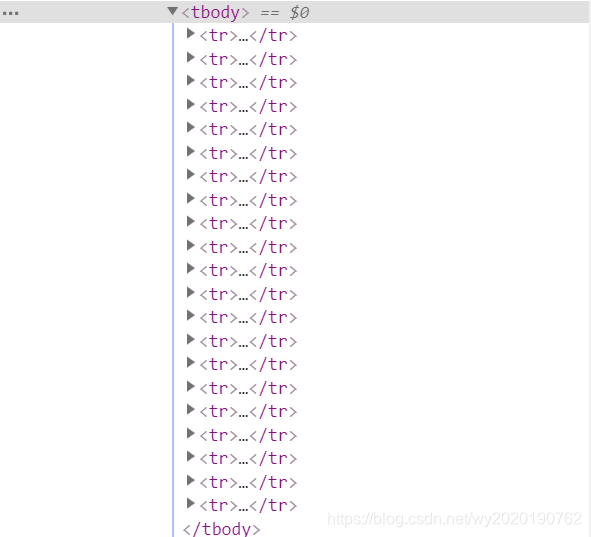
*拓展:
tr、td属于HTML语言标签,成对出现,含义如下:
1、tr 标签 ,代表HTML表格中的一行
2、td 标签 , 代表HTML表格中的一个单元格
2.代码分块详解
(1)导入库
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
Requests库获取网页内容
re库利用正则表达式实现字符串的检索、替换、匹配等操作(正则表达式还需学习)
BeautifulSoup库从Html文件中提取数据
pandas库将获取的数据写入文件
(2)对首页的爬取
通过观察目标网页102页的网址,存在以下规律:
第1页(即首页)网址:http://www.xmccb.com/changpinjieshaohh/index.html
第2页网址:
http://www.xmccb.com/changpinjieshaohh/index_2.html
第3页网址:
http://www.xmccb.com/changpinjieshaohh/index_3.html
…
第102页网址
http://www.xmccb.com/changpinjieshaohh/index_102.html
可以看出,从第二页开始,均在index_后加上页码对应的数字,可通过一个循环爬取2-102的数据,但是第一页后并不是1,故对首页分开处理(能否有统一处理的方式??)
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
#问题1:由于第一页的html不含page,单独运行,可否改进?
link = 'http://www.xmccb.com/changpinjieshaohh/index.html'
start_html = requests.get(link, headers=headers)
start_html.encoding = 'utf-8' #防止中文乱码
print("第1页响应状态码:", start_html.status_code)
soup = BeautifulSoup(start_html.text, 'lxml')
product = soup.find_all('tr')[6:27] #soup中find_all方法寻找源代码中的“tr”,目标网页有两个表格,只需定位到第二个表格即可,故选取第6-26
# print(product)
product_list = []
for row in product: #在每个“tr”中循环找寻“td”
productname = row.find_all('td')[0].contents
productname = str(productname)
# print(type(productname1))
product_name = re.findall(r'>(.*)<', productname)
# print(type(productname2))
product_name = str(product_name)[2:-2]
# product_name = productname[2:-2]
# print(product_name)
yieldrate = str(row.find_all('td')[1].contents)[2:-2]
productdeadline = str(row.find_all('td')[2].contents)[2:-2]
timerange = str(row.find_all('td')[3].contents)[2:-2]
deadline = str(row.find_all('td')[4].contents)[2:-2]
producttype = str(row.find_all('td')[5].contents)[2:-2]
product_list.append({'产品简称':product_name,'预期年化收益率/业绩比较基准':yieldrate,'产品期限(开放周期)':productdeadline,'募集期':timerange,'产品到期日':deadline,'产品类型':producttype})
请求头Headers提供了关于请求、响应或其他发送实体的信息。对于爬虫而言,请求头十分重要,如果没有指定请求头或请求的请求头和实际网页不一致,就可能无法返回正确的结果。
那么,我们如何找到正确的Headers呢?使用Chrome浏览器打开要请求的网页,右击网页任意位置,在弹出的快捷菜单中单击“检查”命令,如图所示,在打开的页面中单击Network选项。
如下图所示,在左侧的资源中找到需要请求的网页,单击该网页,在右侧就可以看到Headers的详细信息。
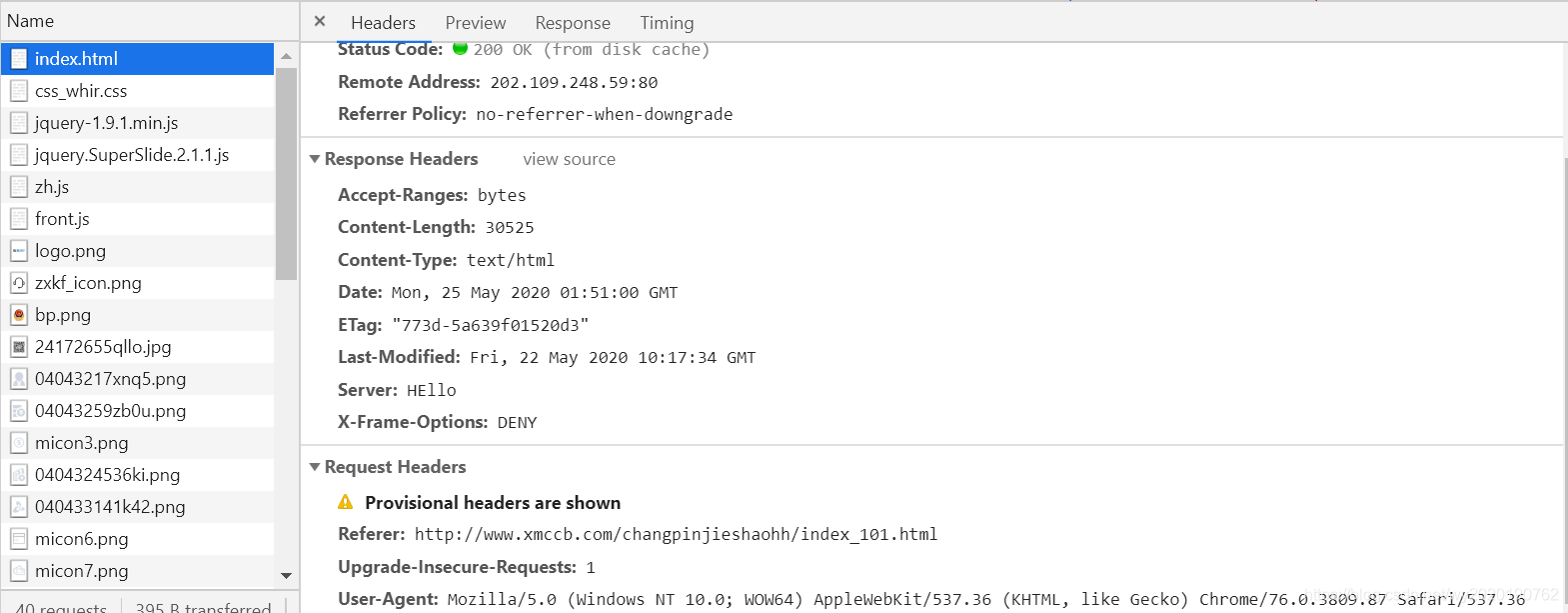
因此,我们可以看到请求头的信息为:
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36
Requests请求访问该网址,并输出响应状态码(status_code),如果返回200,就表示请求成功了;如果返回的是4××,就表示客户端错误;返回5××则表示服务器错误响应。
将代码转换成BeautifulSoup对象:
soup = BeautifulSoup(start_html.text, 'lxml')
这里使用的解析器为“lxml HTML解析器”。
扩展:
print(soup.prettify()) #对代码进行美化
循环语句在每个“tr”里找寻“td”,其中,第一个“td”所对应的产品简称,第二个为预期年化收益率,第三个为产品期限,第四个为募集期,第五个为产品到期日,第六个为产品类型,依次读取到对应的变量中,并保存在列表中。可用正则表达式和字符串的提取规则提取输出内容中我们想要的部分字符串。
(3)对2-102页数据的爬取
这部分的爬取与对首页数据的爬取没有本质区别,只是通过对网址中数字的不同赋值改变所要请求的网址,实现对多个网址内容的依次爬取。
for i in range(2,103):
pack_link = 'http://www.xmccb.com/changpinjieshaohh/index_'+str(i)+'.html'
page_html = requests.get(pack_link, headers=headers,timeout=10)
page_html.encoding = 'utf-8'
print(str(i), "页码响应状态码:", page_html.status_code)
soup = BeautifulSoup(page_html.text, 'lxml')
product = soup.find_all('tr')[6:27]
for row in product:
productname = row.find_all('td')[0].contents
productname = str(productname)
product_name = re.findall(r'>(.*)<', productname)
product_name = str(product_name)[2:-2]
yieldrate = str(row.find_all('td')[1].contents)[2:-2]
productdeadline = str(row.find_all('td')[2].contents)[2:-2]
timerange = str(row.find_all('td')[3].contents)[2:-2]
deadline = str(row.find_all('td')[4].contents)[2:-2]
producttype = str(row.find_all('td')[5].contents)[2:-2]
product_list.append(
{'产品简称': product_name, '预期年化收益率/业绩比较基准': yieldrate, '产品期限(开放周期)': productdeadline, '募集期': timerange,
'产品到期日': deadline, '产品类型': producttype})
3.完整代码
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
#问题1:由于第一页的html不含page,单独运行,可否改进?
link = 'http://www.xmccb.com/changpinjieshaohh/index.html'
start_html = requests.get(link, headers=headers)
start_html.encoding = 'utf-8'
print("第1页响应状态码:", start_html.status_code)
soup = BeautifulSoup(start_html.text, 'lxml')
product = soup.find_all('tr')[6:27]
# print(product)
product_list = []
for row in product:
productname = row.find_all('td')[0].contents
productname = str(productname)
# print(type(productname1))
product_name = re.findall(r'>(.*)<', productname)
# print(type(productname2))
product_name = str(product_name)[2:-2]
# product_name = productname[2:-2]
# print(product_name)
yieldrate = str(row.find_all('td')[1].contents)[2:-2]
productdeadline = str(row.find_all('td')[2].contents)[2:-2]
timerange = str(row.find_all('td')[3].contents)[2:-2]
deadline = str(row.find_all('td')[4].contents)[2:-2]
producttype = str(row.find_all('td')[5].contents)[2:-2]
product_list.append({'产品简称':product_name,'预期年化收益率/业绩比较基准':yieldrate,'产品期限(开放周期)':productdeadline,'募集期':timerange,'产品到期日':deadline,'产品类型':producttype})
for i in range(2,103):
pack_link = 'http://www.xmccb.com/changpinjieshaohh/index_'+str(i)+'.html'
page_html = requests.get(pack_link, headers=headers,timeout=10)
page_html.encoding = 'utf-8'
print(str(i), "页码响应状态码:", page_html.status_code)
soup = BeautifulSoup(page_html.text, 'lxml')
product = soup.find_all('tr')[6:27]
for row in product:
productname = row.find_all('td')[0].contents
productname = str(productname)
product_name = re.findall(r'>(.*)<', productname)
product_name = str(product_name)[2:-2]
yieldrate = str(row.find_all('td')[1].contents)[2:-2]
productdeadline = str(row.find_all('td')[2].contents)[2:-2]
timerange = str(row.find_all('td')[3].contents)[2:-2]
deadline = str(row.find_all('td')[4].contents)[2:-2]
producttype = str(row.find_all('td')[5].contents)[2:-2]
product_list.append(
{'产品简称': product_name, '预期年化收益率/业绩比较基准': yieldrate, '产品期限(开放周期)': productdeadline, '募集期': timerange,
'产品到期日': deadline, '产品类型': producttype})
# print(product_list)
df = pd.DataFrame(product_list)
# print(df)
columns = ['产品简称','预期年化收益率/业绩比较基准','产品期限(开放周期)','募集期','产品到期日','产品类型']
df.to_csv('G:/网络爬虫/静态网页爬取-厦门银行/result.csv', encoding='utf-8',columns=columns) #写入到csv中

















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









