







概念,定义
后缀树是一种树型数据结构,使用后缀树可以快速解决很多字符串相关的问题,功能非常强大。很多文章在说到后缀树时,都会首先提及Tries树。实际上Tries是一种简单版本的后缀树,后缀树也可以说是压缩后的Tries树。总而言之,Tries树和后缀树有很多相似之处,后缀树在时间效率和空间效率都比Tries树要好,不过后缀树相应的就很难理解。很多介绍后缀树的文章都难免让初学者陷入混乱。
字符串的后缀
比如字串S:hello,它的后缀包括:
hello, ello, llo, lo, o, $(空串)
更一般的定义:如果S=t1t2...ti...tn是一个字串, 那么Ti=titi+1...tn是S的起始于i的后缀。例如:
T1 = hello = S
T2 = ello
T3 = llo
T4 = lo
T5 = o
T6 = $
类似的我们可以得到S的前缀:$, h, he, hel, hell, hello。注意,S的子串是一个后缀的前缀,是一个前缀的后缀。比如ell是S的一个子串,它是后缀T2的前缀,是前缀hell的后缀。
suffix Trie与suffix Tree
对于S:bananas
它的后缀Trie和后缀树分别如下所示:
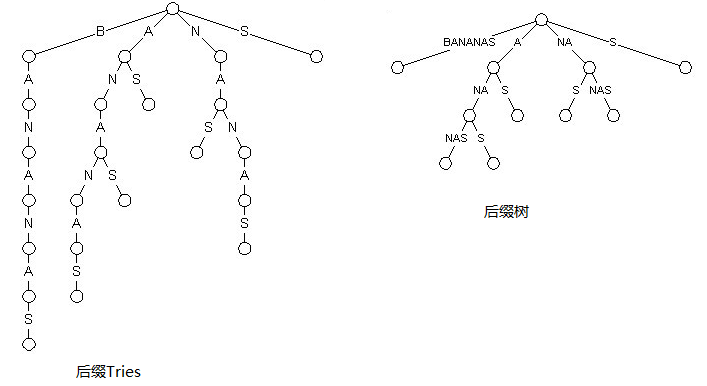
现在来理解它们的区别还比较困难。总结而言可以概括为:后缀树要比后缀Tries省空间,后缀Tries构造比较直接简单,时间复杂度为O(n2),而且空间复杂度也是O(n2)。后缀树的构造很复杂,不容易理解,不过它的时间复杂度和空间复杂度都为O(n)。
后缀Tries没有家喻户晓的原因正是因为它的平方级开销,这使得它在最需要它的领域 -- 长串搜索中被拒之门外。
可以用下面的结构来表示Tries
class Edge {
char ch ; //边代表的字符
Node *node ; //边指向的点
};
class Node {
Edge *first ; //以该节点出发的第一条边
Edge *next ; //下一条边
bool isEnd ; //以该节点结尾的字串是否存在
};
class Node {
char ch ; //该节点代表的字符
Node *child ; //第一个子节点
Node *sibling ; //兄弟节点
bool isEndl ; //以该节点结尾的字串是否存在
};
suffix link(后缀链接)
也叫后缀指针,它指示下一个更短的后缀。即,如果一个后缀表示文本的第0到第n个字符,那么它的后缀指针指向的节点表示文本的第1个到第n个字符。
它的存在有什么好处呢?有了后缀指针,我们就可以方便的从一个后缀跳到另一个后缀,这是使后缀树的构造算法降为O(n)的保证。
后缀树的特性
后缀树通过自身的特性去解决一些复杂的匹配问题。
经过证明,在最坏的情况下,后缀树的节点数也不会超过2N。
前缀相同的后缀共享同样的边
后缀指针指向下一个更短的后缀
问题来源
字符串匹配是程序员经常要面对的问题。字符串匹配算法的改进可以使很多工程受益良多,比如数据压缩和DNA排列。O(n2)的传统匹配算法在面对长字串时无能为力,后来出现了很多改进的算法,比如KMP,Boyer-Moore算法等使复杂度降低O(N+M),效率大大改进。在基因工程的应用中,通常都需要频繁在基因库中定位一个基因数据,对于一个大型的基因库,显然O(N+M)的算法仍然无法满足需要。后缀Tries亮出了O(M)的底牌,彻底鄙视了其它算法的成绩,后缀Tries对比的次数仅仅相当于被搜索串的长度!
但有一点不能忘了,后缀Tries的构造是需要时间和空间的,而且都是平方级。
直到1976年,Edward McCreigh发表了一篇论文,后缀树自此问世了。后缀Tries的困境被彻底打破。
然而,McCreigh最初的构造算法是有缺陷的,原则上它要按逆序构造,也就是说字符要从末端开始插入。如此一来,便不能作为在线算法,它变得更加难于应用与实际问题,如数据压缩。
20年后, 来自赫尔辛基理工大学的Esko Ukkonen把原算法作了一些改动,把它变成了从左往右。
后缀树的构造
很多介绍后缀树的文章,都把重点放在后缀树的构造过程上。可见,后缀树的构建过程是该算法的关键。
历史
1973年,Weiner发明了最初的O(n)算法,Knuth称之为1973算法。Weiner提出的方法采用自右向左处理,从最短的后缀开始,依长度递增顺序不断把后缀添加到树中。
1976年,McCreigh提出了空间效率更高的算法。McCreight提出的方法依长度递减顺序把后缀逐个添加到树中。
20年后,Esko Ukkonen对其改进,提出了更简单的在线算法。
Ukkonen构造算法
待续
应用
后缀树天生就是用来解决长串搜索问题的,而且效率很高。因此,只要涉及在某个固定长数据序列中多次查找子序列的问题,都可以应用后缀树。
缺点
后缀树的构造可以用Ukkonen算法在线性时间内完成,但是不仅构造算法实现相当复杂,而且后缀树存在着致命弱点:空间开销大且对大字母表时间效率不理想。















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









